Overview
This would probably be a relevant topic on any given day in the world of IT, but given the current global pandemic due to COVID-19 (aka coronavirus), it’s become especially important.
IT departments are scrambling to figure out how to react with capacity to connect entire companies remotely for extended periods of time.
With a traditional vendor solution that centers around a router or firewall that’s racked in a data center somewhere, this can be difficult to solve for a few reasons.
Challenges:
- Hardware capacity – most firewalls or routers have a fixed capacity for VPN sessions that must be deployed into a cluster to scale.
- Software licensing – taking a company of thousands and suddenly extending licensing to account for the entire company is a financial hurdle for most companies.
- Time to deploy – assuming both hardware and software licensing challenges can be dealt with in a timely manner, it may take weeks or months to deploy the additional capacity.
Luckily, IT is much more focused on software and cloud solutions these days then putting out boxes for everything.
Open source and cloud solutions when used together can provide an incredible amount of scale and performance without a long ramp up period.
We’ll be looking at the solution design below in the next few sections to explore solving the problem of remote worker VPN scale in a cost effective way.
Solution design
This is an overview of a design we’ve put into production to facilitate enterprise level VPN connectivity without traditional drawbacks like scale limit, hairpinning traffic and expensive hardware and software licensing.
1000+ users – All of the solutions used in this design are open source. The ZeroTier web controller is free for deployments up to 100 endpoints and requires very minimal investment to scale to thousands of endpoints.
10,000+ users – Even 10s of thousands of endpoints would still be a very moderate cost that would mainly be centered around cloud compute fees or physical DC/Campus hypervisor capacity.
It would likely still be less than 10% of the cost of a comparable VPN + hardware box solution.
All of these components can be assembled and tested inside of a day for a handful of FW endpoints and once security policies have been reviewed and applied, full production can easily be achieved not long after that.
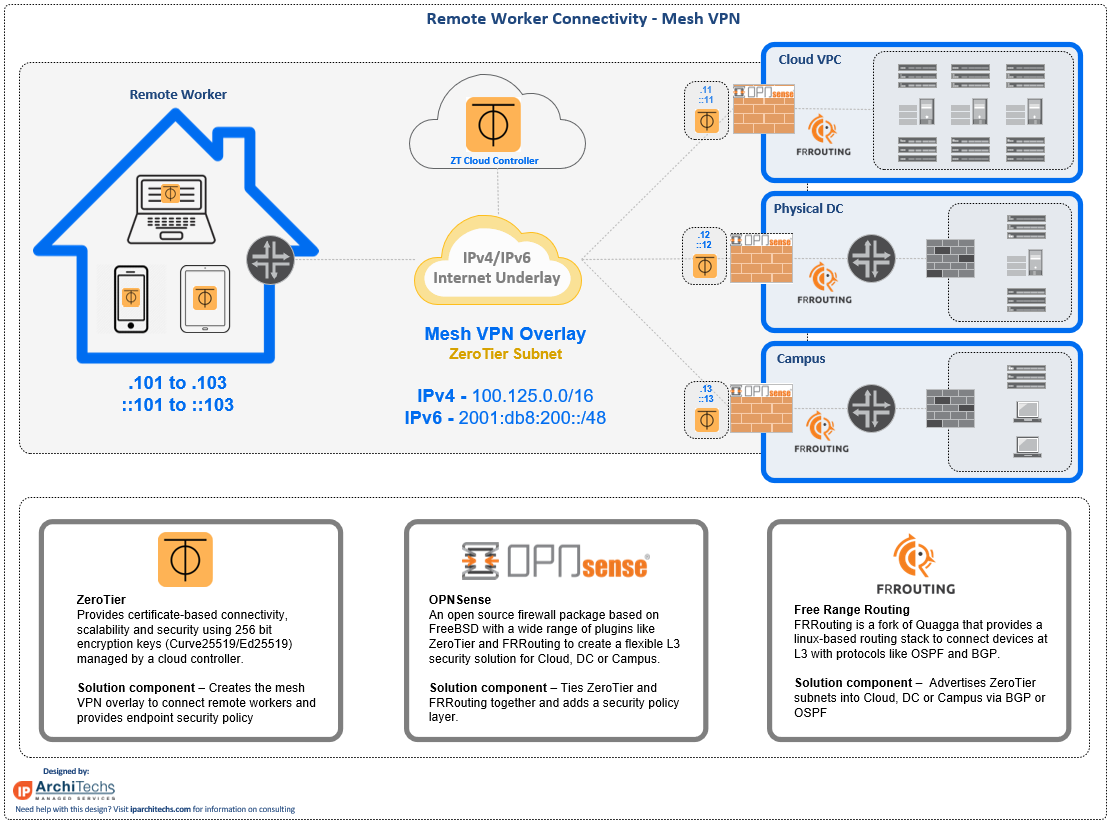
Using ZeroTier for Mesh VPN connectivity.

If you’re unfamiliar with Mesh VPNs, you’re probably not alone.
Mesh VPNs are a relatively recent concept in overlay networking that allow for connectivity directly between any two points in the mesh without hairpinning through central points like a traditional VPN concentrator.
If you want some background on different Mesh VPN solutions, check out this podcast I was recently a part of over at networkcollective.com
What Mesh VPN solutions are available?
There are a few and this isn’t an exhaustive list, but the three I hear the most chatter about are ZeroTier, Nebula and TailScale
Any of these could be used to deploy this design, but I focused on ZeroTier because it’s the most flexible to combine with traditional networking in a data center or campus using dynamic routing protocols.
ZeroTier overview
ZeroTier first got on my radar when Ethan Banks over at the Packet Pushers did a priority queue show with the founder Adam Ierymenko on the Mesh VPN solution he developed.
ZeroTier’s mission is “Global Area Networking” using a unique mix of a centralized controller and certificate based authentication of endpoints.
it’s super easy to deploy as well and can be functional between two computers, phones, etc in a matter of minutes.

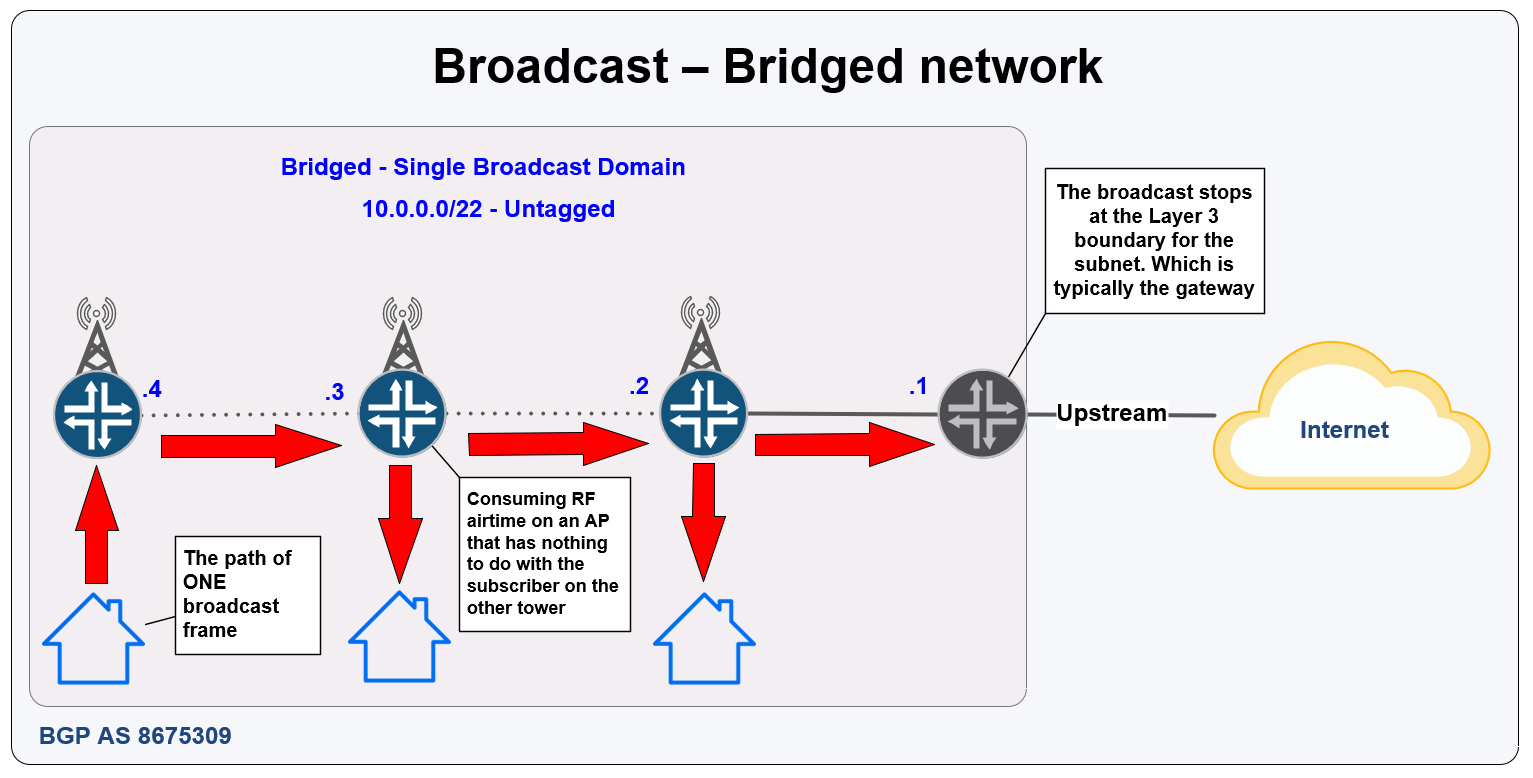
Managing L2 scale
Normally, a large /16 subnet stretched across the globe would have networkers like me cringing as it’s a solution that’s often frowned upon and with good reason.
However, ZeroTier solves this in a very interesting way by managing all of the components that normally blow up L2 overlays like broadcast and multicast.
ARP is a good example – it is converted into unicast and sent to the appropriate destination as described in ZTs manual below:

Broadcast is also carried as multicast to reduce overhead. Hosts can choose to participate or block multicast based on what the host is used for.
This is how ZT scales to very large numbers in the same subnet.
And if that isn’t good enough, they also run a public network called ‘earth’ that’s one large /7, just to make sure that tens of thousands of people on one subnet won’t blow things up.

Operating system support
One of the great benefits of using ZeroTier is that it runs on practically everything including Windows, Linux, iPhone, iPad and Mac.
Just download and install the appropriate client then go to my.zerotier.com to sign up for an account and create an overlay network.
ZT Controller – managing endpoints
Once you’ve created an overlay network, ZeroTier makes it incredibly easy to manage and authorize endpoints.
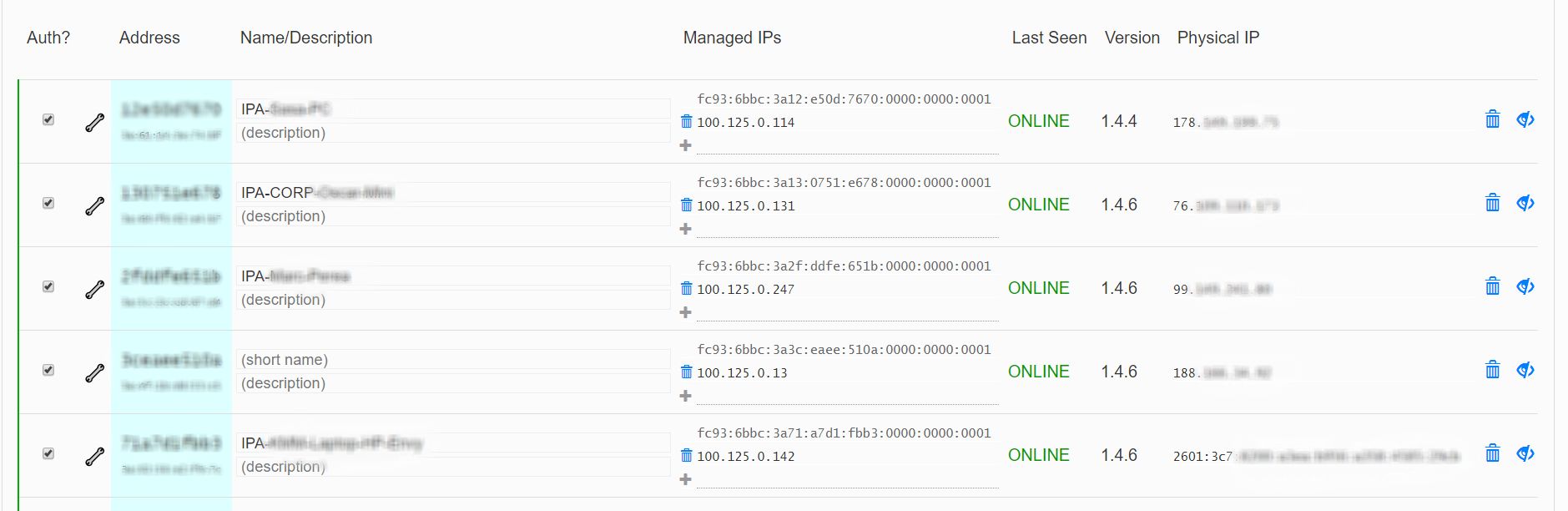
Below is a screenshot of endpoints in production. Notice the last entry has IPv6 available for internet access, so ZeroTier will use that to transport the IPv4 overlay network – which is a huge benefit…the underlay IP version doesn’t matter.
This is not true in almost every other enterprise VPN solution i’ve come across – IPv4 must encapsulate in IPv4 and IPv6 must Encapsulate in IPv6.
Injecting routes
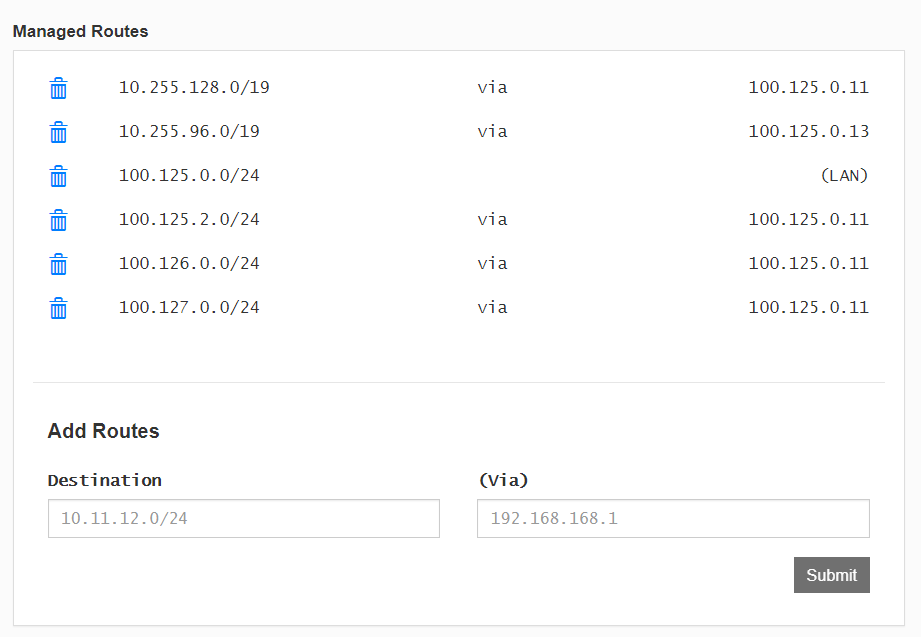
Routes are enabled to endpoints using a dynamic static route injection from the controller.
These routes show up on the host routing table to provide connectivity to endpoints within the network.
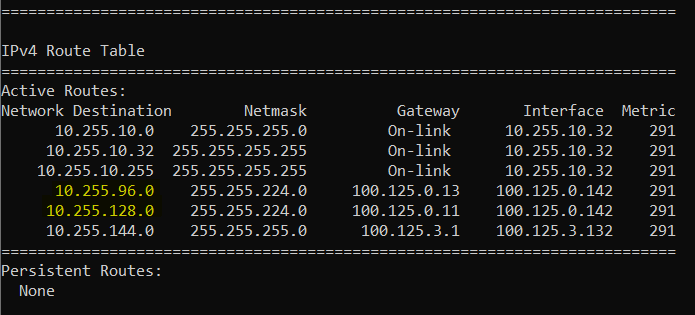
And this is what it looks like for the 10.255.x.x routes on an endpoint host to a 100.125.0.x gateway (which represents a cloud or physical DC in this network)
Security policy
ZeroTier has the ability to push flow rules to endpoints that can permit / deny or change the flow of traffic.
There are a number of ways to leverage this along with rules at the OPNSense firewall to create a security policy that is modular, effective and functional.
Example: one way to leverage flow policies is to allow RDP only on this particular ZT network by permitting TCP/3389 traffic. Combined with host authentication and firewall level permissions, access to RDP can be tightly controlled by using 3 layers of security policy.

Using OPNSense as a firewall
If you’ve never used it, OPNSense is a fantastic open source firewall package.
It can be deployed from an ISO into a VM or as a bootstrap install in the cloud (I’ve successfully used AWS and Digital Ocean)
Mesh VPN and Routing
One of the intial challenges when using Mesh VPNs was to interconnect with routers and provide security policy beyond just the controller.
OPNSense has a number of packages and plugins – what initially drew me to it was the support for ZeroTier out of the box.
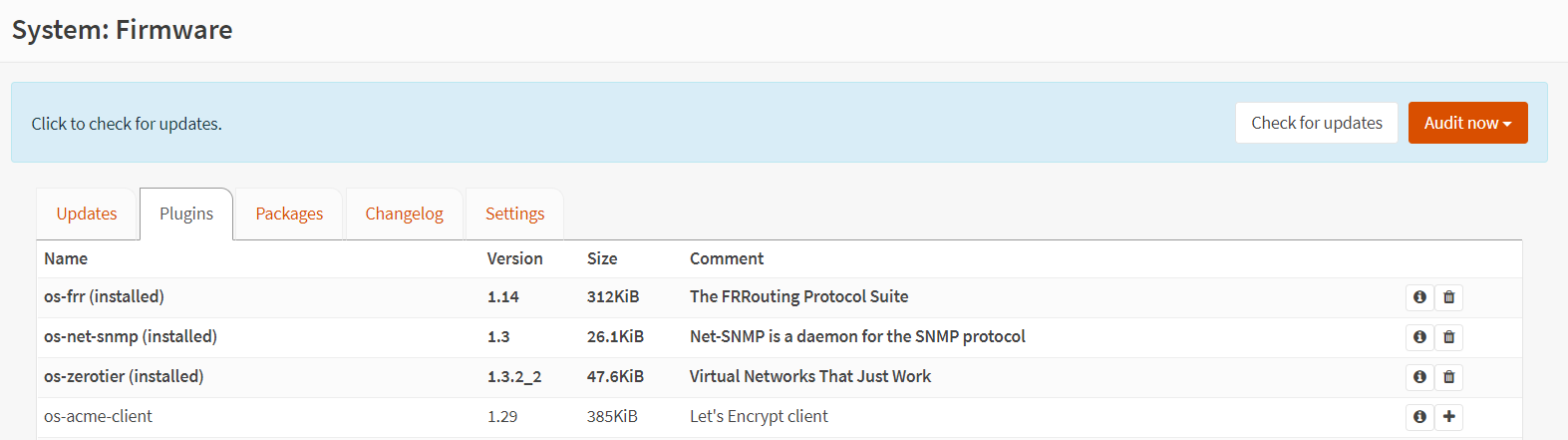
Installation was painless and the ZeroTier adapter was running and reachable within minutes.

Security rules
Here is a brief example of a security rule in OPNSense defining access coming from a ZeroTier remote worker subnet to a group of RDP Servers
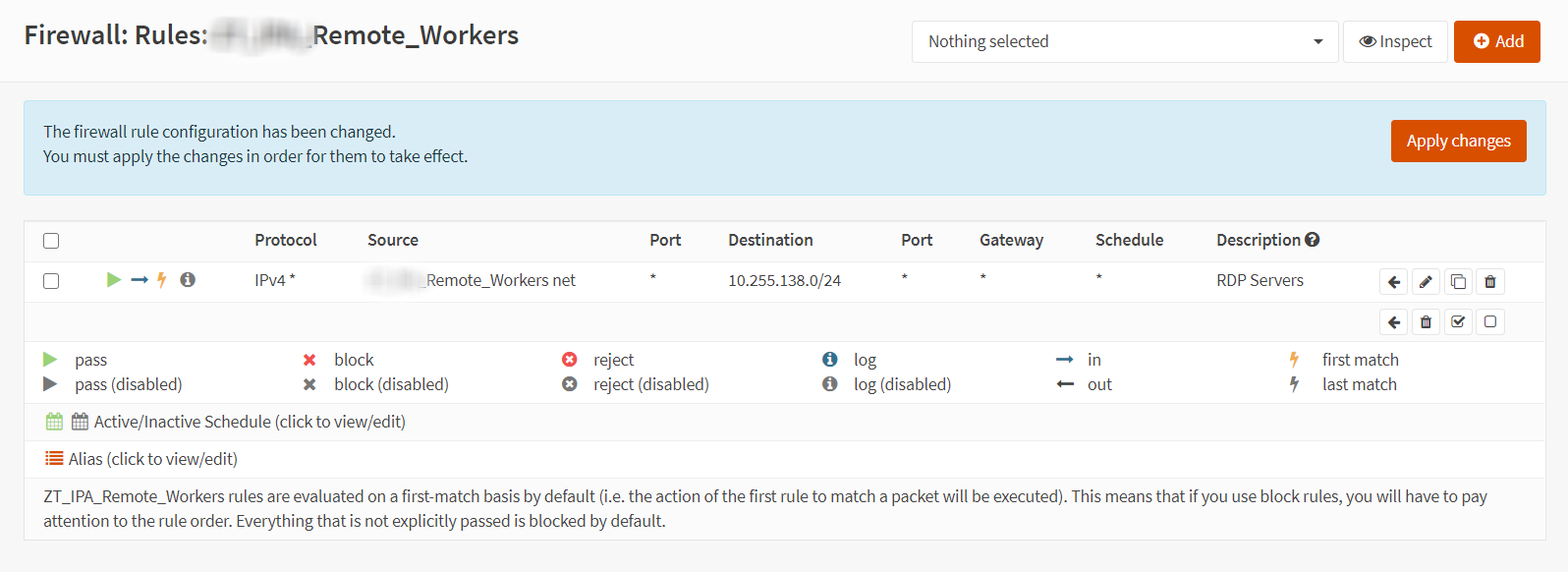
That’s pretty much all you need to get started with connecting remote workers into the firewall.
Should you decide to force Internet access through the firewall, a NAT policy can be setup and ZeroTier can inject (or remove) a default route to the host if so desired.
The last piece to the puzzle – dynamic routing – is covered in the next section.
FRRouting for dynamic routing
The final piece to glue together the Mesh VPN connectivity through the firewall is a way to dynamically advertise the VPN subnets into a router or another firewall.
FRRouting or Free Range Routing is an open source routing stack that was forked from Quagga a few years ago.
It’s a very solid and capable way to turn any linux box into a feature rich routing platform.
A quick look at the protocols supported shows a wealth of options

The plugin for OPNSense is installed in the same way as ZeroTier and is equally painless. Once intalled, a tab for routing shows up in the left hand menu.
OSPF
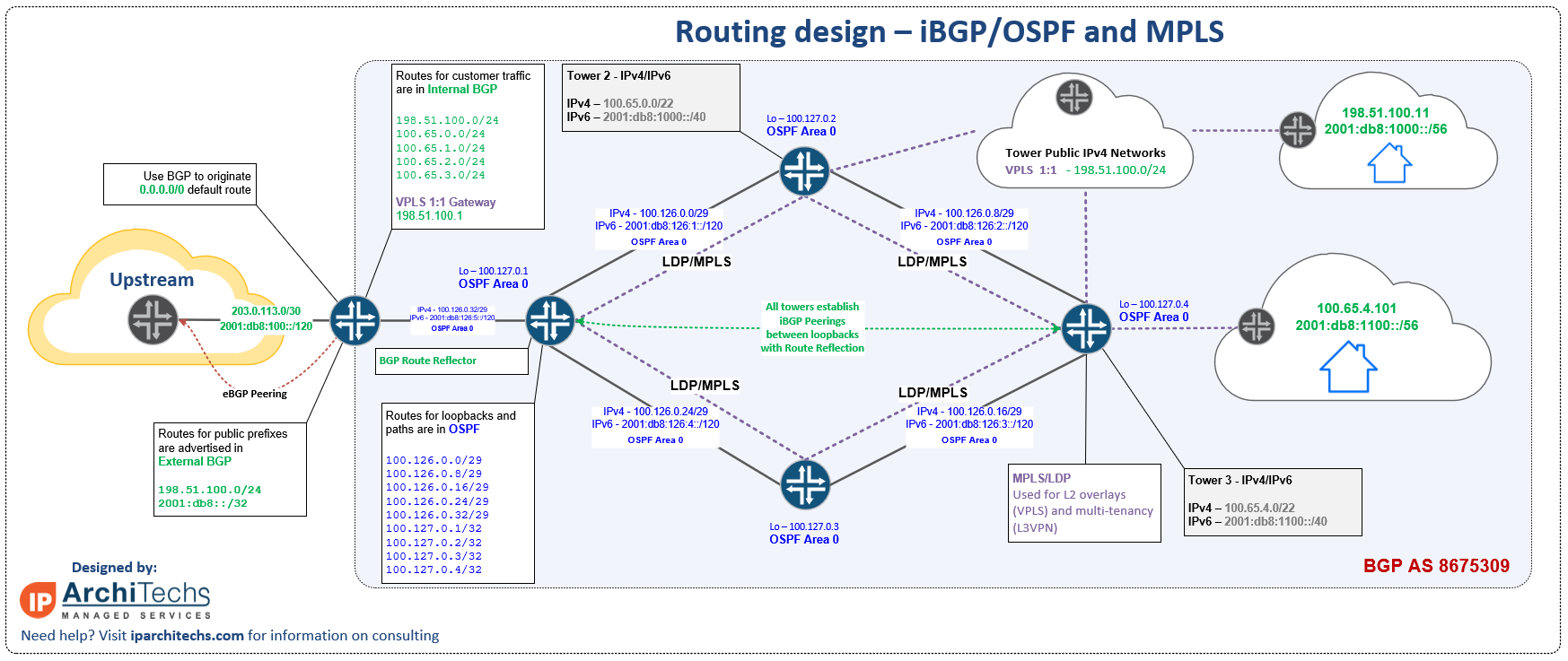
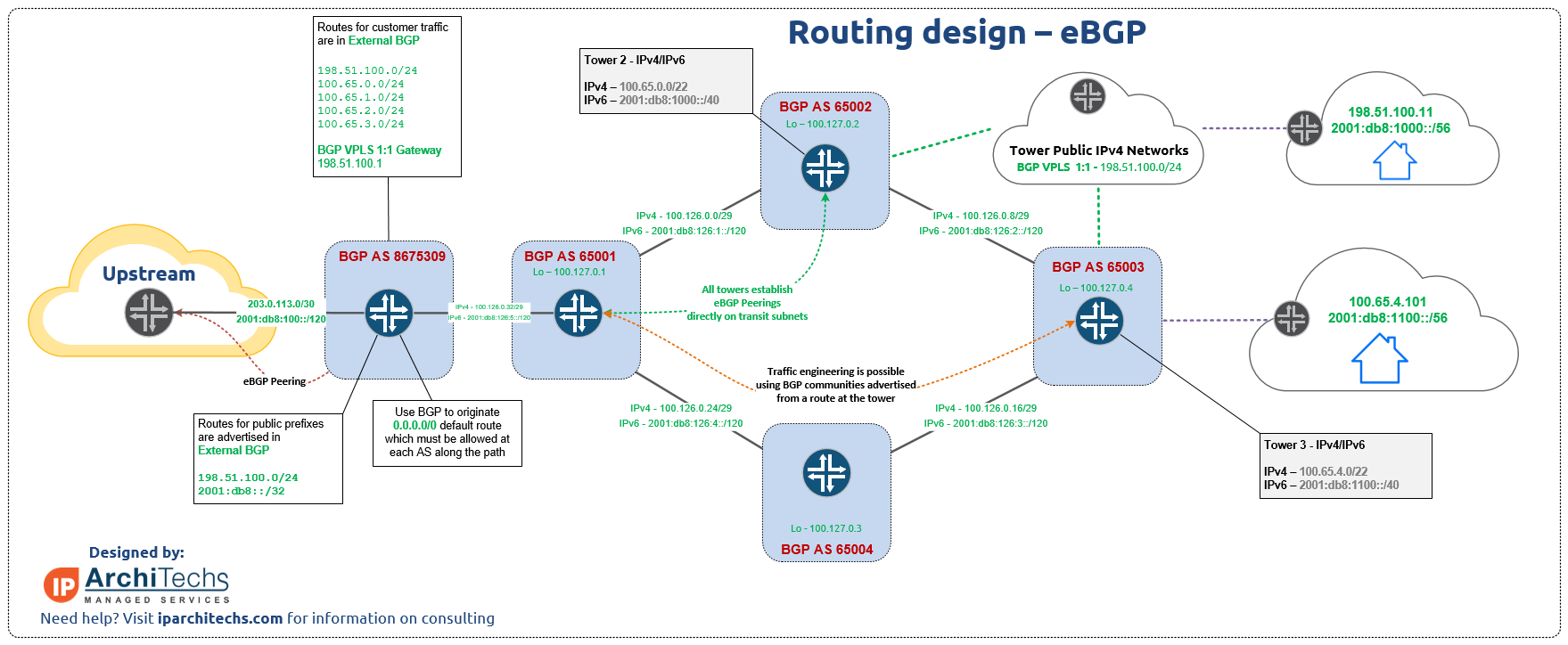
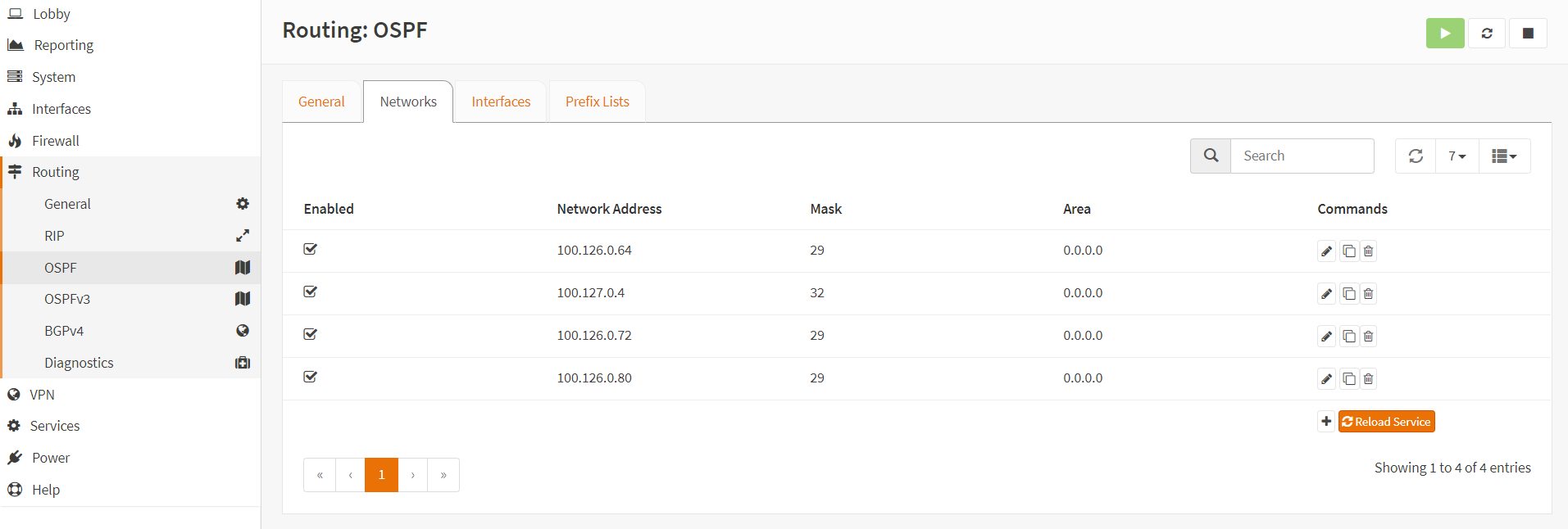
OSPF Configuration and creating neighbor adjacencies is very straightforward. In this network, OSPF is used to advertise loopbacks for iBGP to the DC core switch.
Here is an example from the OPNSense UI
BGP
BGP is also very easy to configure. In this example from the OPNSense UI, several ZT networks are advertised into the DC core route reflector via iBGP.
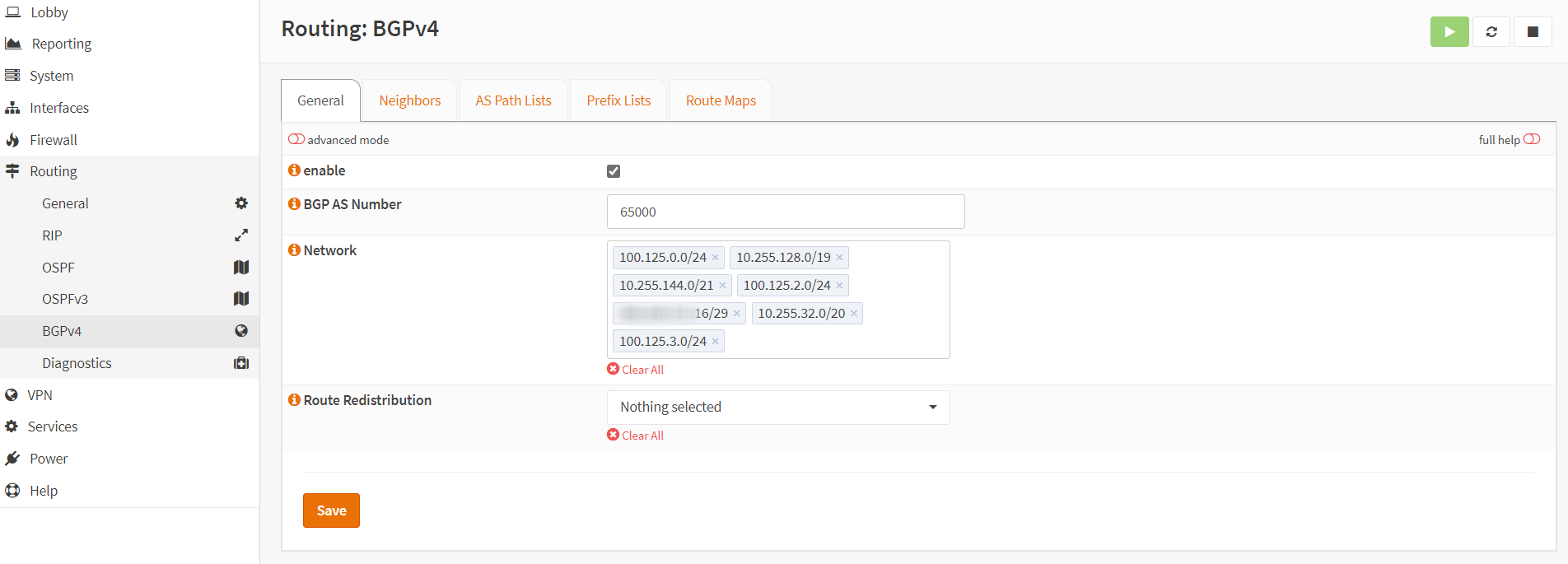
Active routes
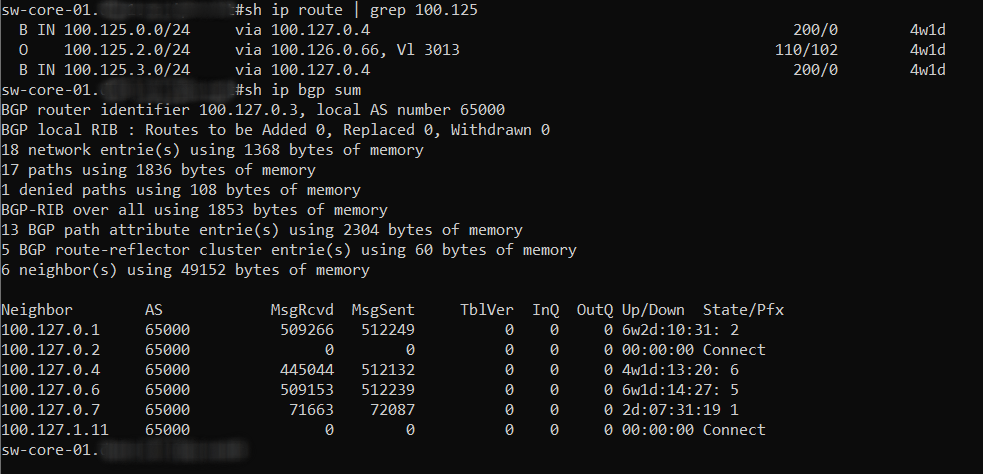
All routes for FRRouting, including Kernel routes can be viewed from the routing diagnostics tab in OPNSense.

Here is a view of the ZeroTier 100.125.x.x routes coming from the OPNSense FW and FRRouting into the DC Core route reflector.
Running configuration
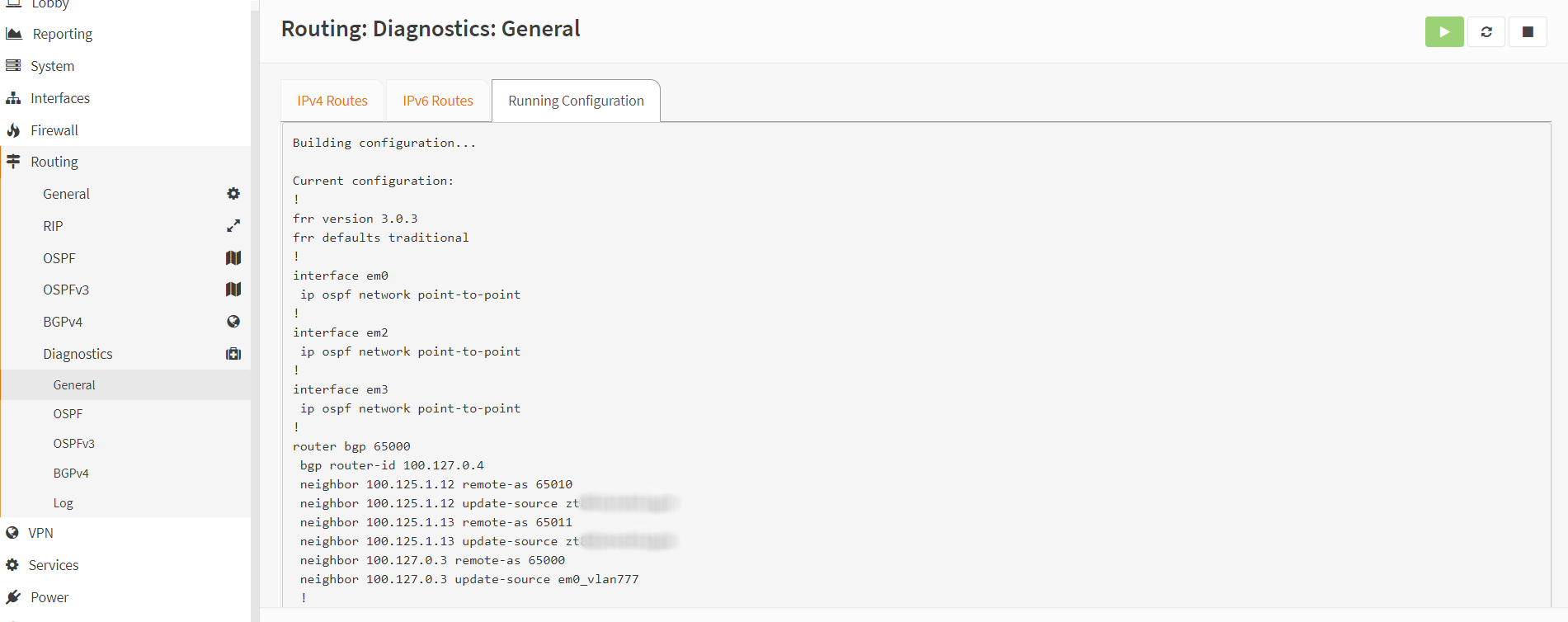
FRRouting has a running config that’s consistent with an industry standard CLI configuration.
The UI plugin will update the running config based on the web configuration, but features that aren’t supported in the UI can still be added by editing the running config.
Final thoughts
Ultimately, this is merely a functional starting point for a corporate VPN solution.
There are so many security and networking pieces that could be added depending on an organization’s compliance and regulatory requirements.
However, the advantage of using open source components is that anything can be added to a prod build with a little time and some testing.
The key is to get a lab build and tested.
Try building out a solution with Mesh VPNs, open source firewall and routing tools and see where it takes you!