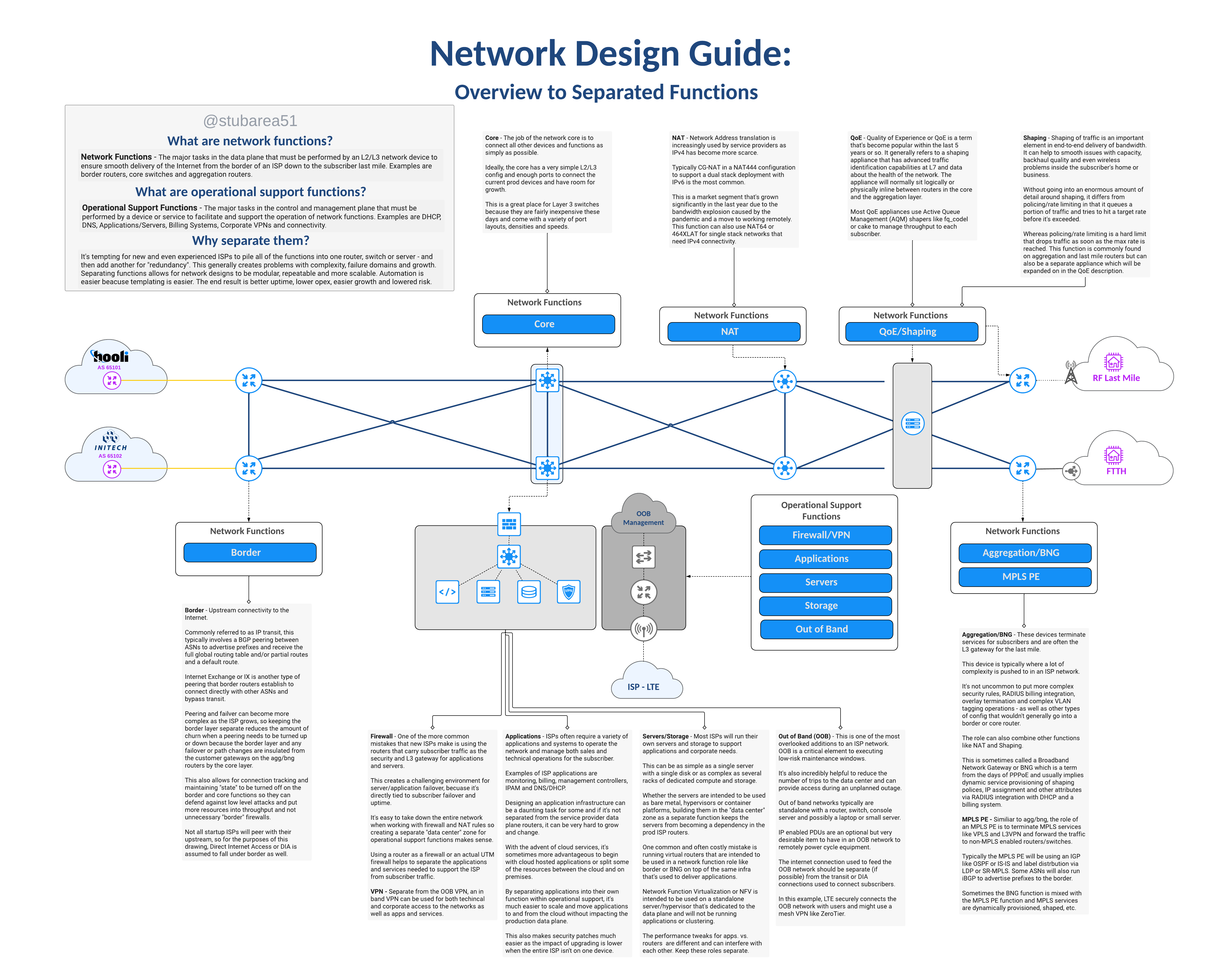
A reference guide for new & existing ISPs that need to understand network functions and separation.
“How do I add redundancy?” “How do I scale?” “How do I reduce downtime and operational costs?”
These are questions that I get asked practically every day as a consulting network architect that designs and builds ISPs.
In most cases the answer is the same whether the ISP uses fixed wireless broadband, copper or fiber to deliver the last mile – separation of network functions.
This illustrated guide is intended to define the topic and create visual context for each function using a network drawing. It’s the first in a new series on this subject.
A new series of content
This topic is deep and there is a lot to unpack so this will be the first segment in a series of blog posts and videos covering function separation.
Large ISPs typically already embrace the philosophy of separating network functions, so the focus of this series will be to help new or growing regional ISPs understand the design intent and the challenges/costs of running networks that don’t separate network functions.
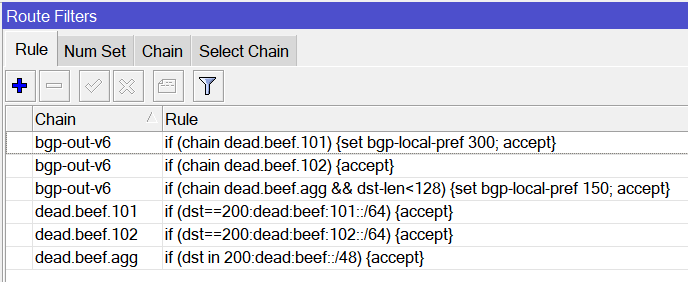
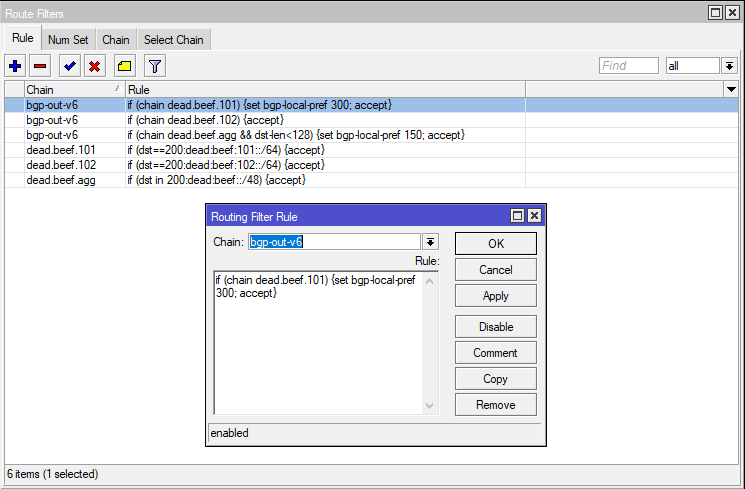
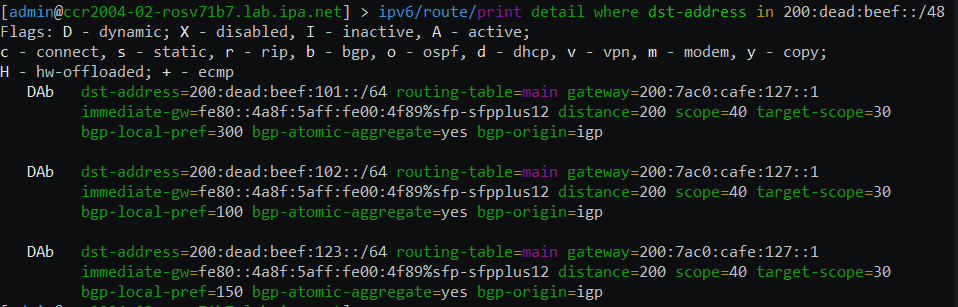
Routing filters have been a hot topic lately in the world of RouterOSv7. The first implementation of routing filters in ROSv7 was difficult to work with and documented in the two articles below:
MikroTik then made some changes and opened up discussion to get feedback. I did a lot of work and testing using ROS 7.1beta7 which never made it to public release and was close to publishing the results when 7.1rc1 came out so this post will use that version.
Coding vs. Network CLI – The single biggest resistance to the new style of filtering is the string format is hard to work with. It requires knowledge of the match and action statements as well as how to write an expression to correctly parse them. Network engineers are not software engineers and route filtering (much like firewalling) has the capacity to be complex and require many lines of config – which means the format should align with v6 route filters and/or firewall rules.
Tab complete – The lack of tab complete is a big gap. Network engineers, admins and technicians expect to be able to tab complete when creating a config. This is rumored to be in the works and hopefully it will make it into later release candidates.
Using context sensitive help with “?” – There are a couple issues with context sensitive help in ROS 7.1rc1. The first issue is using the F1 key for help in any part of ROSv7 (not just filtering) instead of the ‘?’. This should at least be an option that can be set.
The second issue is the lack of context sensitive help for the routing filters – if an engineer is unsure of the syntax, it’s currently not possible to get help from the command line.
This has been a fundamental part of CLI based network operating systems for over 30 years. It needs to be added back.
Conclusions
One thing is clear, everyone I discussed it with on Facebook, Reddit, MikroTik Forums and with clients and engineers on my team did not like the new format.
It’s worth noting that MikroTik equipment is often used in remote locations where it isn’t practical to pull up the help docs and engineers in the field rely on the ability to use tab-complete and context sensitive help to finish configuration tasks. This is a critical feature for a network operating system to have.
To MikroTik – please consider implementing the filters so that at a minimum, the features in ROSv6 (like tab-complete, context sensitive help and a non-coding syntax) are maintained while allowing for new functionality.
Examples of filtering in other well-known operating systems
Here are some examples of the same filtering rules in different network operating systems for comparison. All of them support tab-complete and context sensitive help.
Free Range Routing is probably one of my favorites because it’s open and is being actively developed. JunOS is very popular from a filtering standpoint because the OS is easy to work with programatically.
Cisco is included because they are pervasive but isn’t at the top of my list because the syntax isn’t anything special and IOS-XR equipment tends to be incredibly expensive even though bugs are still commonplace – so it’s not a great value.
### Cisco IOS-XR x.x ###
prefix-set dead.beef.101
200:dead:beef:101::/64
end-set
!
prefix-set dead.beef.102
200:dead:beef:102::/64
end-set
!
prefix-set dead.beef.agg
200:dead:beef::/48 le 128
end-set
!
route-policy bgp-out-v6
if destination in dead.beef.101 then
set local-preference 300
pass
elseif destination in dead.beef.102 then
pass
elseif destination in dead.beef.agg then
set local-preference 150
pass
endif
end-policy