
In another life, not too long ago, I spent a number of years in civilian and military law enforcement. When going through just about any kind of tactical training, one of the recurring themes they hammer into you is “situational awareness or SA.”
Wikipedia defines SA as:
Situational awareness or situation awareness (SA) is the perception of environmental elements with respect to time or space, the comprehension of their meaning, and the projection of their status after some variable has changed, such as time, or some other variable, such as a predetermined event. It is also a field of study concerned with understanding of the environment critical to decision-makers in complex, dynamic areas from aviation, air traffic control, ship navigation, power plant operations, military command and control, and emergency services such as fire fighting and policing; to more ordinary but nevertheless complex tasks such as driving an automobile or riding a bicycle.
Defining the need for SA in network engineering
It’s interesting to notice that critical infrastructure such as power plants and air traffic control are listed as disciplines that train in SA, however, I’ve never seen it taught in network engineering. In today’s world, the Internet has become as important as any other critical infrastructure and probably more in some ways. Network engineering shares many of the high pressure components as other critical infrastructure. Engineers are often forced to make decisions quickly under stress that can have a significant financial impact and may have regional, national or even global ramifications. Engineers that work supporting military, healthcare, public safety and telecom sectors have the additional responsibility of avoiding downtime that can risk the safety of life and property. When not under the immediate pressure of a high risk change or outage, network engineers are frequently given projects with timelines that are too short to plan properly and when the time to implement comes, unforeseen issues tend to pop up much more frequently. Understanding SA is key to ensuring that engineers focus on the right tasks at the right time and know when to ask for help, when to coordinate and even when to step back and stop working.
Why don’t we teach SA in networking?
This is largely, I suspect, one of the things network engineers are expected to acquire with experience and so it isn’t formally taught or is passed down from engineer to engineer. SA is something that is best taught as a combination of practical experience and both formal and informal training. The Cisco CCIE Route/Switch lab exam is probably one of the few examples of formal training that forces a network engineer to be aware of task priority as well as assessing the changing state of the network and responding appropriately. That said, after a brief google search, it does appear to be taught in cyber security as an adapted form of SA meant for military personnel. Much of the training tends to focus on how to avoid losing situational awareness by following certain methodologies and what to do if you realize you have lost SA.
An example of the loss of SA in networking.

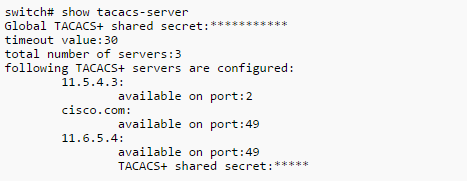
This is a scenario that just about every engineer can relate to…You’re working on a network cut and one of the tasks that you have to perform (which should be relatively quick) turns out to be quite difficult – because of a mis-configuration, bug, missing info, etc. A common example is network management config like SNMP, netflow, TACACS, etc. Let’s say you’re bringing a new L3 switch core online that involves physical link migration as well as new VLANs and OSPF/BGP. You have a 4 hour maintenance window and you start to work on an issue where your centralized TACACS server isn’t responding to the new switch – maybe it’s a security policy in the server or maybe you have the key wrong. You start to troubleshoot the issue with the expectation that you’ll have it solved in 10 or 15 minutes.
45 minutes later, you’re ALMOST there and so you put your head down and charge on through since you’re only 10 minutes away from solving the issue…right? Another 45 minutes go by and you’re at a complete loss as to why TACACS won’t work properly on this switch. Let’s pause for a moment and assess the status of the cut – we are now 1 hour and 30 minutes into the window and we have used almost half of the time on a single task. We still have to move physical links, ensure smooth L2 STP convergence when we add a new trunk and VLANs and L3 routing has to be brought online and tested with BGP and OSPF.
At this point, you’ve probably lost situational awareness because almost half of the time was spent on one task that is probably not critical to bringing a new L3 switch core online. This isn’t to say that ensuring the proper AAA isn’t important, but it’s a task that could be done in a follow up window the next night – or you might even extend your current maintenance window after the critical physical and route/switch pieces have been done. The point is, that in most environments, network management tasks aren’t as critical to configure as L2/L3 forwarding if you have to make a choice between the two based on time available.
There are probably thousands of scenarios like this one we could go through but the critical take away here is to understand exactly which items have to function in order to accomplish the overall goal. A secondary component to that is to understand where you can make compromises and still come away with a win – maybe in the example above, static routes are an acceptable temporary solution if you run into issues with dynamic routing.
SA concepts for network engineers
I’ve adapted some of the concepts from the US Coast Guard’s manual on SA to illustrate the important points and relevance for network engineers. The full text can be found here
Clues to the loss of SA
In reviewing a network outage or failed cut, you will often find one or more of these clues in hindsight as you try to figure out what went wrong.
- Confusion – If something isn’t quite right with the network as you’re working on it, but you can’t put your finger on it, trust your gut and share it with the engineering team or any other relevant parties. Likewise if you sense the team is generally confused about a critical task, don’t be afraid to take a step back and try to get clarification from the team. At worst you may have a short delay, but at best, you may discover some major gaps or other issues that need to be dealt with before moving forward. Confusion is the sworn enemy of communication.
- Deviation from the plan – we don’t always have the time to plan our network changes and it isn’t realistic to think that 100% of changes will be planned, but if you’re doing it right, most of the config that is put into the network should be planned and tested. When executing a network change, if you have to deviate from the planned config more than just a few lines, it might be worth putting the change on hold to assess whether or not your on-the-fly changes will upset things in other areas. Trying to think through all the dependencies of adding BGP route reflection in an entire data center at 3AM may not be the best choice to make.
- Unresolved Discrepancies – If the SYSLOG is churning through OSPF neighbor flapping entries, then maybe it isn’t the best time to introduce more OSPF changes. Understanding the state of the network before you make changes is key to avoiding breaking things even more. This seems like a very common sense approach, but all too often, we as engineers tend ignore the danger signs of an unstable network and try to fight our way through to “just get things working.” It’s far better to identify and resolve known issues before introducing new config that could be destabilizing – even if that means missing a target date in a project.
- Ambiguity – If there isn’t a great deal of clarity around the changes you plan to introduce into the network, then you’re setting yourself up for failure. If an engineer comes to me and says he wants “throw VLANs 100 through 110″ onto all the switches that need it”, I would probably challenge him to come back with the configuration required to do exactly that and in the process, we will probably have a much better understanding of the Layer 2 impact versus (con)figuring it out as we go.
- Fixation/Preoccupation – If we think back to the example earlier about spending an hour and a half on troubleshooting TACACS, that is a great example of fixation on one task. Unfortunately just about all of us have been there because it is so easy to lose sight of the bigger picture when you’re trying to get something to work. This is where a team of engineers can be very helpful. You might suggest to a member of the team who is head down and wrestling with a non-critical problem to refocus on the critical pieces and then the team can come back and work on the tasks together. If you’re working solo, then you have to be especially vigilant and self-policing when it comes to avoiding fixation/preoccupation.
Maintaining Awareness

- Communication – clear and effective communication, both verbal and written, is key to avoiding major issues. You should always strive to provide the right information in a timely manner to avoid ambiguity and confusion. It’s important to communicate things like a planned course of action as well as tasks that you are specifically charged with – even if it’s just to verify the information you have is accurate.
- Identify Problems – If you see a potential issue, don’t wait to bring it up. Sometimes, we as engineers are afraid to raise concerns for fear of looking foolish or uninformed, but harboring a concern and then voicing it once you’re in an outage situation doesn’t help anybody and certainly will make you feel foolish for not bringing it up when you had the chance.
- Continually Assess the Situation – Continually checking on the state of the network and the impact changes are having will keep you alert for any issues that may pop up. Many of the problems we have to go back and fix as network engineers are a direct result of incomplete validation after a change has been made. Another thought to consider here is that if you are a member of a team, you can delegate this task or ask for assistance so the burden isn’t entirely on you.
- Clarify expectations – If expectations and goals are not clearly defined, they can be hard to achieve. If it’s not understood that a network change is expected to cause an outage, you may have some unhappy campers on your hands because you didn’t clearly set the expectation.
The lone gunman effect on SA

There is no faster way to lose SA than to try and go it alone in the midst of a team environment…
One of the hardest things to do sometimes when functioning as a member of a team is to delegate tasks and responsibility. Especially if everyone on the team is not at the same technical level. That said, it’s typically not the best idea to be the lone gunman if you have resources available to utilize. Simple tasks like checking monitoring systems and logs can be assigned to team members with less experience and doing peer review of config can be helpful with more experienced engineers. To take this concept even further, if you have support from the network vendor available for peer review or even a dedicated engineer to sit in on a change window, always take advantage of that resource. Too often, we as engineers become consumed with being the go-to guy or gal and coming up with all the answers. What we should be doing is putting the success of the project first and using any resources available to ensure a successful network change or implementation.
Don’t be afraid to pull the emergency brake
If you find yourself in the middle of a bad situation or sense that you’re about to be in the middle of a major network outage, then STOP! One of the most important skills an engineer can possess is the ability to understand when to call it quits – at least for a brief period – until you can come back with a better plan. We’ve all had to make that gut wrenching call where we decide whether to plow forward or pull back and sometimes there isn’t much of a choice. Whenever you have the option, however, don’t hesitate to take it. The stakeholders will usually overlook schedule delays in the interest of preserving up-time. Also, demonstrating an understanding and respect for the business side of the house that depends on a functional network will probably buy you some goodwill with the business unit and increase the level of trust in your technical judgement.
Closing thoughts
Situational awareness for network engineers is mindset that we have to practice daily, but the overall learning curve is a long term process. We don’t always get it 100% perfect because we are human and subject to a number of external influences that compromise objectivity and work performance. The most important take away is to recognize, as other disciplines have, that there is value in understanding SA and the potential issues that come with losing SA. The next time you have a network cut, implementation or outage, take a minute to think through the SA concepts and how they relate to your specific corner of IP networking.