Working with MikroTik and IP Infusion’s OcNOS to interop EVPN/VxLAN has been on my wish list for a long time. Both solutions are a great cost-effective alternative to mainstream vendors – both separately and together – for WISP/FISP/DC & Enterprise networks.
BGP EVPN and VxLAN
One of the more interesting trends to come out for the 2010s in network engineering was the rise of overlays in data center and enterprise networking. While carriers have been using MPLS and the various overlays available for that type of data plane since the early 2000s, enterprises and data centers tended to steer away from MPLS due to cost and complexity.
BGP EVPN – BGP Ethernet VPN or EVPN was originally designed for an MPLS data plane in RFC7432 and later modified to work with a VxLAN data plane in RFC8365.
It solves the following problems:
- Provides a control plane for VxLAN overlays
- Supports L2/L3 multitenancy via exchange of MAC addresses & IPv4/IPv6 routing inside of VRFs
- Multihoming at the Network Virtualization Edge (NVE)
- Multicast traffic in VxLAN overlays
VxLAN – VxLAN was developed in the early 2010s as an open-source alternative to Cisco’s OTV and released as RFC7348
Problems VxLAN solves:
- Scales beyond 4094 VLANs by using a 24-bit VxLAN Network Identifier or VNI (that can also be tied to a VLAN)
- Encapsulates ethernet frames inside of UDP
- Creates L2 domains for DC, Enterprise and even Service Provider use cases.
EVPN/VxLAN – Better together
VxLAN on its own was limited because it needed a control plane to dynamically create tunnels and manage MAC address learning. EVPN and VxLAN became popular because together, they allowed network operators to solve many of the same problems as MPLS with overlays but didn’t need every hop in the network to support a specific protocol as VxLAN works with standard IPv4/IPv6 headers so it can pass through routers and switches that don’t support VxLAN.
This created a migration opportunity for data centers and enterprises to leverage EVPN/VxLAN designs over time without a massive rip/replace of hardware.
Adding EVPN and VxLAN to RouterOS 7.
VxLAN

While IP Infusion has supported both of these in OcNOS for quite a while, pairing these features together in ROSv7 has been a long time in the making. VxLAN was added fairly early in RouterOS v7 beta in February 2020.

A newer addition to the VxLAN implementation in ROSv7 allows for the hardware offload of very simple network topologies in supported hardware. It has a number of caveats that make it unlikely to be used outside of a lab until more features are added but the potential is easy to see – low cost EVPN/VxLAN endpoints that can handle traffic at wirespeed in an ASIC.

BGP EVPN
BGP EVPN on the other hand was a more recent addition in ROSv7.20beta2
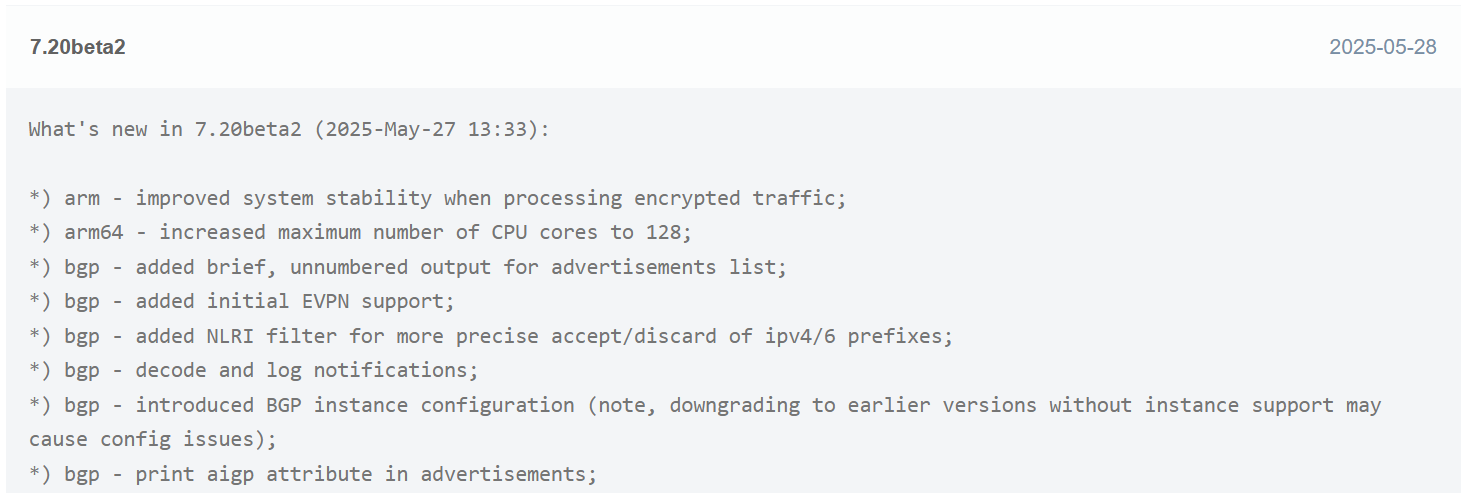
MikroTik added the EVPN address family to BGP peerings and the ability to set import/export route targets per VNI and BGP instance.

There are five EVPN route types defined:

MikroTik has currently implemented Type 3 IMET routes:

However, RouterOS can learn and display other EVPN route types like macip (though it may not be able to fully utilize all of them)

Given the amount of effort MikroTik has recently put into EVPN and VxLAN hw offload, it seems reasonable that we’ll see other EVPN route types and hardware capabilities enabled.
EVE-NG lab concept and overview
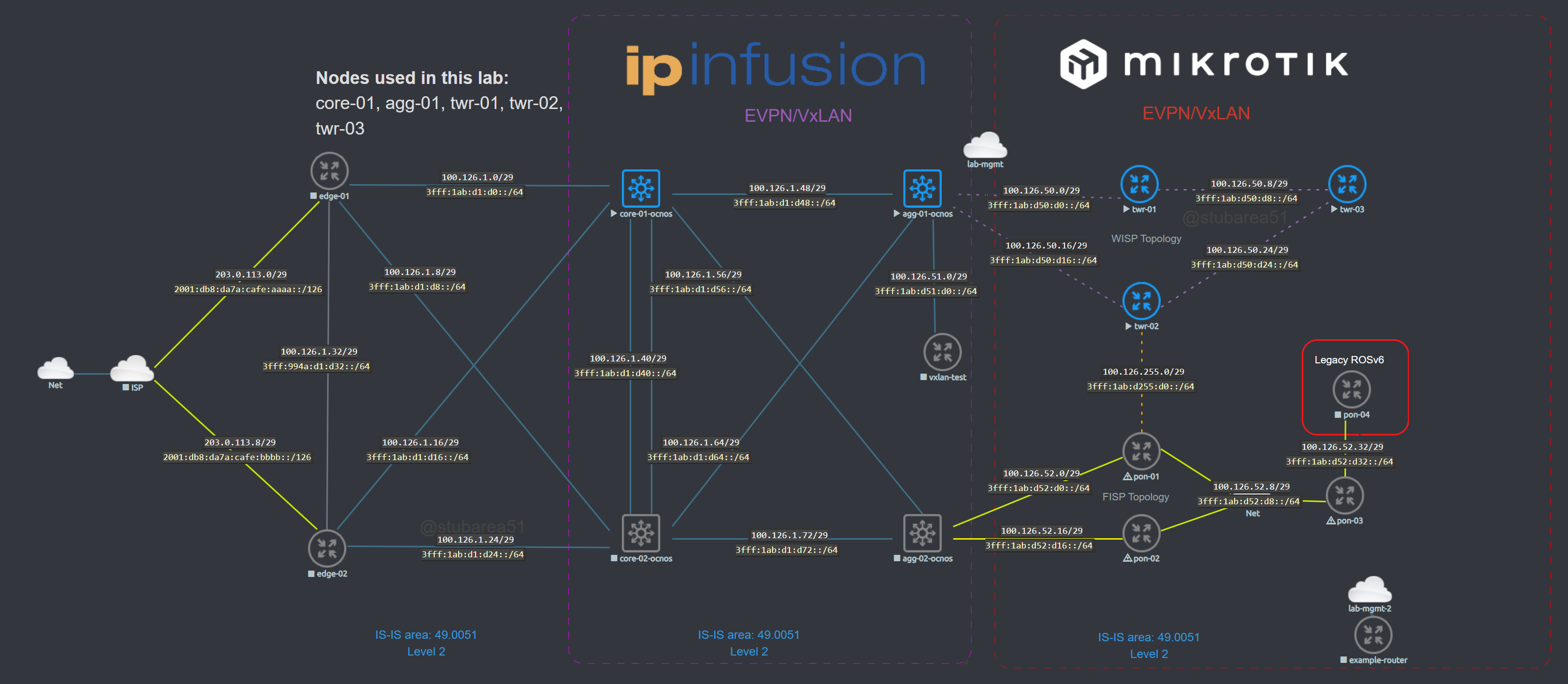
Topology
While EVPN/VxLAN is more often used in the data center or within enterprises, it’s sometimes used in service providers as well. Though it’s more common to see EVPN with an MPLS data plane in the ISP world.
The lab topology is based on a WISP/FISP design and is one i’ve been using for a while to test a number of different features, designs and operating systems.
Nodes used
For this lab, we’ll be using the core-01, agg-01 and twr-01, 02 and 03 nodes (blue nodes are powered on).
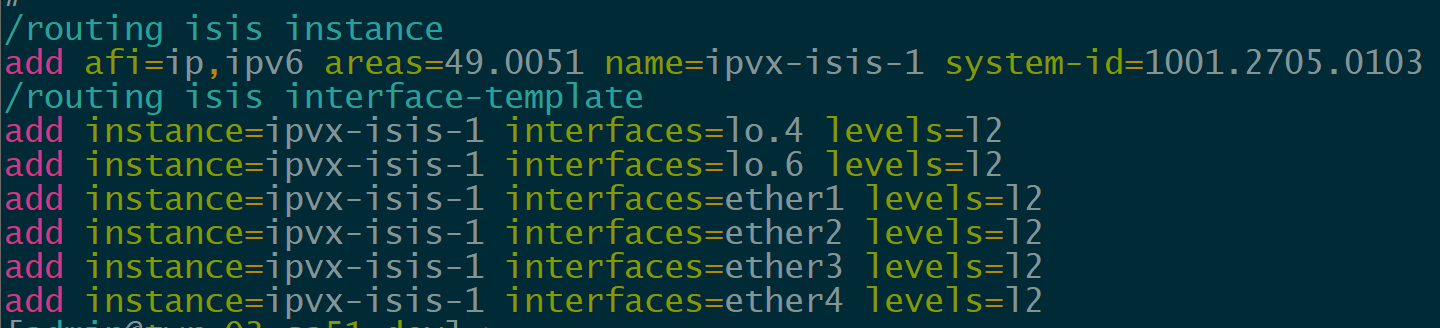
IS-IS Underlay
In order to provide reachability for iBGP, we are using IS-IS as the IGP for several reasons.
- Highly scalable and stable
- IPv4/IPv6 using the same instance
- Does not have the same area design constraints as OSPF
IP Infusion OcNOS has supported IS-IS for quite a while but it’s a newer addition to MikroTik with support added in ROSv7.13.
If you want to learn more about using IS-IS in RouterOS, I presented an overview of the protocol at the MikroTik Professionals Conference in 2024.
IPv4 and IPv6
Most of my labs are dual-stack or single stack IPv6 unless the feature or protocol i’m testing is IPv4 only.
IPv6 transition continues to increase and it’s important to test with the newest version of the Internet protocol whenever possible.
This lab utilizes RFC9637 IPv6 space because it allows us to model a variety of network types from a single ISP to a mock-up of the entire IPv6 Internet if desired.
3fff::/20OcNOS as a BGP EVPN route reflector
Since MikroTik has one EVPN route type working and only supports ETREE leaf type, I ended up using OcNOS SP as a BGP route reflector for IPv4, IPv6 and EVPN AFIs.
As EVPN support improves, i’ll update the testing to include using VTEPs between OcNOS and RouterOS.
Lab Validation
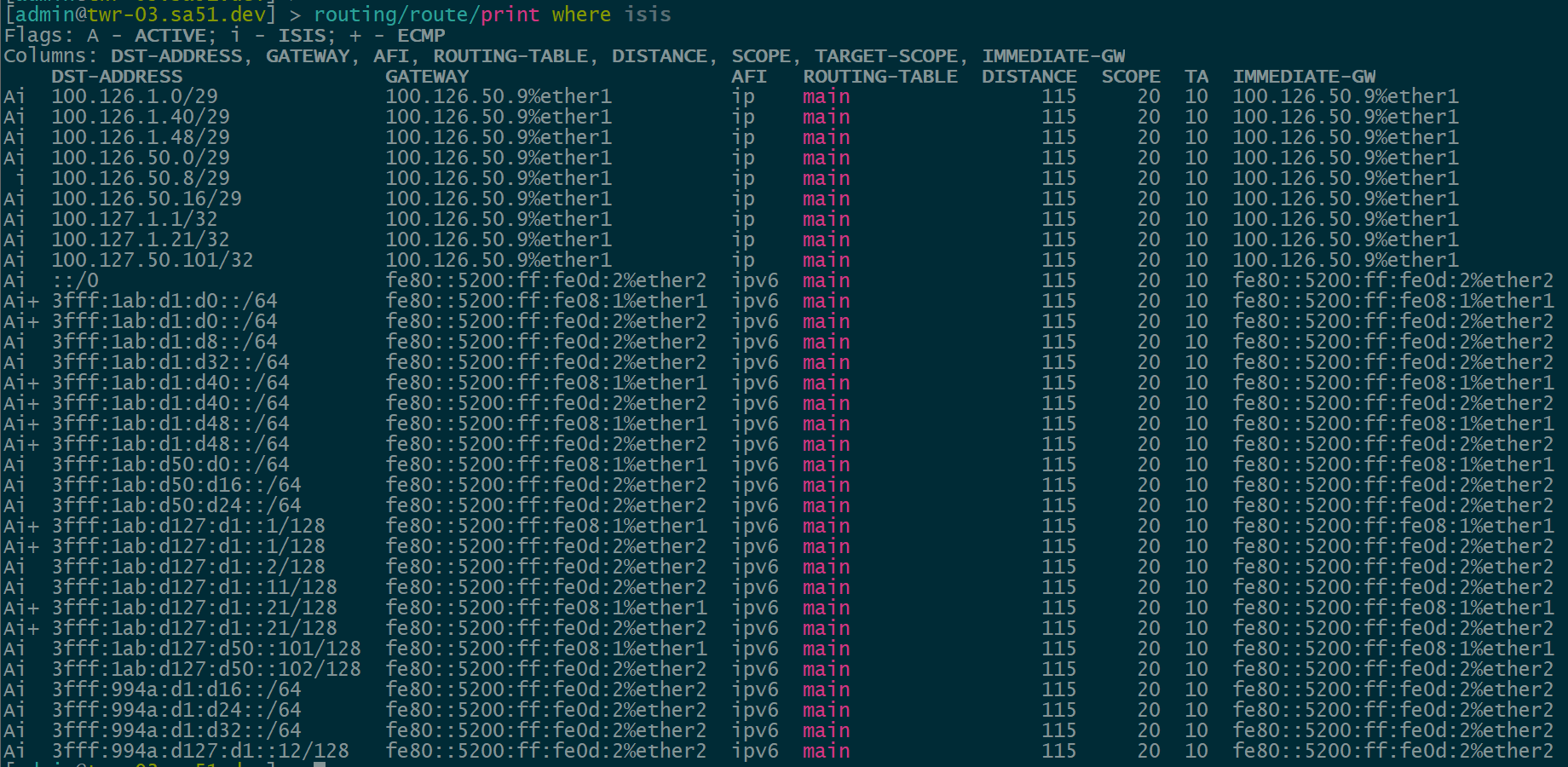
IS-IS underlay
Our first step is to validate IPv4 and IPv6 IS-IS routes between the core and the towers. All of the loopback and ptp routes between the core and towers show up and are reachable.
core-01
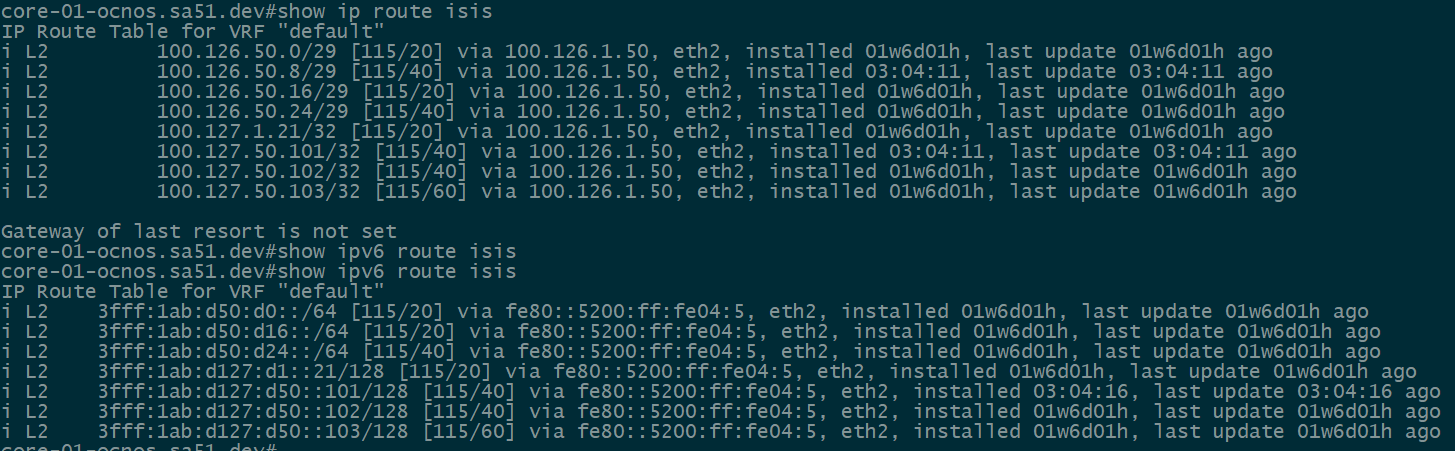
twr-03
BGP Peerings
Next, we want to ensure that BGP peerings are up between the towers and the RR. We can see established peerings on both IPv4 and IPv6 loopbacks to all towers.
core-01
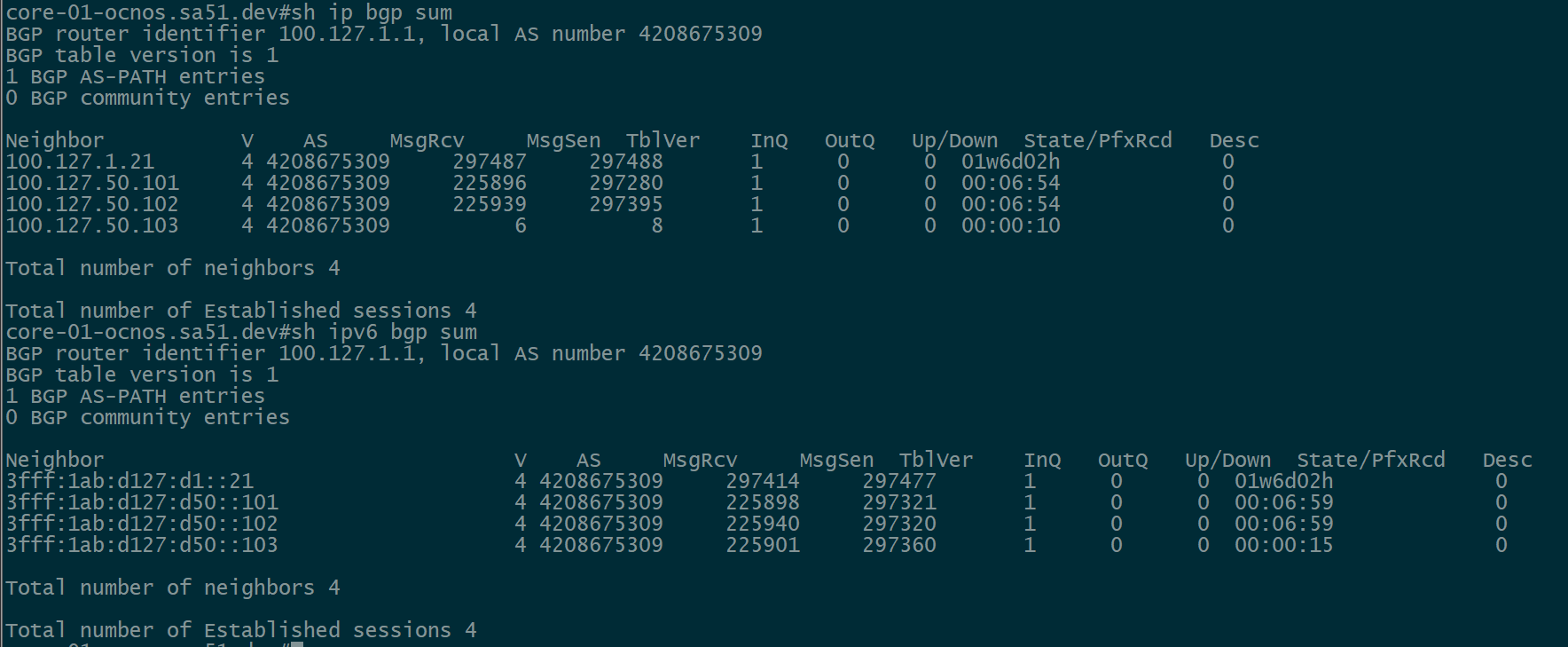
twr-02

BGP EVPN VNI and Route Target Import/Export configured
In order to create the dynamic VTEPS in VxLAN for a VNI, we have to create the correct EVPN configuration for the VNIs we are going to use as well as route target import & export
twr-01
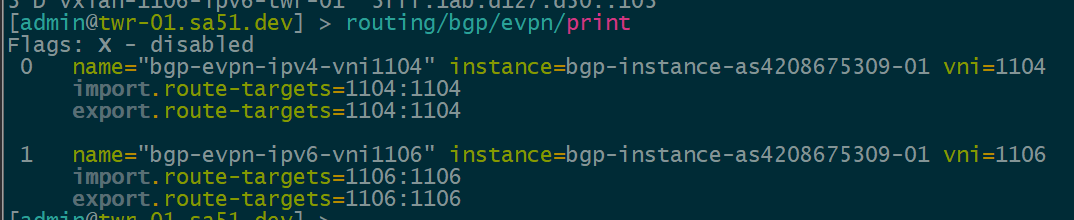
BGP EVPN Routes advertised and learned
Now let’s validate that EVPN routes are being reflected and learned between the towers and the RR. Based on the output, we see multiple EVPN Type 3 routes with a next hop to each of the three tower loopbacks for IPv4 and IPv6.
core-01
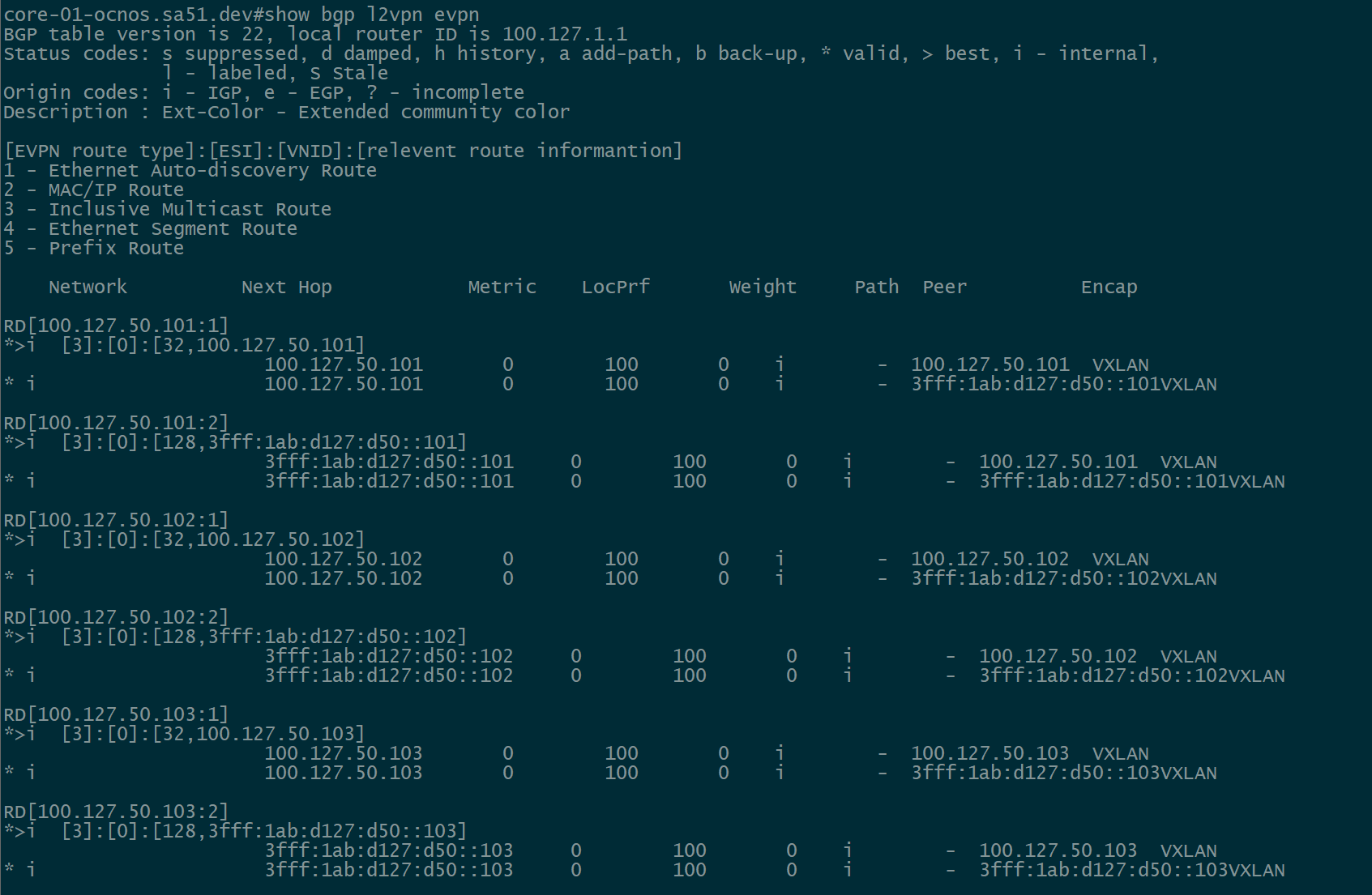
twr-01
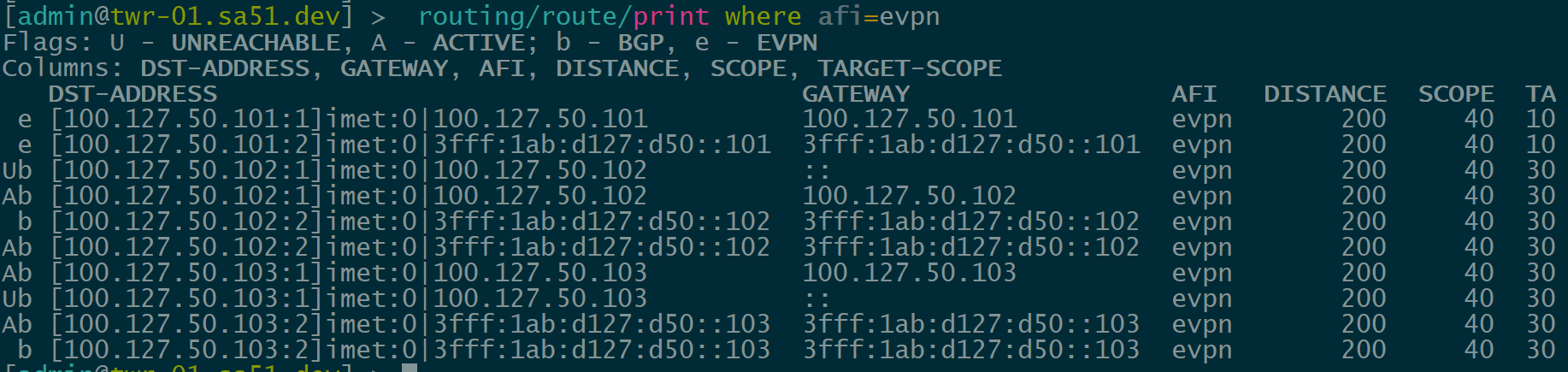
Dynamic VTEPs created
Now that EVPN is working and exchanging information on the VNIs we have configured, we can see the VTEPS have ben automatically created over both IPv4 and IPv6 and each tower can reach the other within the VNIs.
twr-01
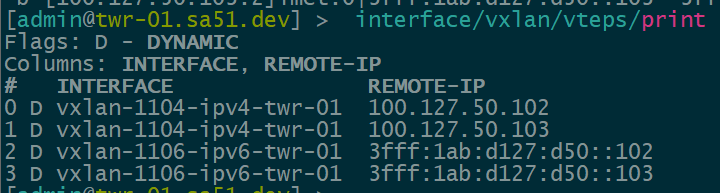
twr-02
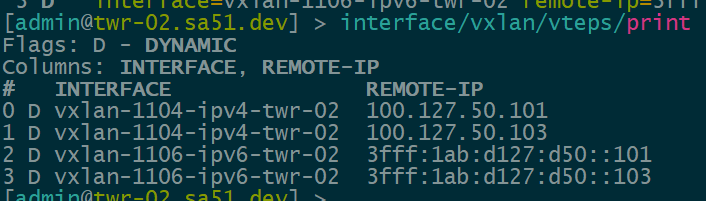
twr-03
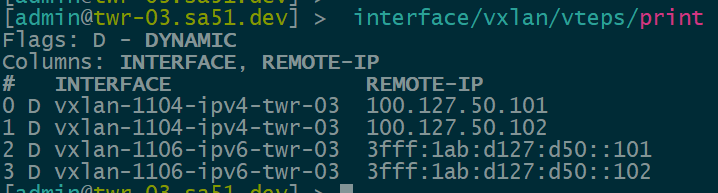
Overlay Reachability
The final validation is to check and see if the IPv4 addresses configured over each type of VTEP can reach each other within the overlay.
VNI 1104 is tied to VLAN1104 for IPv4 VTEPs and uses 198.18.104.0/24
VNI 1106 is tied to VLAN1106 for IPv6 VTEPs and uses 198.18.106.0/24
IPv4 over IPv4 EVPN/VxLAN – twr-01 to twr-03
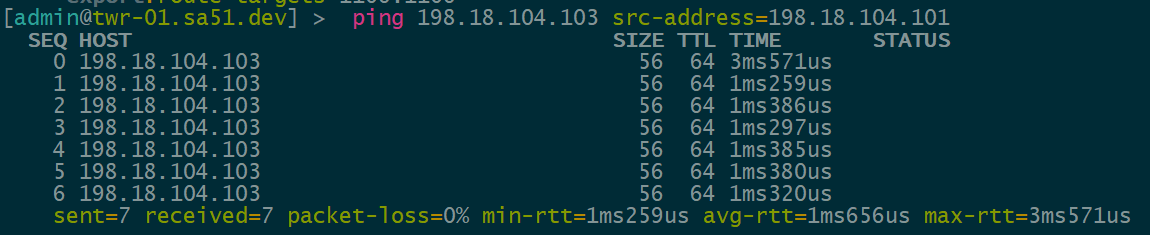
IPv4 over IPv6 EVPN/VxLAN – twr-02 to twr-01
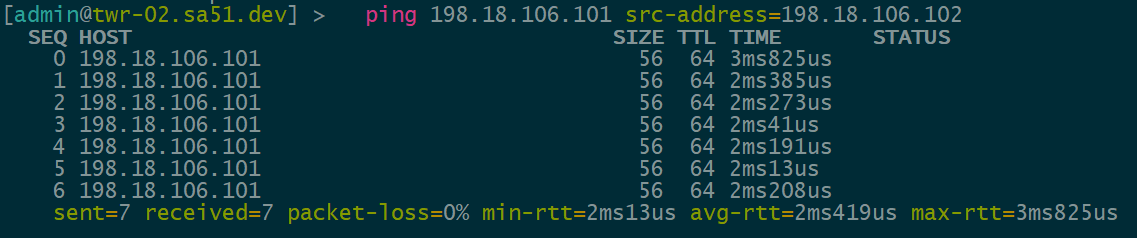
Lab configurations
OcNOS VM for EVE-NG can be downloaded here:
MikroTik CHR VM can be downloaded here:
EVE-NG can be downloaded here:
core-01-ocnos.sa51.dev
! Software version: DEMO_VM-OcNOS-SP-PLUS-x86-6.6.0.248-GA 03/24/2025 05:49:09
!
! No configuration change since last reboot
!
feature netconf-ssh
feature netconf-tls
!
service password-encryption
!
snmp-server enable traps link linkDown
snmp-server enable traps link linkUp
!
bgp extended-asn-cap
!
qos enable
!
hostname core-01-ocnos.sa51.dev
no ip domain-lookup
errdisable cause stp-bpdu-guard
feature telnet vrf management
feature dns relay
ip dns relay
ipv6 dns relay
feature ntp vrf management
ntp enable vrf management
!
nvo vxlan enable
!
ip vrf management
!
interface po1
description core-01-to-core-02
shutdown
ip router isis sa51
ipv6 router isis sa51
!
interface lo
ip address 127.0.0.1/8
ip address 100.127.1.1/32 secondary
ipv6 address ::1/128
ipv6 address 3fff:1ab:d127:d1::1/128
ip router isis sa51
ipv6 router isis sa51
!
interface eth0
ip vrf forwarding management
ip address dhcp
ipv6 address autoconfig
!
interface eth1
!
interface eth2
description core-01-to-agg-01
ip address 100.126.1.49/29
ipv6 address 3fff:1ab:d1:d48::49/64
ip router isis sa51
ipv6 router isis sa51
!
interface eth3
!
interface eth4
description core-01-to-core-02
ip address 100.126.1.41/29
ipv6 address 3fff:1ab:d1:d40::41/64
ip router isis sa51
ipv6 router isis sa51
!
interface eth5
description core-01-to-core-02
shutdown
!
interface eth6
description to-edge-01
ip address 100.126.1.1/29
ipv6 address 3fff:1ab:d1:d0::1/64
ip router isis sa51
ipv6 router isis sa51
!
interface eth7
!
exit
!
router isis sa51
is-type level-2-only
metric-style wide
net 49.0051.1001.2700.1001.00
!
router bgp 4208675309
bgp router-id 100.127.1.1
no bgp inbound-route-filter
neighbor bgp-pg-ipv4-as4208675309 peer-group
neighbor bgp-pg-ipv4-as4208675309 remote-as 4208675309
neighbor bgp-pg-ipv4-as4208675309 update-source lo
neighbor bgp-pg-ipv4-as4208675309 timers 5 15
neighbor bgp-pg-ipv6-as4208675309 peer-group
neighbor bgp-pg-ipv6-as4208675309 remote-as 4208675309
neighbor bgp-pg-ipv6-as4208675309 update-source lo
neighbor bgp-pg-ipv6-as4208675309 timers 5 15
neighbor 100.127.1.21 peer-group bgp-pg-ipv4-as4208675309
neighbor 100.127.50.101 peer-group bgp-pg-ipv4-as4208675309
neighbor 100.127.50.102 peer-group bgp-pg-ipv4-as4208675309
neighbor 100.127.50.103 peer-group bgp-pg-ipv4-as4208675309
neighbor 3fff:1ab:d127:d1::21 peer-group bgp-pg-ipv6-as4208675309
neighbor 3fff:1ab:d127:d50::101 peer-group bgp-pg-ipv6-as4208675309
neighbor 3fff:1ab:d127:d50::102 peer-group bgp-pg-ipv6-as4208675309
neighbor 3fff:1ab:d127:d50::103 peer-group bgp-pg-ipv6-as4208675309
!
address-family ipv4 unicast
neighbor bgp-pg-ipv4-as4208675309 activate
neighbor bgp-pg-ipv4-as4208675309 route-reflector-client
exit-address-family
!
address-family l2vpn evpn
neighbor bgp-pg-ipv4-as4208675309 activate
neighbor bgp-pg-ipv4-as4208675309 route-reflector-client
neighbor bgp-pg-ipv6-as4208675309 activate
neighbor bgp-pg-ipv6-as4208675309 route-reflector-client
exit-address-family
!
address-family ipv6 unicast
neighbor bgp-pg-ipv6-as4208675309 activate
neighbor bgp-pg-ipv6-as4208675309 route-reflector-client
exit-address-family
!
exit
!
!agg-01-ocnos.sa51.dev
! Software version: DEMO_VM-OcNOS-SP-PLUS-x86-6.6.0.248-GA 03/24/2025 05:49:09
!
! No configuration change since last reboot
!
feature netconf-ssh
feature netconf-tls
!
service password-encryption
!
snmp-server enable traps link linkDown
snmp-server enable traps link linkUp
!
bgp extended-asn-cap
!
qos enable
!
hostname agg-01-ocnos.sa51.dev
no ip domain-lookup
bridge 1 protocol ieee vlan-bridge
errdisable cause stp-bpdu-guard
data-center-bridging enable bridge 1
feature telnet vrf management
feature dns relay
ip dns relay
ipv6 dns relay
feature ntp vrf management
ntp enable vrf management
!
vlan database
vlan 101 bridge 1 state enable
!
nvo vxlan enable
!
ip vrf management
!
mac vrf vrf-evpn-1101
rd 100.127.1.21:1101
route-target both evpn-auto-rt
!
nvo vxlan vtep-ip-global 100.127.1.21
!
interface lo
ip address 127.0.0.1/8
ip address 100.127.1.21/32 secondary
ipv6 address ::1/128
ipv6 address 3fff:1ab:d127:d1::21/128
ip router isis sa51
ipv6 router isis sa51
!
interface eth0
ip vrf forwarding management
ip address dhcp
ipv6 address autoconfig
!
interface eth1
!
interface eth2
description agg-01-to-twr-01
ip address 100.126.50.1/29
ipv6 address 3fff:1ab:d50:d0::1/64
ip router isis sa51
ipv6 router isis sa51
!
interface eth3
description agg-01-to-twr-02
ip address 100.126.50.17/29
ipv6 address 3fff:1ab:d50:d16::d17/64
ip router isis sa51
ipv6 router isis sa51
!
interface eth4
switchport
bridge-group 1
!
interface eth5
description agg-01-to-core-01
ip address 100.126.1.50/29
ipv6 address 3fff:1ab:d1:d48::50/64
ip router isis sa51
ipv6 router isis sa51
!
interface eth6
!
interface eth7
!
exit
!
router isis sa51
is-type level-2-only
metric-style wide
net 49.0051.1001.2700.1021.00
!
router bgp 4208675309
bgp router-id 100.127.1.21
no bgp inbound-route-filter
neighbor bgp-pg-ipv4-as4208675309 peer-group
neighbor bgp-pg-ipv4-as4208675309 remote-as 4208675309
neighbor bgp-pg-ipv4-as4208675309 update-source lo
neighbor bgp-pg-ipv4-as4208675309 timers 5 15
neighbor bgp-pg-ipv6-as4208675309 peer-group
neighbor bgp-pg-ipv6-as4208675309 remote-as 4208675309
neighbor bgp-pg-ipv6-as4208675309 update-source lo
neighbor bgp-pg-ipv6-as4208675309 timers 5 15
neighbor 100.127.1.1 peer-group bgp-pg-ipv4-as4208675309
neighbor 3fff:1ab:d127:d1::1 peer-group bgp-pg-ipv6-as4208675309
!
address-family ipv4 unicast
neighbor bgp-pg-ipv4-as4208675309 activate
neighbor bgp-pg-ipv4-as4208675309 route-reflector-client
exit-address-family
!
address-family l2vpn evpn
neighbor bgp-pg-ipv4-as4208675309 activate
neighbor bgp-pg-ipv4-as4208675309 route-reflector-client
neighbor bgp-pg-ipv6-as4208675309 activate
exit-address-family
!
address-family ipv6 unicast
neighbor bgp-pg-ipv6-as4208675309 activate
exit-address-family
!
exit
!
!
endtwr-01.sa51.dev
/interface bridge
add name=br-router vlan-filtering=yes
add name=lo.4
add name=lo.6
/interface ethernet
set [ find default-name=ether1 ] disable-running-check=no
set [ find default-name=ether2 ] disable-running-check=no
set [ find default-name=ether3 ] disable-running-check=no
set [ find default-name=ether4 ] disable-running-check=no
set [ find default-name=ether5 ] disable-running-check=no
set [ find default-name=ether6 ] disable-running-check=no
set [ find default-name=ether7 ] disable-running-check=no
set [ find default-name=ether8 ] disable-running-check=no
/interface vxlan
add bridge=br-router bridge-pvid=1104 learning=no local-address=100.127.50.101 mac-address=72:F8:A7:93:B5:43 name=vxlan-1104-ipv4-twr-01 vni=1104
add bridge=br-router bridge-pvid=1106 learning=no local-address=3fff:1ab:d127:d50::101 mac-address=0E:2C:97:B8:5F:8D name=vxlan-1106-ipv6-twr-01 vni=1106 \
vteps-ip-version=ipv6
/interface vlan
add interface=br-router name=v1104 vlan-id=1104
add interface=br-router name=v1106 vlan-id=1106
/ip vrf
add interfaces=ether8 name=vrf-lab-mgmt
/port
set 0 name=serial0
/routing bgp instance
add as=4208675309 name=bgp-instance-as4208675309-01 router-id=100.127.50.101
/routing bgp template
add afi=ip as=4208675309 hold-time=15s keepalive-time=5s name=bgp-tmplt-ipv4-as4208675309
add afi=ipv6 as=4208675309 hold-time=15s keepalive-time=5s name=bgp-tmplt-ipv6-as4208675309
/routing id
add disabled=no id=100.127.50.101 name=id-main select-dynamic-id=""
/routing isis instance
add afi=ip,ipv6 areas=49.0051 l2.originate-default=never name=ipvx-isis-1 system-id=1001.2705.0101
/ipv6 settings
set accept-router-advertisements=yes
/interface bridge vlan
add bridge=br-router tagged=br-router vlan-ids=1106
add bridge=br-router tagged=br-router vlan-ids=1104
/ip address
add address=100.126.50.2/29 interface=ether1 network=100.126.50.0
add address=100.127.50.101 interface=lo.4 network=100.127.50.101
add address=100.126.50.9/29 interface=ether2 network=100.126.50.8
add address=198.18.106.101/24 interface=v1106 network=198.18.106.0
add address=198.18.104.101/24 interface=v1104 network=198.18.104.0
/ip dhcp-client
add interface=ether8
/ipv6 route
add gateway=3fff:da7a:1ab:77::1 routing-table=vrf-lab-mgmt vrf-interface=vrf-lab-mgmt
/ip service
set ssh vrf=vrf-lab-mgmt
set winbox vrf=vrf-lab-mgmt
/ipv6 address
add address=3fff:1ab:d127:d50::101/128 advertise=no interface=lo.6
/routing bgp connection
add afi=ip,evpn disabled=no instance=bgp-instance-as4208675309-01 local.address=100.127.50.101 .role=ibgp name=bgp-peer-ipv4-core-01 remote.address=100.127.1.1 \
.as=4208675309 templates=bgp-tmplt-ipv4-as4208675309
add afi=ipv6,evpn instance=bgp-instance-as4208675309-01 local.address=3fff:1ab:d127:d50::101 .role=ibgp name=bgp-peer-ipv6-core-01 remote.address=\
3fff:1ab:d127:d1::1 .as=4208675309 templates=bgp-tmplt-ipv6-as4208675309
/routing bgp evpn
add export.route-targets=1104:1104 import.route-targets=1104:1104 instance=bgp-instance-as4208675309-01 name=bgp-evpn-ipv4-vni1104 vni=1104
add export.route-targets=1106:1106 import.route-targets=1106:1106 instance=bgp-instance-as4208675309-01 name=bgp-evpn-ipv6-vni1106 vni=1106
/routing isis interface-template
add instance=ipvx-isis-1 interfaces=lo.4 levels=l2
add instance=ipvx-isis-1 interfaces=lo.6 levels=l2
add instance=ipvx-isis-1 interfaces=ether1 levels=l2
add instance=ipvx-isis-1 interfaces=ether2 levels=l2
add instance=ipvx-isis-1 interfaces=ether3 levels=l2
add instance=ipvx-isis-1 interfaces=ether4 levels=l2
/system identity
set name=twr-01.sa51.dev
/system note
set show-at-login=no
/tool romon
set enabled=yes
/tool sniffer
set file-limit=10000KiB file-name=bgp-twr-01 filter-ip-protocol=tcp filter-port=bgptwr-02.sa51.dev
/interface bridge
add name=br-router vlan-filtering=yes
add name=lo.4
add name=lo.6
/interface ethernet
set [ find default-name=ether1 ] disable-running-check=no
set [ find default-name=ether2 ] disable-running-check=no
set [ find default-name=ether3 ] disable-running-check=no
set [ find default-name=ether4 ] disable-running-check=no
set [ find default-name=ether5 ] disable-running-check=no
set [ find default-name=ether6 ] disable-running-check=no
set [ find default-name=ether7 ] disable-running-check=no
set [ find default-name=ether8 ] disable-running-check=no
/interface vxlan
add bridge=br-router bridge-pvid=1104 learning=no local-address=100.127.50.102 mac-address=EA:DC:97:20:66:1D name=vxlan-1104-ipv4-twr-02 vni=\
1104
add bridge=br-router bridge-pvid=1106 learning=no local-address=3fff:1ab:d127:d50::102 mac-address=12:37:A4:64:42:DD name=vxlan-1106-ipv6-twr-02 \
vni=1106 vteps-ip-version=ipv6
/interface vlan
add interface=br-router name=v1104 vlan-id=1104
add interface=br-router name=v1106 vlan-id=1106
/ip vrf
add interfaces=ether8 name=vrf-lab-mgmt
/port
set 0 name=serial0
/routing bgp instance
add as=4208675309 name=bgp-instance-as4208675309-01 router-id=100.127.50.102
/routing bgp template
add afi=ip as=4208675309 hold-time=15s keepalive-time=5s name=bgp-tmplt-ipv4-as4208675309
add afi=ipv6 as=4208675309 hold-time=15s keepalive-time=5s name=bgp-tmplt-ipv6-as4208675309
/routing id
add disabled=no id=100.127.50.102 name=id-main select-dynamic-id=""
/routing isis instance
add afi=ip,ipv6 areas=49.0051 l2.originate-default=never name=ipvx-isis-1 system-id=1001.2705.0102
/ipv6 settings
set accept-router-advertisements=yes
/interface bridge vlan
add bridge=br-router tagged=br-router vlan-ids=1106
add bridge=br-router tagged=br-router vlan-ids=1104
/ip address
add address=100.126.50.18/29 interface=ether1 network=100.126.50.16
add address=100.127.50.102 interface=lo.4 network=100.127.50.102
add address=100.126.50.25/29 interface=ether3 network=100.126.50.24
add address=198.18.106.102/24 interface=v1106 network=198.18.106.0
add address=198.18.104.102/24 interface=v1104 network=198.18.104.0
/ip dhcp-client
add interface=ether8
/ipv6 route
add gateway=3fff:da7a:1ab:77::1 routing-table=vrf-lab-mgmt vrf-interface=vrf-lab-mgmt
/ip service
set ssh vrf=vrf-lab-mgmt
set winbox vrf=vrf-lab-mgmt
/ipv6 address
add address=3fff:1ab:d127:d50::102/128 advertise=no interface=lo.6
add address=3fff:1ab:d50:d16::d18 advertise=no interface=ether1
add address=3fff:1ab:d50:d24::d25 advertise=no interface=ether3
/routing bgp connection
add afi=ip,evpn disabled=no instance=bgp-instance-as4208675309-01 local.address=100.127.50.102 .role=ibgp name=bgp-peer-ipv4-core-01 \
remote.address=100.127.1.1 .as=4208675309 templates=bgp-tmplt-ipv4-as4208675309
add afi=ipv6,evpn instance=bgp-instance-as4208675309-01 local.address=3fff:1ab:d127:d50::102 .role=ibgp name=bgp-peer-ipv6-core-01 \
remote.address=3fff:1ab:d127:d1::1 .as=4208675309 templates=bgp-tmplt-ipv6-as4208675309
/routing bgp evpn
add export.route-targets=1104:1104 import.route-targets=1104:1104 instance=bgp-instance-as4208675309-01 name=bgp-evpn-ipv4-vni1104 vni=1104
add export.route-targets=1106:1106 import.route-targets=1106:1106 instance=bgp-instance-as4208675309-01 name=bgp-evpn-ipv6-vni1106 vni=1106
/routing isis interface-template
add instance=ipvx-isis-1 interfaces=lo.4 levels=l2
add instance=ipvx-isis-1 interfaces=lo.6 levels=l2
add instance=ipvx-isis-1 interfaces=ether1 levels=l2
add instance=ipvx-isis-1 interfaces=ether2 levels=l2
add instance=ipvx-isis-1 interfaces=ether3 levels=l2
add instance=ipvx-isis-1 interfaces=ether4 levels=l2
/system identity
set name=twr-02.sa51.dev
/system note
set show-at-login=no
/tool romon
set enabled=yestwr-03.sa51.dev
/interface bridge
add name=br-router vlan-filtering=yes
add name=lo.4
add name=lo.6
/interface ethernet
set [ find default-name=ether1 ] disable-running-check=no
set [ find default-name=ether2 ] disable-running-check=no
set [ find default-name=ether3 ] disable-running-check=no
set [ find default-name=ether4 ] disable-running-check=no
set [ find default-name=ether5 ] disable-running-check=no
set [ find default-name=ether6 ] disable-running-check=no
set [ find default-name=ether7 ] disable-running-check=no
set [ find default-name=ether8 ] disable-running-check=no
/interface vxlan
add bridge=br-router bridge-pvid=1104 learning=no local-address=100.127.50.103 mac-address=8E:9A:2E:06:F9:A6 name=vxlan-1104-ipv4-twr-03 vni=\
1104
add bridge=br-router bridge-pvid=1106 learning=no local-address=3fff:1ab:d127:d50::103 mac-address=BA:73:44:4C:51:5D name=vxlan-1106-ipv6-twr-03 \
vni=1106 vteps-ip-version=ipv6
/interface vlan
add interface=br-router name=v1104 vlan-id=1104
add interface=br-router name=v1106 vlan-id=1106
/ip vrf
add interfaces=ether8 name=vrf-lab-mgmt
/port
set 0 name=serial0
/routing bgp template
add afi=ip as=4208675309 hold-time=15s keepalive-time=5s name=bgp-tmplt-ipv4-as4208675309
add afi=ipv6 as=4208675309 hold-time=15s keepalive-time=5s name=bgp-tmplt-ipv6-as4208675309
/routing id
add disabled=no id=100.127.50.103 name=id-main select-dynamic-id=""
/routing bgp instance
add as=4208675309 name=bgp-instance-as4208675309-01 router-id=id-main
/routing isis instance
add afi=ip,ipv6 areas=49.0051 name=ipvx-isis-1 system-id=1001.2705.0103
/ipv6 settings
set accept-router-advertisements=yes
/interface bridge vlan
add bridge=br-router tagged=br-router vlan-ids=1106
add bridge=br-router tagged=br-router vlan-ids=1104
/ip address
add address=100.126.50.10/29 interface=ether1 network=100.126.50.8
add address=100.127.50.103 interface=lo.4 network=100.127.50.103
add address=198.18.106.103/24 interface=v1106 network=198.18.106.0
add address=198.18.104.103/24 interface=v1104 network=198.18.104.0
/ip dhcp-client
add interface=ether8
/ipv6 route
add gateway=3fff:da7a:1ab:77::1 routing-table=vrf-lab-mgmt vrf-interface=vrf-lab-mgmt
/ip service
set ssh vrf=vrf-lab-mgmt
set winbox vrf=vrf-lab-mgmt
/ipv6 address
add address=3fff:1ab:d127:d50::103/128 advertise=no interface=lo.6
/routing bgp connection
add afi=ip,evpn disabled=no instance=bgp-instance-as4208675309-01 local.address=100.127.50.103 .role=ibgp name=bgp-peer-ipv4-core-01 \
remote.address=100.127.1.1 .as=4208675309 templates=bgp-tmplt-ipv4-as4208675309
add afi=ipv6,evpn instance=bgp-instance-as4208675309-01 local.address=3fff:1ab:d127:d50::103 .role=ibgp name=bgp-peer-ipv6-core-01 \
remote.address=3fff:1ab:d127:d1::1 .as=4208675309 templates=bgp-tmplt-ipv6-as4208675309
/routing bgp evpn
add export.route-targets=1104:1104 import.route-targets=1104:1104 instance=bgp-instance-as4208675309-01 name=bgp-evpn-ipv4-vni1104 vni=1104
add export.route-targets=1106:1106 import.route-targets=1106:1106 instance=bgp-instance-as4208675309-01 name=bgp-evpn-ipv6-vni1106 vni=1106
/routing isis interface-template
add instance=ipvx-isis-1 interfaces=lo.4 levels=l2
add instance=ipvx-isis-1 interfaces=lo.6 levels=l2
add instance=ipvx-isis-1 interfaces=ether1 levels=l2
add instance=ipvx-isis-1 interfaces=ether2 levels=l2
add instance=ipvx-isis-1 interfaces=ether3 levels=l2
add instance=ipvx-isis-1 interfaces=ether4 levels=l2
/system identity
set name=twr-03.sa51.dev
/system note
set show-at-login=no
/tool romonIn MikroTik’s OSPF documentation they briefly cover the LSA for OSPFv2 but don’t have OSPFv3 listed yet.
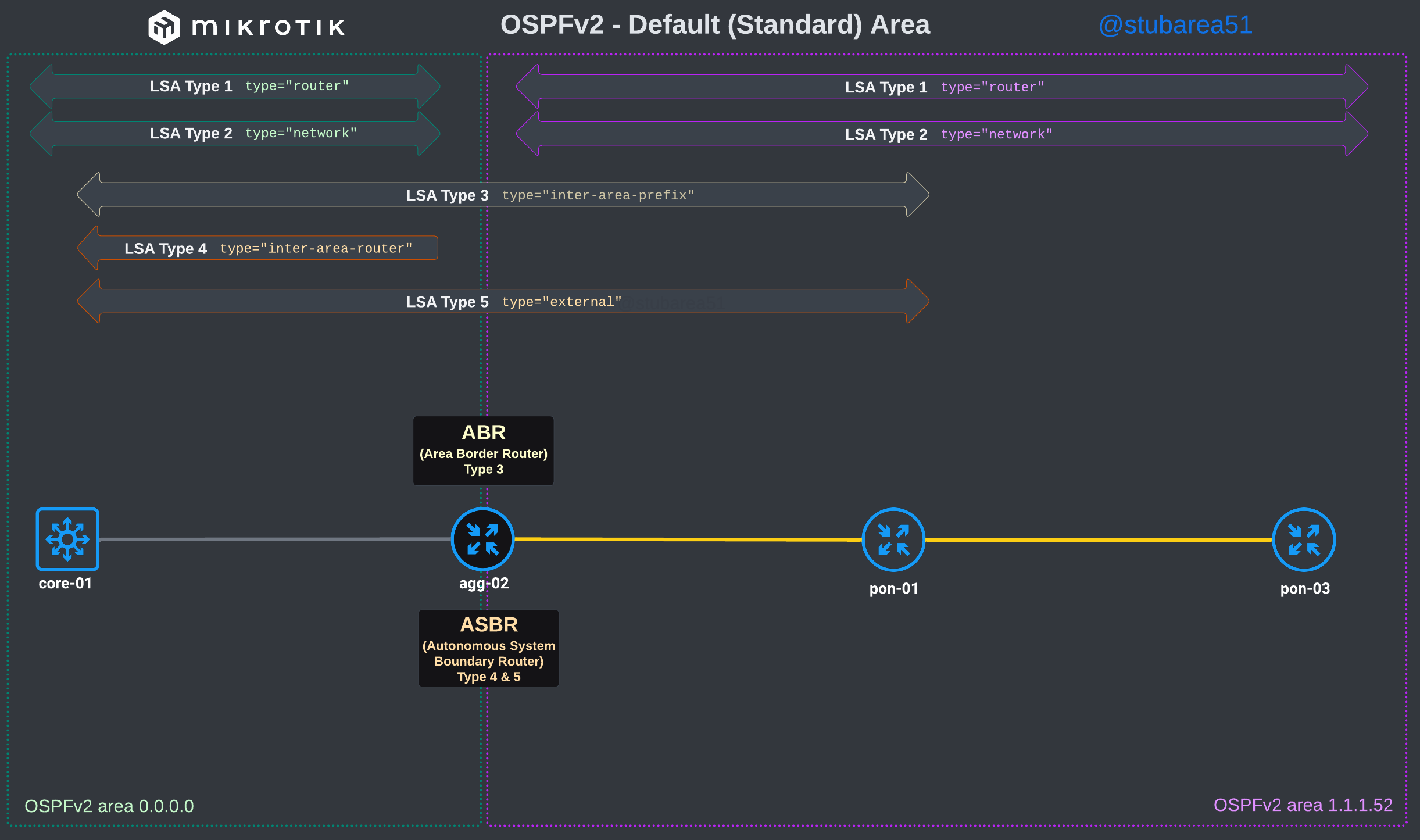
To better illustrate how the LSAs work, I created these graphical overviews for OSPFv2 and OSPFv3. When troubleshooting OSPF, it’s very helpful to understand which LSAs you should see in an area and how IPv4 and IPv6 differ.
Hope you find these helpful!
OSPFv2
OSPFv3
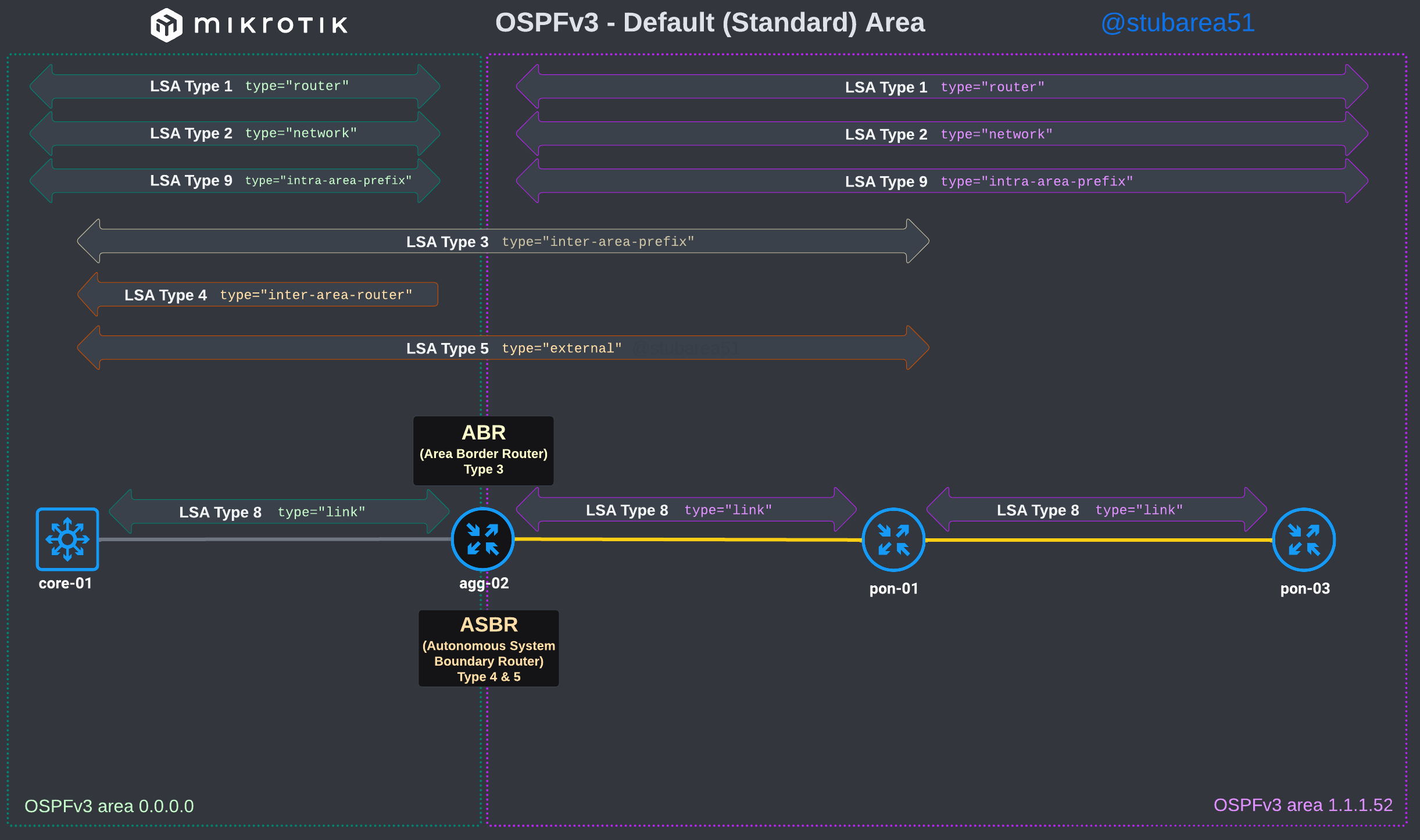
]]>
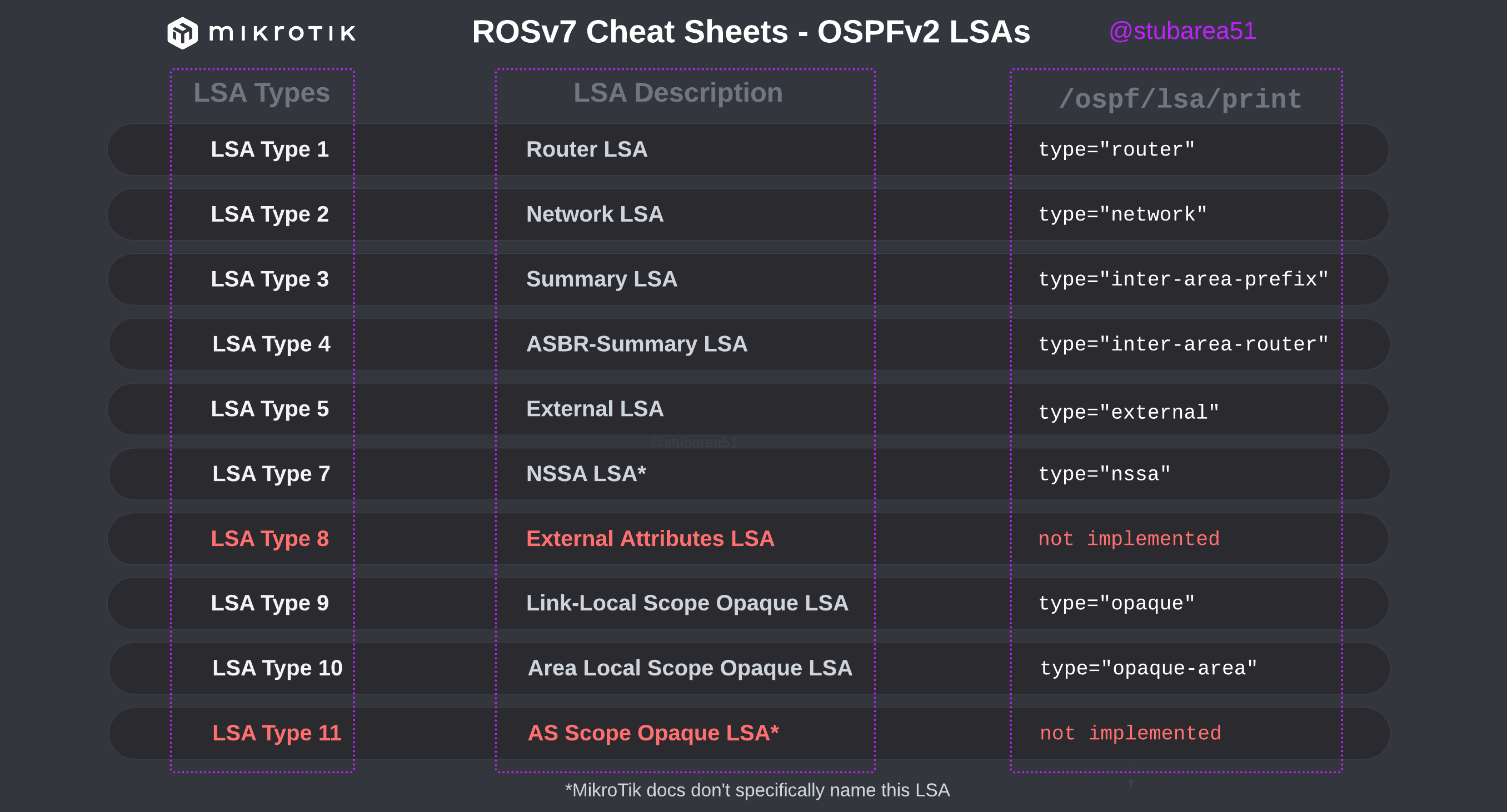
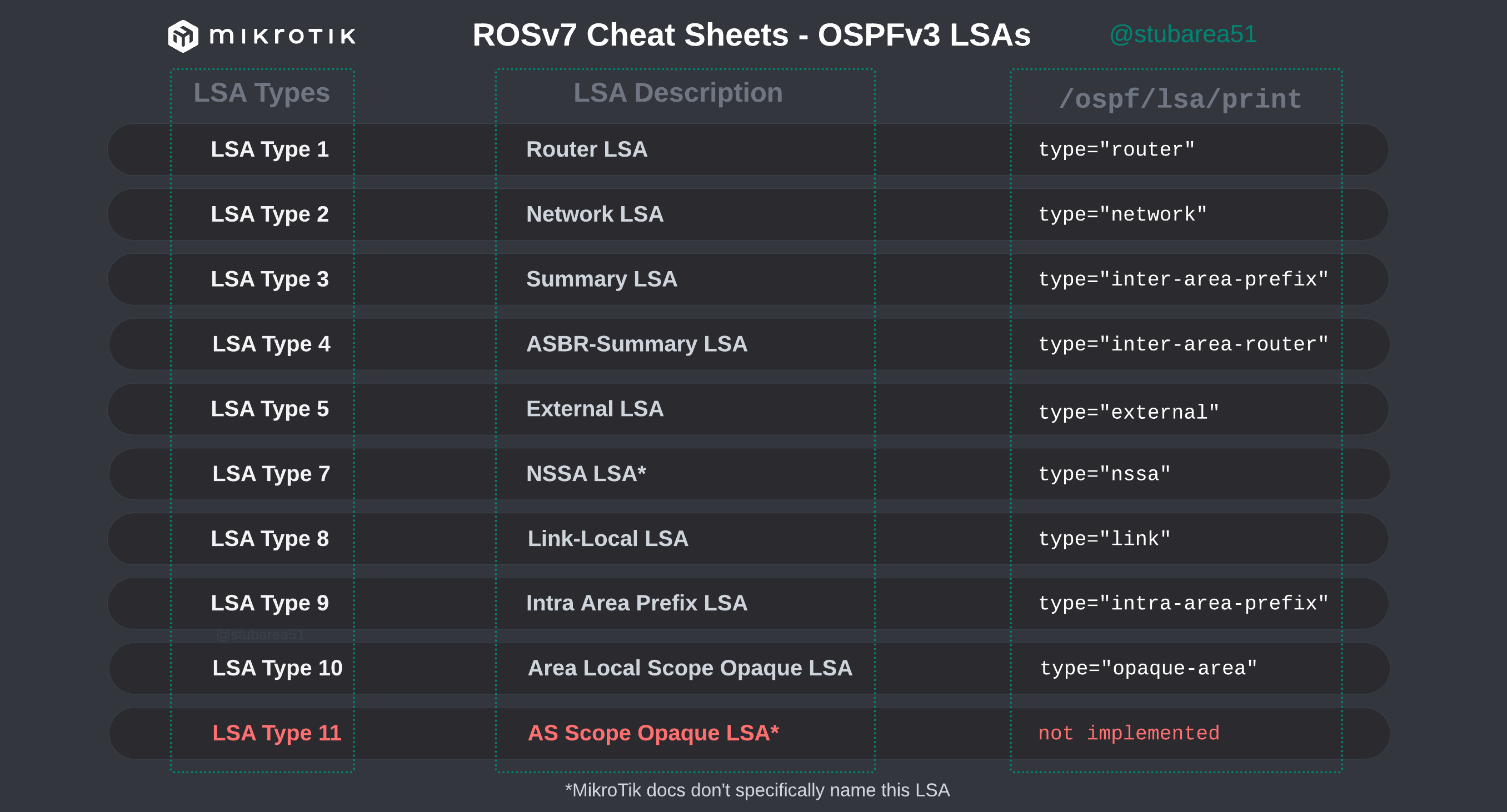
However, MikroTik’s LSA names don’t always match up to the language used in RFCs and other resources when trying to verify the behavior of an LSA is working as intended. This can make troubleshooting difficult.
These cheat sheets match up the lsa description for OSPFv2 and OSPFv3 in RouterOSv7 with the common LSA Type and number reference.
PDF links are listed below – hope you find this helpful!
OSPFv2
PDF: https://stubarea51.net/wp-content/uploads/2024/06/ROSv7-OSPF-Fundamentals-SA51-LSA-Types-OSPFv2.pdf
OSPFv3
MikroTik Routers and Wireless – Software
RouterOS continues to mature as we move through the versions in the teens.
When we transitioned between ROSv5 and ROSv6 in the early 2010s, it was right around this version numbering that we started to see production stability. By the time 6.2x versions came out, the general consensus was that v6 was ready for prime time. We are getting closer to that point in ROSv7 – depending on your use case.
Certainly, there are still issues to solve for advanced users like ISPs and Data Centers that need protocols like BGP, OSPF, IS-IS and MPLS, but simpler use cases seem to really be stabilizing with the last few months of releases.
Notable changes in this release:
*) bgp – allow to leak routes between local VRFs;
There are a few reasons this is a really important addition to ROSv7. First, it’s an issue that’s been on the roadmap for a very long time as noted in the Routing Protocol Overview section of MikroTik’s help docs. This is encouraging because it’s likely been one of the harder problems for the development team to solve given the length of time it sat open.

Secondly, it’s another step to moving ROSv7 towards better PE, BNG and multi-tenant capabilities. ROSv6 was limited to using only routing rules to leak between routing marks/VRF and overlapping address space inside each VRF was problematic.
Lastly, this paves the way for newer technologies like EVPN, VxLAN (which already exists in ROS) and SR-MPLS – all of which make use of VRFs.
!) smb – removed legacy SMB service (replaced with newer and faster ROSE SMB service);
MikroTik is doubling down on their new ROSE storage package by removing the legacy SMB code and using ROSE as the default.
While mainstream systems/storage engineers are unlikely to flock to MikroTik as an enterprise storage solution, it does open up a world of possibilities when advanced storage services are needed in a small form-factor with minimal power requirements.
Industrial, Manufacturing, Mining and ISPs have frequently used small compute/storage solutions at remote sites or in harsh environments.
It also opens up a lot of possibilities for network automation and management when coupled with the container package.
*) package – reduced “wireless” package size for ARM, ARM64, MIPSBE, MMIPS devices
Unlike mainstream vendors, MikroTik does a phenomenal job of working to keep older hardware relevant and generally does not EOL hardware frequently.
The split in the wireless packages and work to reduce the filesize of the non-Qualcomm package is a good indicator of the commitment to supporting all generations of equipment possible.
*) bth – added simple “Back To Home Users” manager under IP/Cloud menu;
MikroTik seems to be very focused on creating their own “Easy VPN” solution for home/smb users to simplify VPN connectivity.
While ZeroTier and Wireguard are fairly easy to deploy, they do require some advanced config.
It seems like MikroTik is trying to create a simplified version of Tailscale with BTH and it will be interesting to see where it goes.

Overview
This is an article i’ve wanted to write for a long time. In the last decade, the work that I have done with WISPs/FISPs in network design using commodity equipment like MikroTik and FiberStore has yielded quite a few best practices and lessons learned.
While the idea of “router on a stick” isn’t new, when I first started working with WISPs/FISPs and MikroTik routers 10+ years ago, I immediately noticed a few common elements in the requests for consulting:
“I’m out of ports on my router…how do I add more?”
“I started with a single router, how do I make it redundant and keep NAT/peering working properly”?
“I have high CPU on my router and I don’t know how to add capacity and split the traffic”
“I can’t afford Cisco or Juniper but I need a network that’s highly available and resilient”
Coming from a telco background where a large chassis was used pretty much everywhere for redundancy and relying on links split across multiple line cards with LACP, that was one of my first inclinations to solve the problem.
Much like today, getting one or more chassis-based routers for redundancy was expensive and often not practical within budgetary or physical/environmental constraints.
So I started experimenting with switch stacks as an inexpensive alternative to chassis-based equipment given that they operate using similar principles.
Let’s start with an overview of common Layer 3 network topologies in the WISP/FISP world.
WISP/FISP Topologies
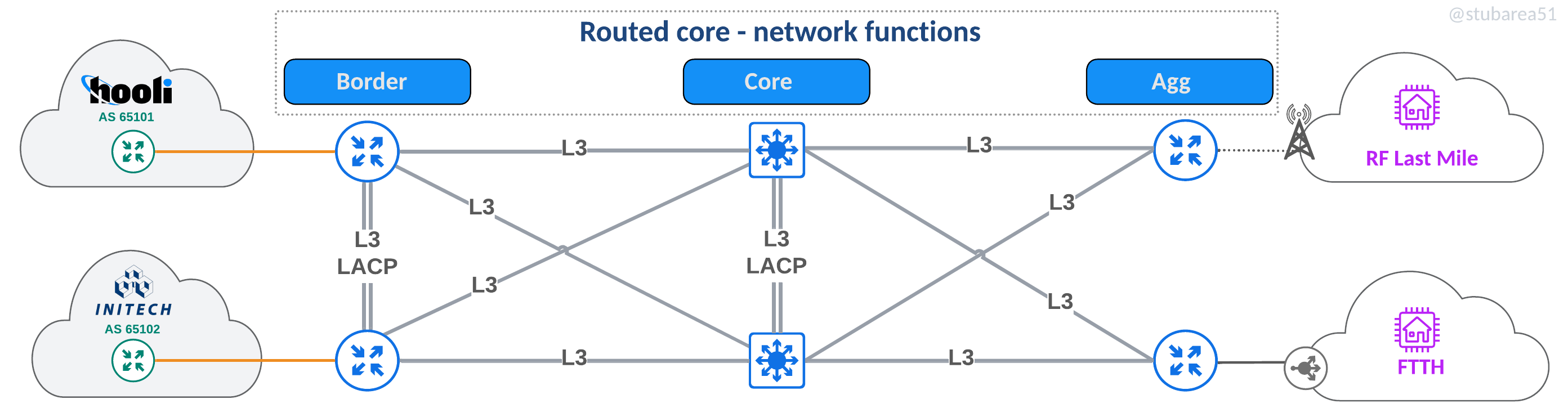
Routed
This is the most traditional design and still widely used in many small ISPs. Physical links plug directly into the router or switch that handles the corresponding network function.
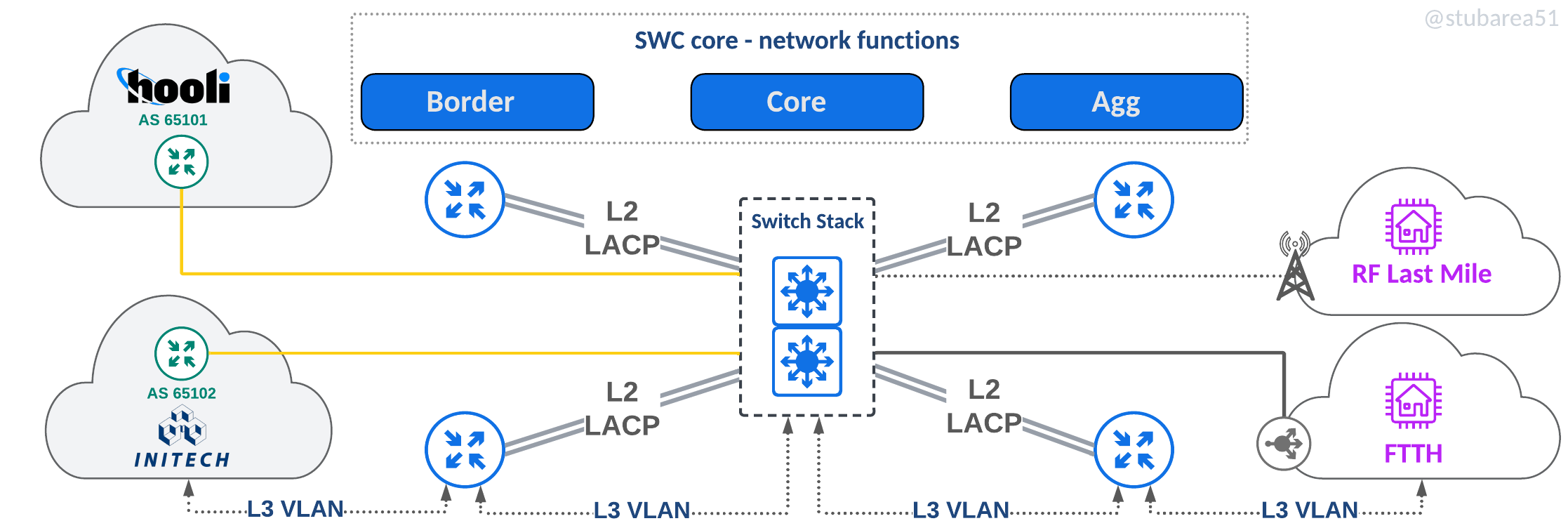
Switch Centric (SWC)
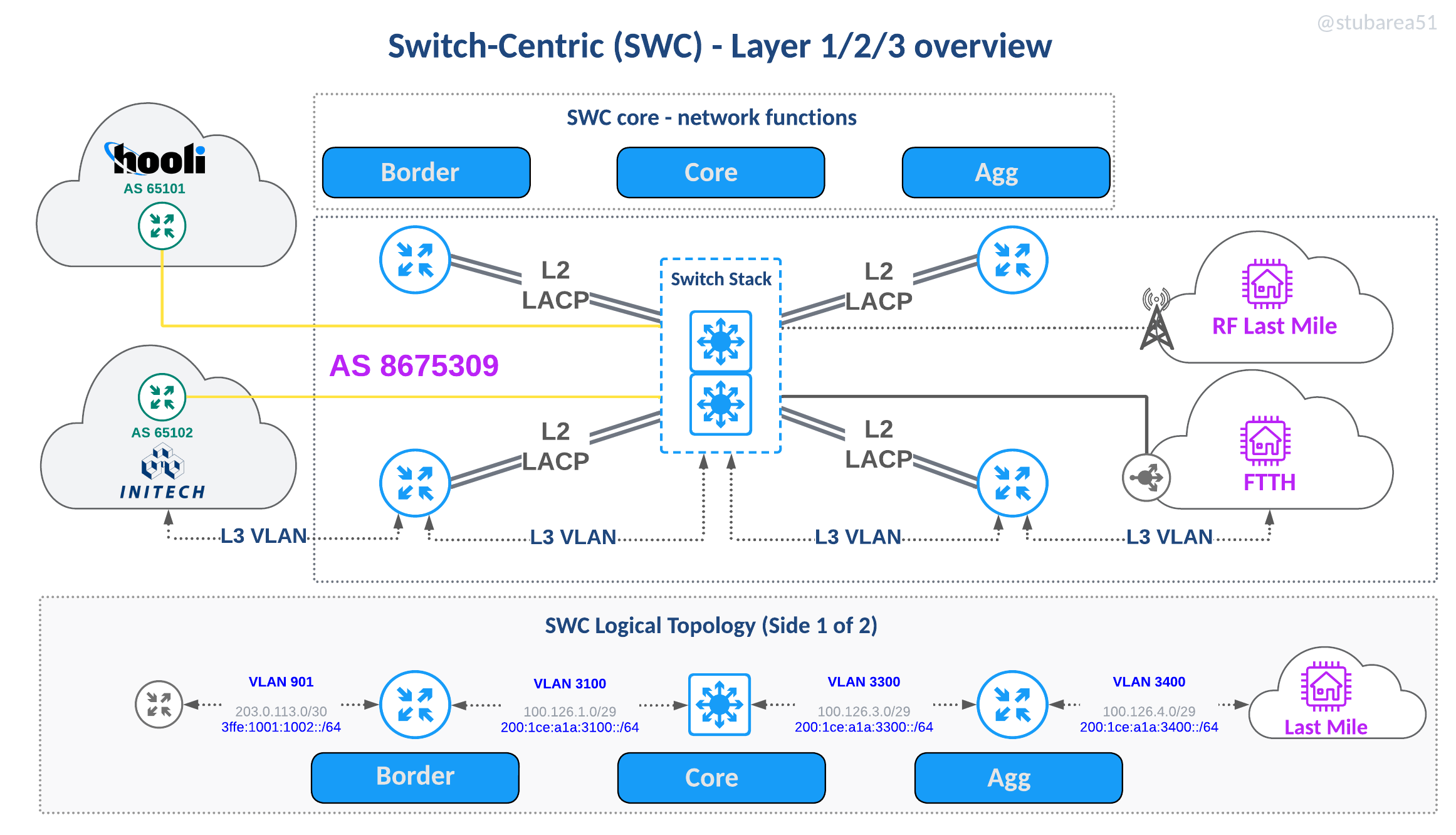
The main focus of this article, the SWC topology uses a switch stack that all links plug into and L3 paths are logically defined by VLANs.
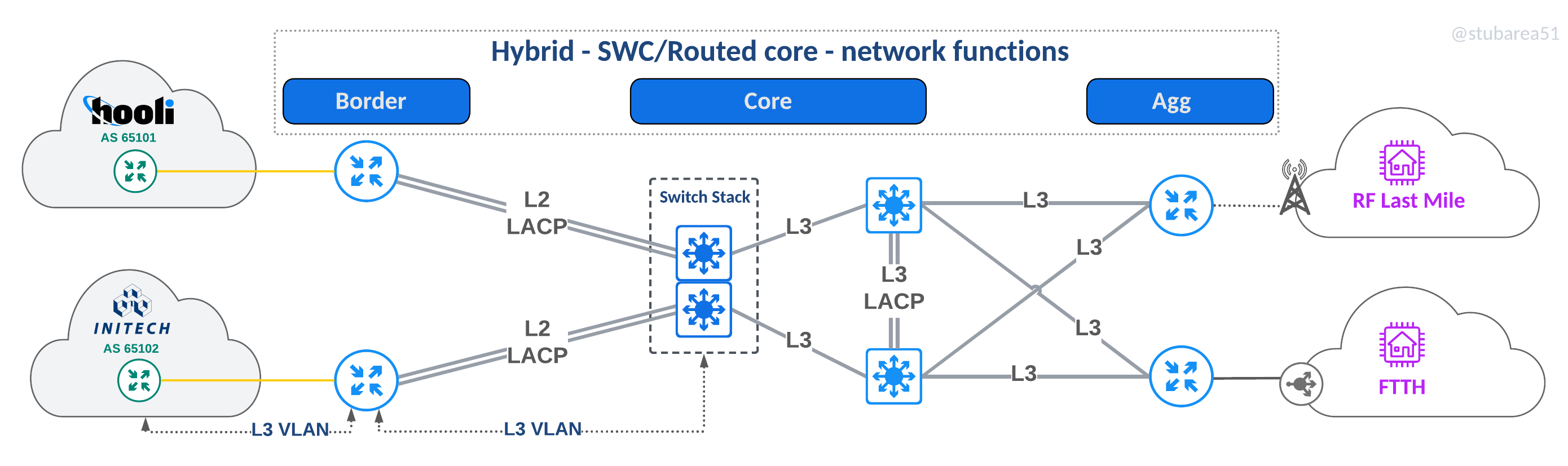
Hybrid – SWC/Routed
An approach used when both routed and SWC make sense – often used for border routers with just a few 100G ports to extend port capacity in a scalable way.
SWC begins with router on a stick
Before diving into the origins and elements of switch centric design (SWC), it’s probably helpful to talk about what “router on a stick” is and how it relates to the design.
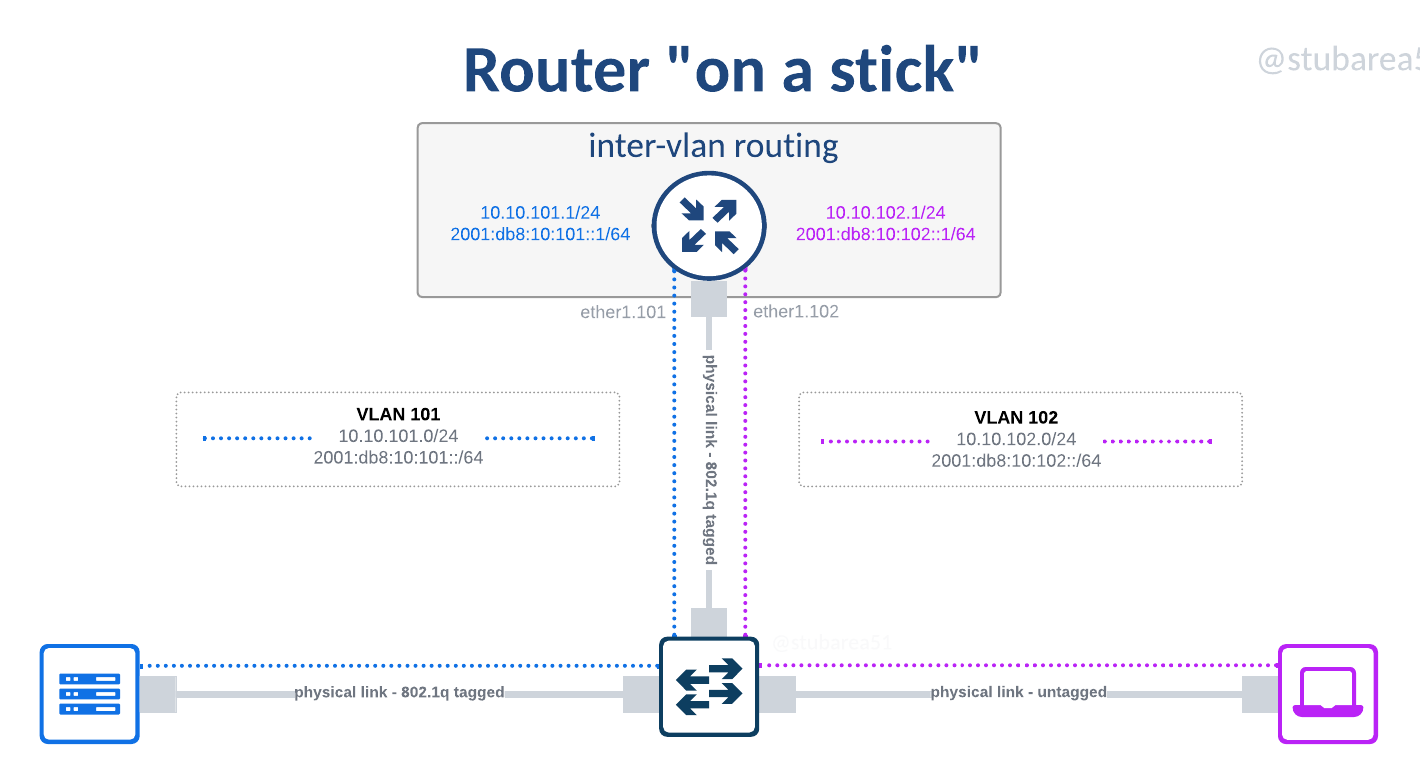
The term router on a stick refers to the use of a switch to extend the port density of a router. In the early days of ethernet networking in the 1990s and 2000s, routers were incredibly expensive and often had only one or two ports.
Even as routers became modular and cards could be added with a few more ports, it was still very expensive to add routed ports. Switches by contrast, were much cheaper and could easily handle up to 48 ports in most vendors.
It became a common practice to use a single routed port or a pair of them bonded with LACP and establish an 802.1q tagged link to a switch so that different Subnets/VLANs could be sent to the router for inter-vlan routing or sent on to a different destination like the Internet.
One of the drawbacks to this approach was the speed of the router. 20 years ago, outside of larger chassis-based platforms, routers didn’t typically exceed 100 Mbps of throughput and many were much less than that.
As such, the practice of using “router on a stick” began to fall out of favor with network designers for a few reasons:
1. The advent of L3 switching – as ASICs became commonplace in the 2000s and leading into the 2010s, routers weren’t needed at every L3 point in the network anymore. This improved performance and reduced cost.
2. Layer 2 problems – 20 years ago, it was harder to mitigate against L2 issues like loops and broadcast storms because not all devices had L2 protections that almost every managed switch now has like storm control, MSTP, mac-based loop guards, etc.
Why router on a stick for WISP/FISP networks?
The short answer lies in the use of commodity routers like MikroTik and Ubiquiti for WISP/FISP networks.
Both vendors are popular with WISPs as they bring advanced feature sets like MPLS and BGP into routers that cost only hundreds of dollars. The flagship models even today don’t exceed several thousand dollars.
As small ISPs moved from 1G to 10G in their core networks roughly 10 years ago, a number of routers were released from both vendors with a limited number of 10G ports.
A MikroTik CCR1036-8G-2S+ router that became one of the most popular SWC routers

It quickly became apparent in the WISPs/FISPs that I worked with that more 10G ports were needed to properly connect routers, radios, servers and other systems together.
Although the driver for using router on a stick was port density, I’d later discover a number of other benefits that are still relevant today.
Before getting into the benefits of connecting all devices to the switch, switch stacking is the next component of the journey in SWC design.
Adding switch stacking
Router on a stick was only part of the equation as we worked through early iterations of the design – adding high availability was another needed component.
Adding multiple independent switches to routers that had ports tagged down to the switch became messy because L2 loop prevention was needed in order to manage links.
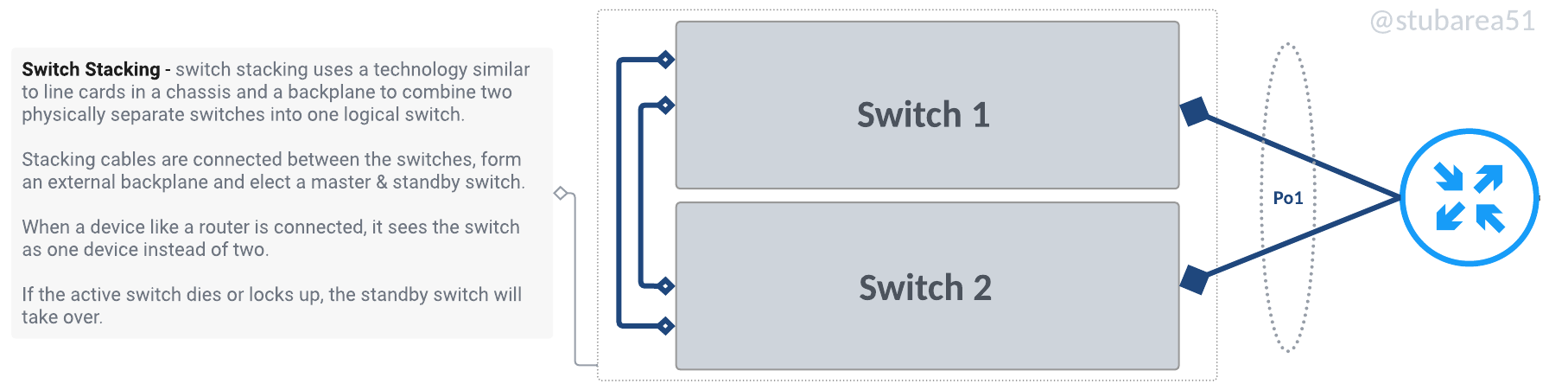
What is a switch stack?
Switch stacking allows multiple switches to be combined into one logical switch using either a backplane or frontplane via dedicated cabling instead of a circuit board like you’d find in a chassis.
Fiber Store has a great blog article about it and the difference between stacking and MLAG.
Switch Stacking Explained: Basis, Configuration & FAQs | FS Community
Types of switch stacking
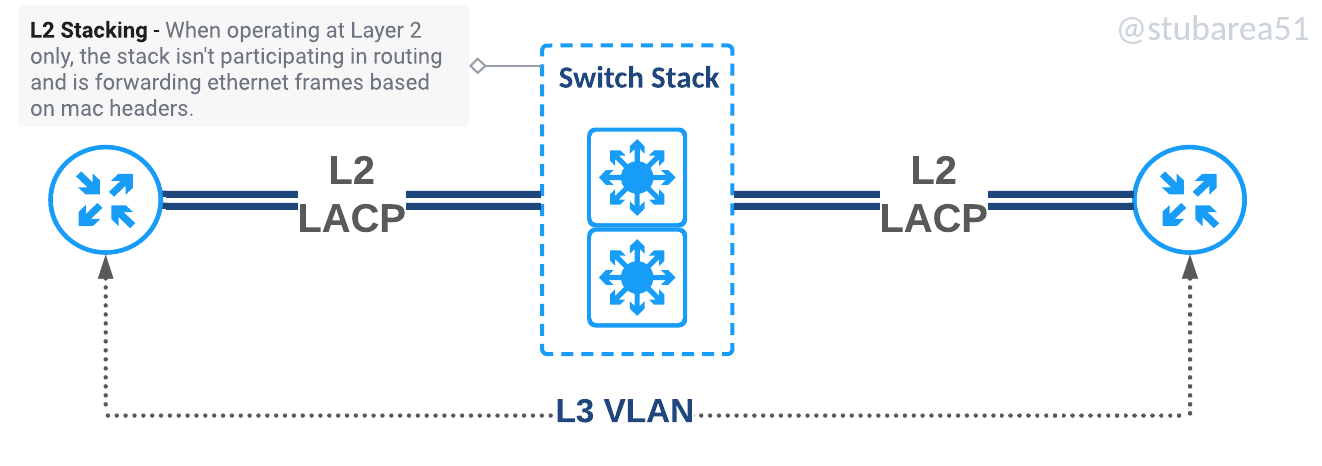
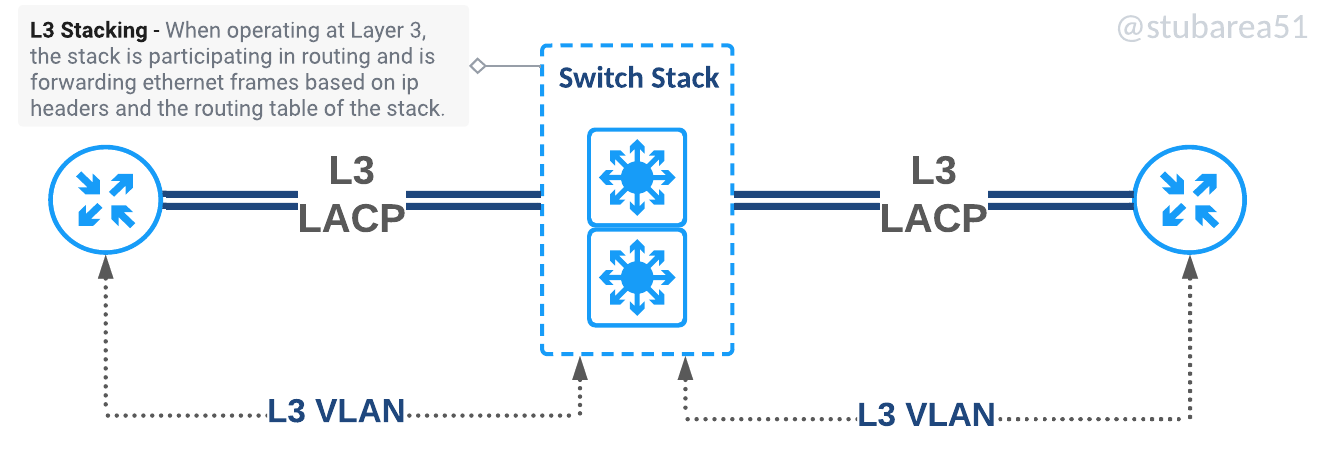
There are two main types of switch stacking. Those that allow stacking of layer 2 only and those that allow stacking of layer2 and layer3. Our earliest designs used only L2 stacking as it was less expensive to build but as the cost of switches that support stacking and L3 came down in the mid-2010s, it became easier use Layer 3 stacking going forward.
Stacking and Backplanes
The idea of backplanes in computing goes back to at least the mid 20th century. It’s an efficient way to tie together data communication into a bus architecture.
in this context, a bus is defined as:
“a group of electrical connectors in parallel with each other, so that each pin of each connector is linked to the same relative pin of all the other connectors” source: wikipedia
Here is a wire-based backplane from a 1960s computer.

Chassis backplane
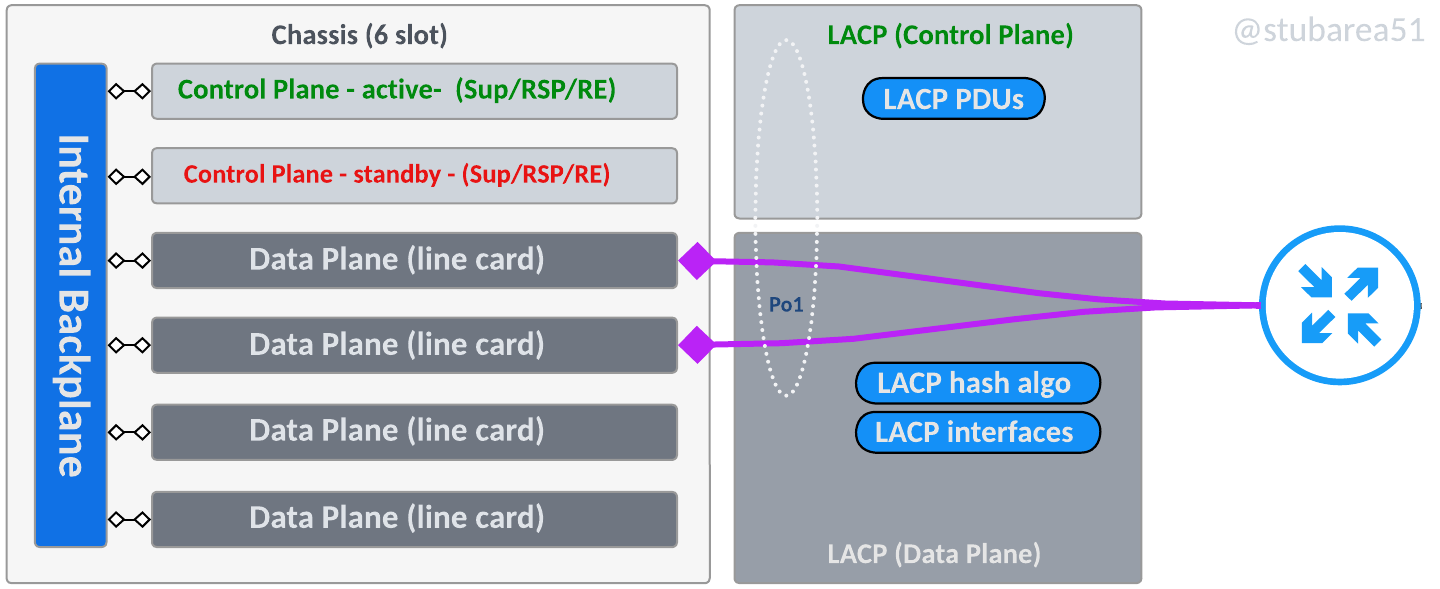
Does a switch stack actually have a “backplane” or is it a ring?
When only two switches are stacked, technically it’s both but as the number of switches increase, stack connectivity becomes more of a ring than a true bus architecture like a chassis backplane.
In the context of this article, it’s helpful to think about the “backplane” as the communication channel that ties the switches together and carries traffic between switches as needed.
Some vendors refer to the stack communication as a backplane, a frontplane, a channel, a ring, stacking links, etc
Even though certain stack configurations don’t exactly fit the definition of a backplane with a bus, it’s a common reference and we’ll illustrate the two main types of switching planes.
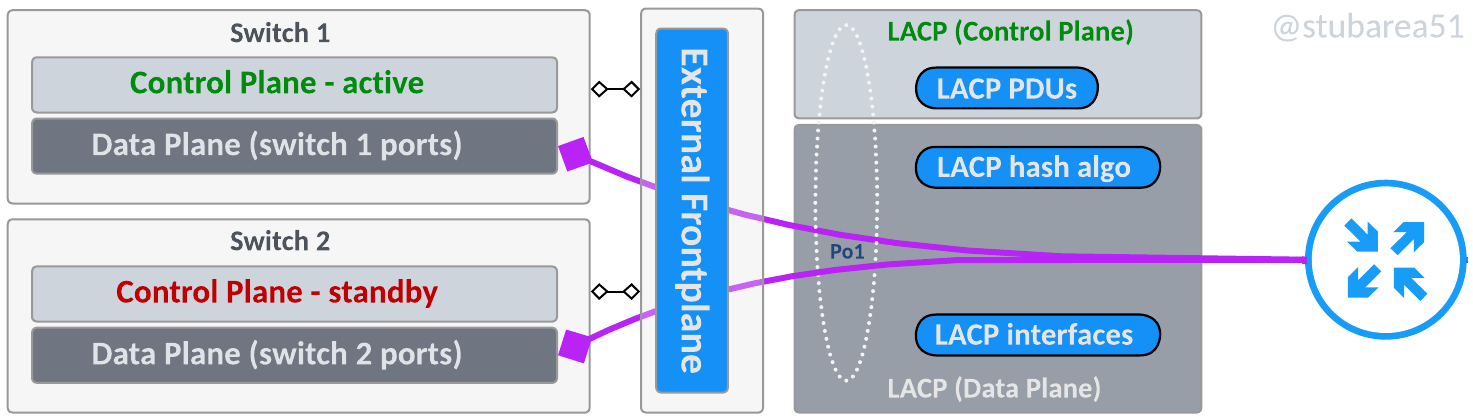
Stacking backplane
With two switches, this topology is closest to a chassis backplane and uses dedicated stacking modules with proprietary cabling. Most switch manufacturers have moved away from this design towards a “frontplane”
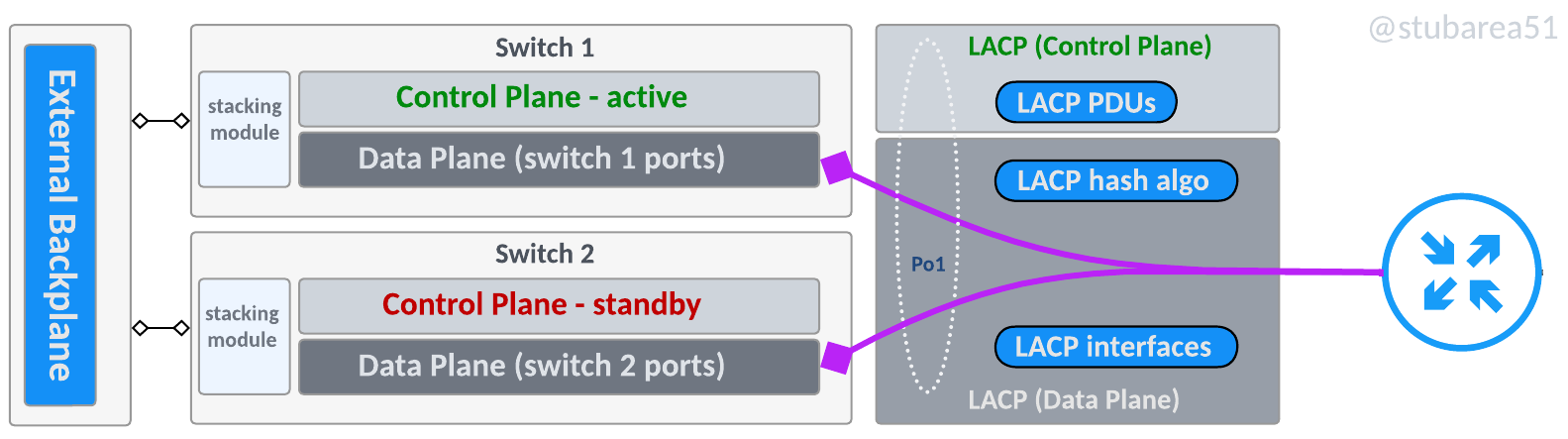
Stacking frontplane
A stacking frontplane uses built in 10G, 25G, 40G or 100G ports to establish the stack communication for the control plane and the data plane.
The ports are configured for stack communication in the CLI, typically when the switches are setup and cannot be used or configured for specific IPs or VLANs as the switch manages all communication internally.
Chassis vs. Stack
If the underlying architecture between chassis and stacking is so similar, why not just use stacking everywhere?
This is where the business context comes into play. There are several advantages that a chassis has over stacking.
Chassis advantages
- Failover time – usually a control plane failure or line card failure is almost immediate and sometimes even lossless. Stacking usually takes longer to recover from failure and is typically in the realm of 15 to 30 seconds for stack switchover
- Upgrades – upgrading software while certainly a more complex operation in a chassis is often less impactful as the control plane modules can be updated one at a time and line cards are often designed to be upgraded while in service without disruption.
- Physical redundancy – chassis based devices are modular and typically have more options for redundancy like power and fan modules.
- Throughput – when large amounts of throughput are needed, chassis based devices have more scalability in their internal backplanes where stacking has more limited throughput capabilities between switches.
However, chassis are not without drawbacks. Stacking has several advantages that are hard to overlook for WISP/FISP designs.
Stacking advantages
- Cost – stackable switches are typically orders of magnitude cheaper than getting a chassis with linecards for control plane, data plane and modules for power and fans
- Power – stacking is almost always more power efficient than a similarly sized chassis
- Space – stackable switches can consume as little as 2RU as compared to 4U or more for chassis based devices
- Environmental – chassis are often intended to be put into a climate-controlled DC, CO or enclosure and given that WISP/FISP peering points aren’t always inside a DC but at the base of a tower or other last mile location, getting equipment that is easier to manage heat/cooling is a significant contributing factor.
- Simplicity – stacking is much simpler than chassis-based operations because there are fewer elements to coordinate and upgrades, while service impacting, are typically much easier to perform.
Why not just get a used chassis off of ebay from Cisco/Juniper/Nokia?
This was a popular option when I first started working in the WISP field but has fallen out of favor for a few reasons:
- No hardware Support
- No software Support
- Security concerns with counterfeit and compromised equipment
- Cost rising due to equipment shortages
- Power draw
History of switch centric in WISP/FISP networking
2014 (Origin of the term)
The term switch-centric or SWC goes back to 2014 when we began to use switch stacks to overcome limited 10G ports in MikroTik routers like the CCR1036-8G2S+.
I coined and started using the term “switch centric” in consulting because it was easier (and slightly catchier) to explain to entrepreneurs and investors.
2015 (Use of Dell 8024F as a switching core)
The Dell 8024F was one of the first switches we used for stacking. It was inexpensive, readily available and software updates were free.

2016 (Technical drawing for WISPAPALOOZA)
In this version of the design, there are some notable differences with the current design. The first is the lack of L3 switching in the core switch stack. In 2016 and prior, there were fewer switch stacks that supported routing and were available at a price point similar to that of MikroTik routers.
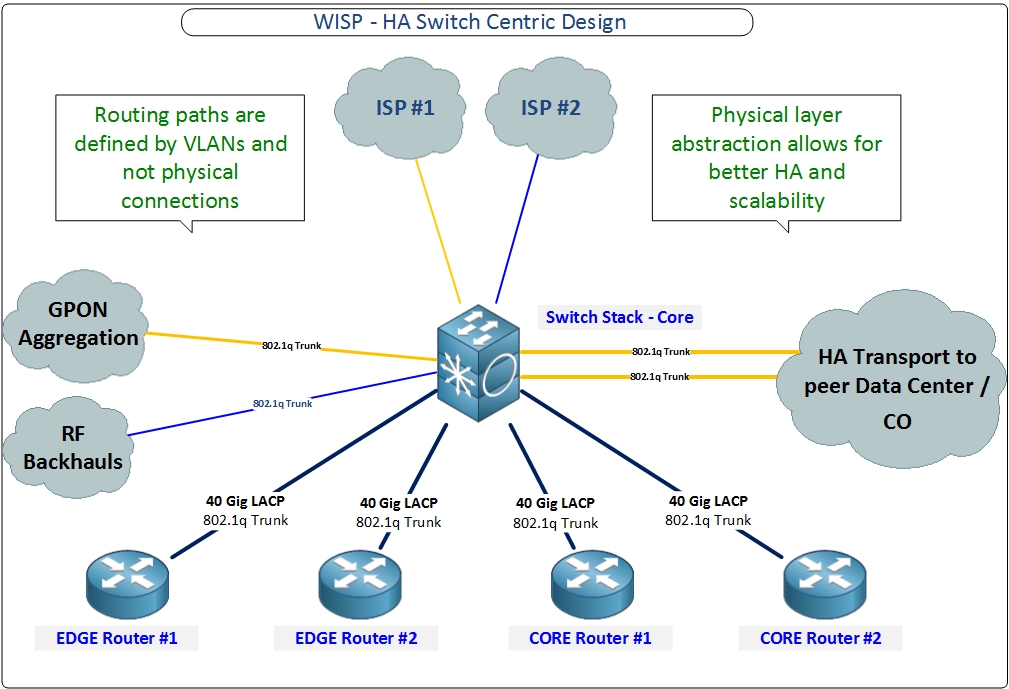
2017 to 2022 (Dell 4048-ON core and move to L3 switching)
The 4048 series was a step up from the 8024F as it has far better L3 capabilities and more ports. It was inexpensive and readily available until 2020 where the chip shortage started to affect supply.

2020 to now (FS 5860 series)
Fiber Store took a while to make a solid L3 stackable switch and we tried several models before the 5860 series with mixed results. However, the 5860 series has really become a staple in SWC design. It’s reliable and feature rich. It’s probably the best value in the market for a stackable switch.
Depending on the port density and speeds required, I currently use both models in SWC design.
FS5860-20SQ
20 x 10G, 4 x 25G, 2 x 40G

FS5860-48SC
48 x 10G, 8 x 100G

Switch Centric Design
The SWC design utilized today is the result of a decade of development and testing on hundreds of WISPs/FISPs in prod to fine tune and improve the design.
One of the design elements that grew with the SWC design is the idea of separation of network functions. It’s a network design philosophy that embraces the idea of modularity and simpler config by not using one or two devices to do everything.
I previously covered separation of network functions in a blog post if you want to go deeper into the topic.
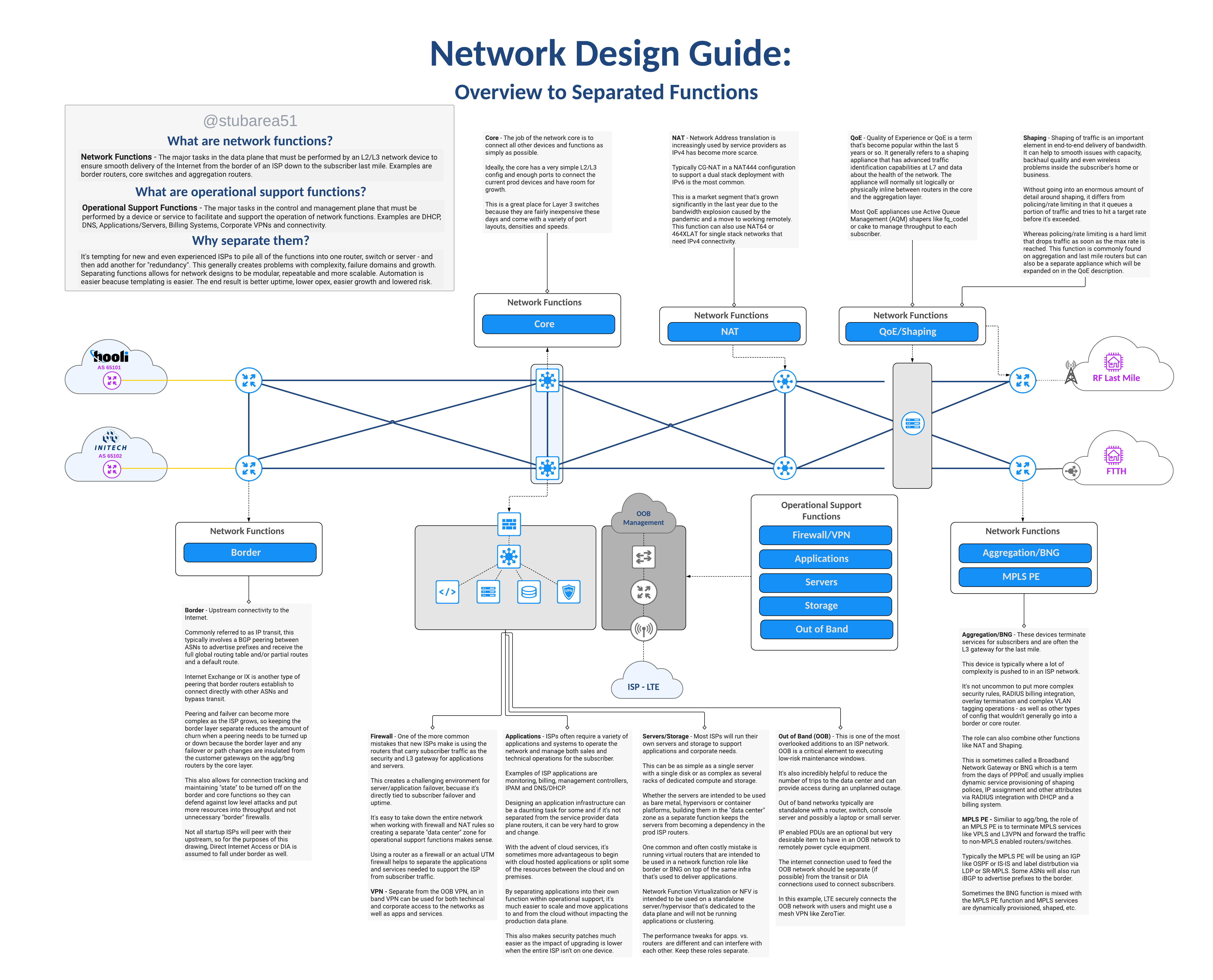
In reviewing the latest iteration of the SWC design, you’ll see the functions outlined and how they fit into the network.
The logical topology in the drawing illustrates how VLANs are used to define routed paths just like the router on a stick diagram from earlier in the article.
For simplicity, the logical drawing only shows one side of of the redundant design to simplify the concepts. This includes the first border router, switch stack and first agg router.
Benefits of SWC:
There are many benefits of SWC design and in my opinion, they far outweigh the tradeoffs for many WISPs/FISPs looking for economical hardware and flexible operations without sacrificing high-availability.
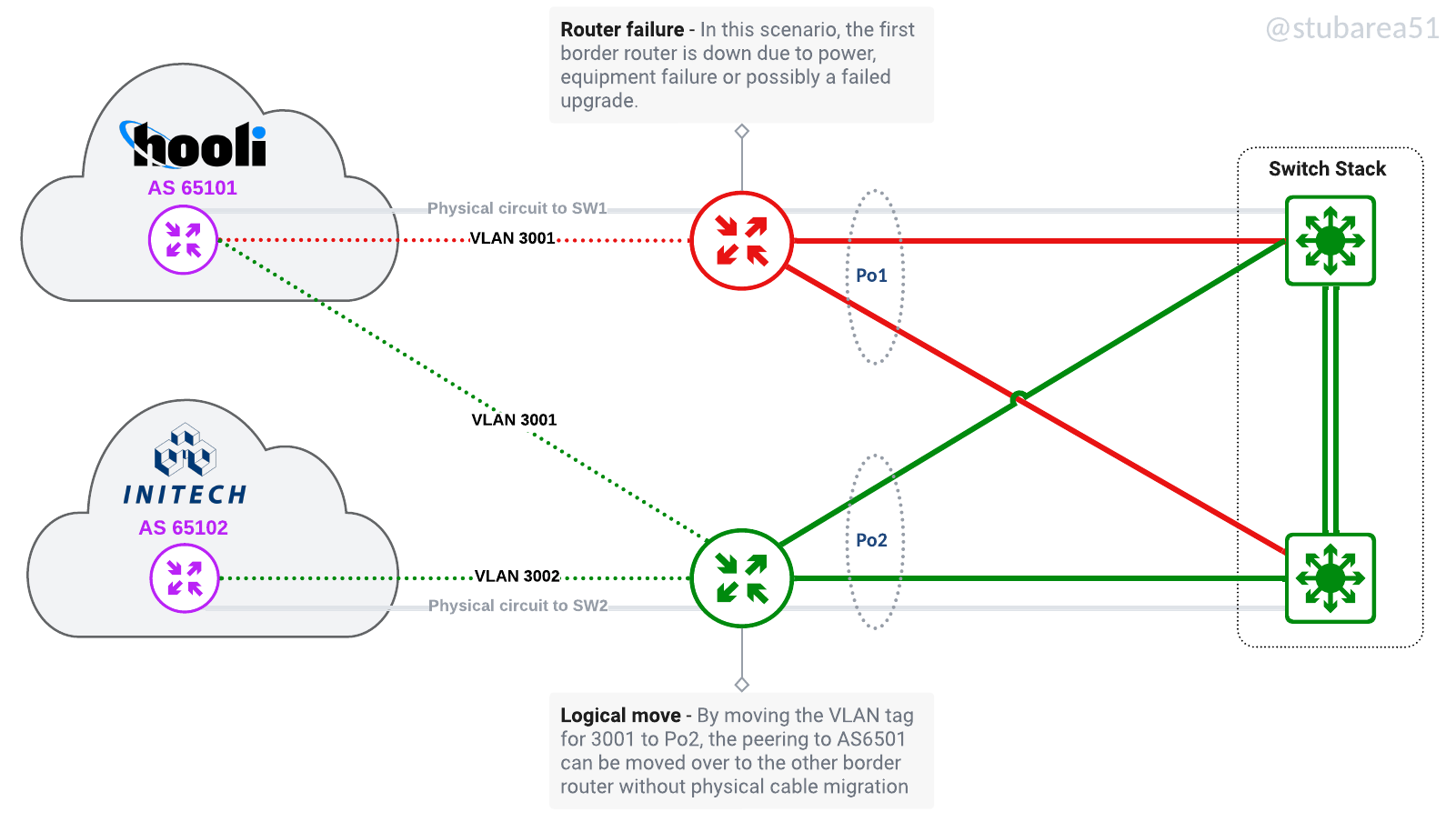
Logically move circuits.
Many WISPs/FISPs serve rural areas and backhaul their traffic to a data center that may be several hours away. The ability to move traffic off of a failed router and onto another remotely is a key advantage of the SWC design.
By moving the ptp VLAN for the transit or IX peering onto another router, the traffic can be restored in a matter of minutes vs. hours and doesn’t involve a physical trip to the DC.
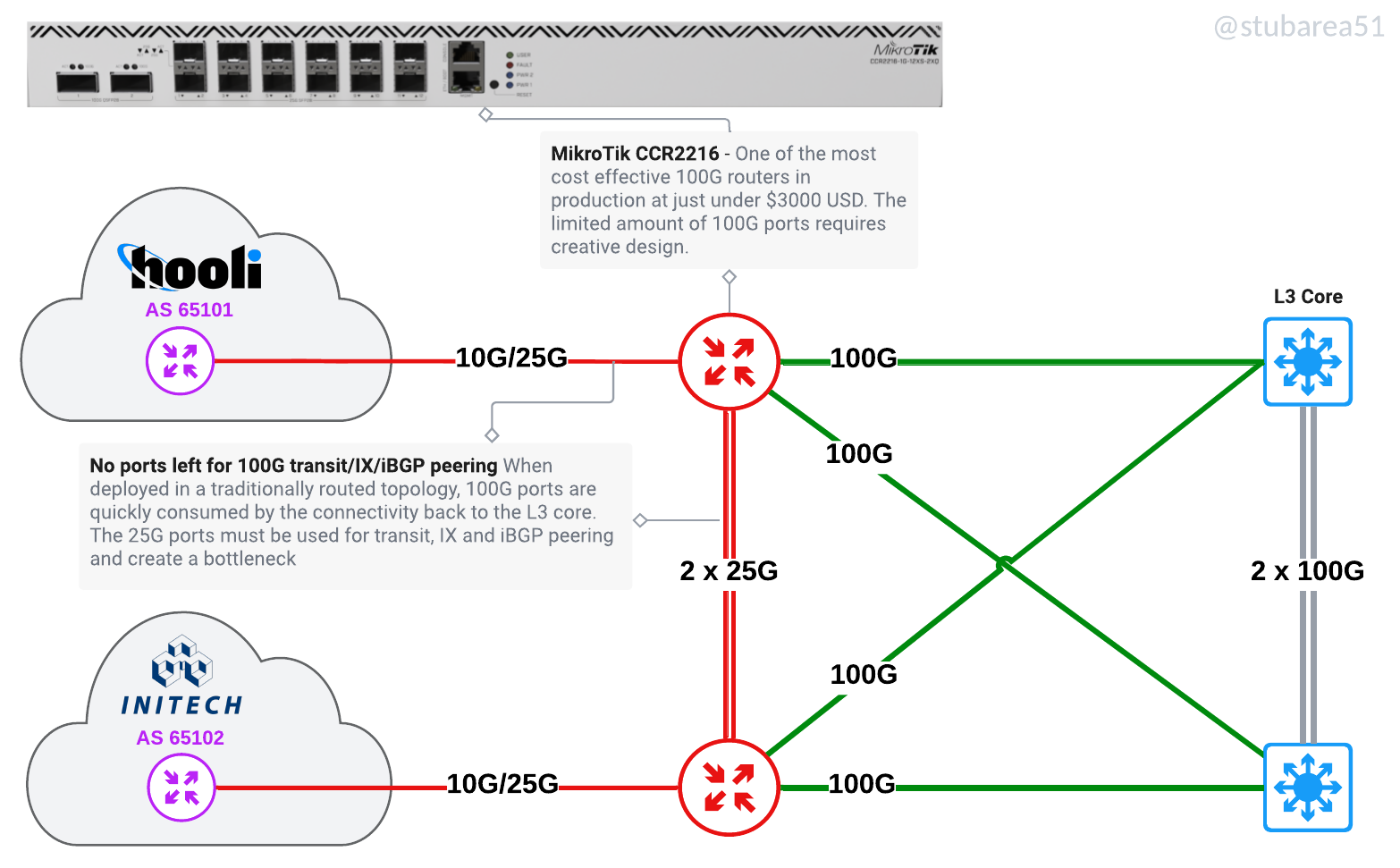
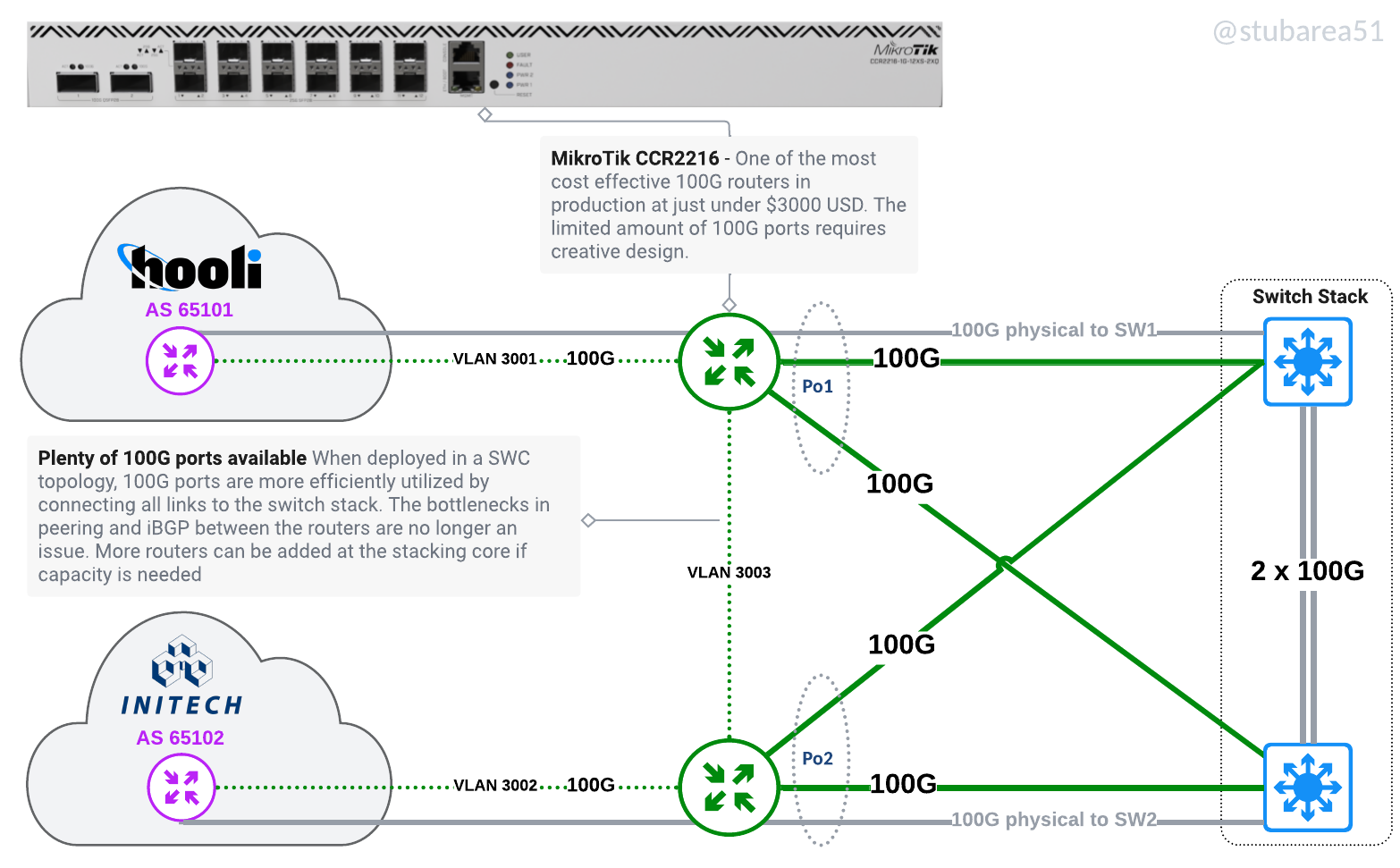
Better utilize routers with low density of 10G/25G/100G ports
One of the original drivers for the SWC design was adding port density for 10G by using the switch stack as a breakout. Now that inexpensive 100G routers are available, we have the same challenge with 100G as most of the more cost effective routers have very few 100G ports.
These are two of the routers I most commonly use when cost-effective 100G is required for peering or aggregation
MikroTik CCR2216-1G-12XS-2XQ (2 x 100G)

Juniper MX204 (4 x 100G)

The limitations of having a low 100G port count in a traditionally routed design.
The same routers in a SWC design
Adding or upgrading routers
Adding a new router or upgrading a router with a bigger one becomes simpler. It doesn’t impact production at all because you can setup an LACP channel from the new router to the switch and then configure it remotely when you’re ready. No need to keep moving physical connections around as each layer grows.
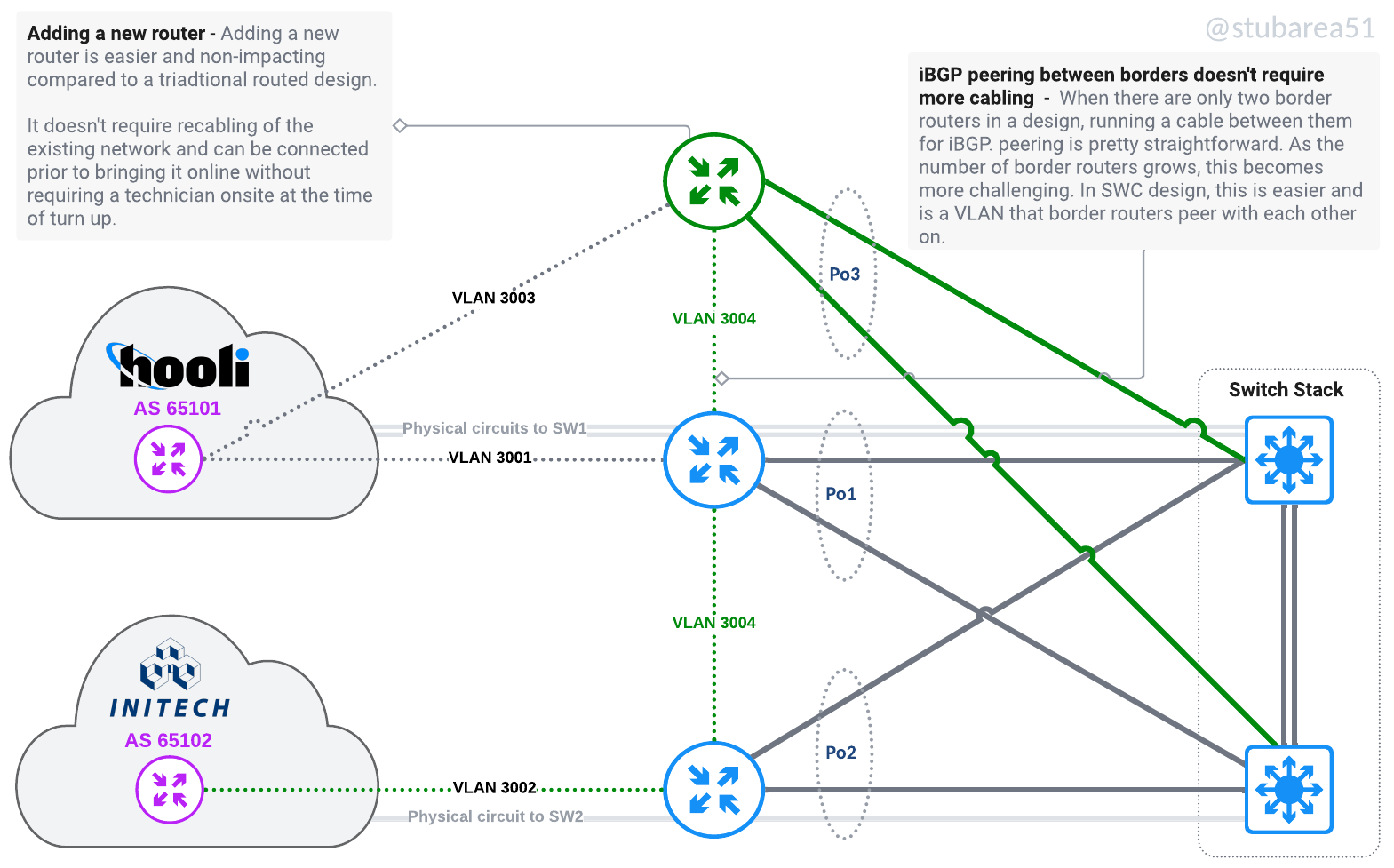
If a router is being replaced, config migration is also easier – because everything is tied to VLANs and the VLANs are tied to an LACP channel. Migrating a config with thousands of lines only requires 2 to 3 lines of changes – the physical ports that are LACP members.
Move workloads logically to efficiently use capacity
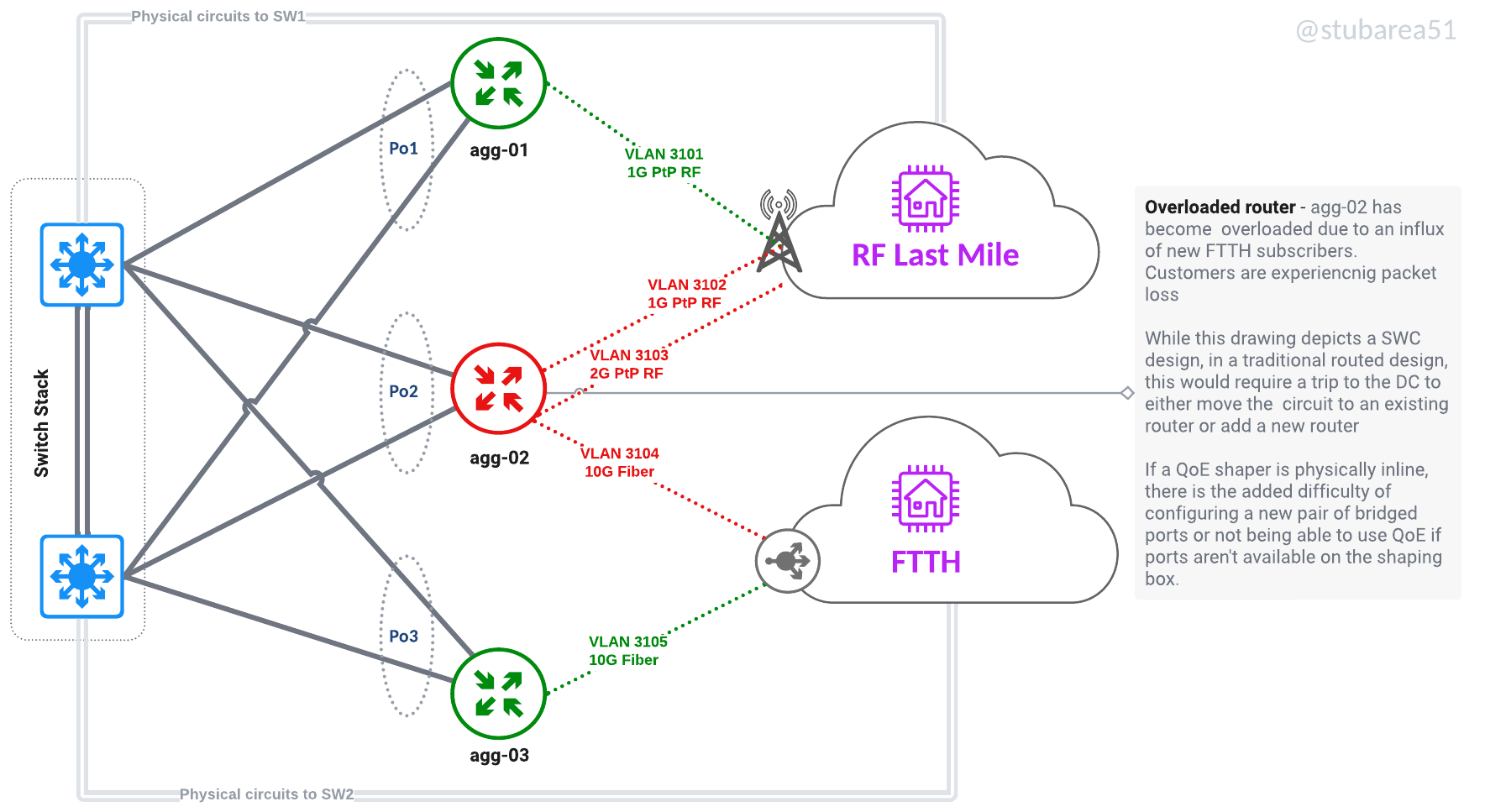
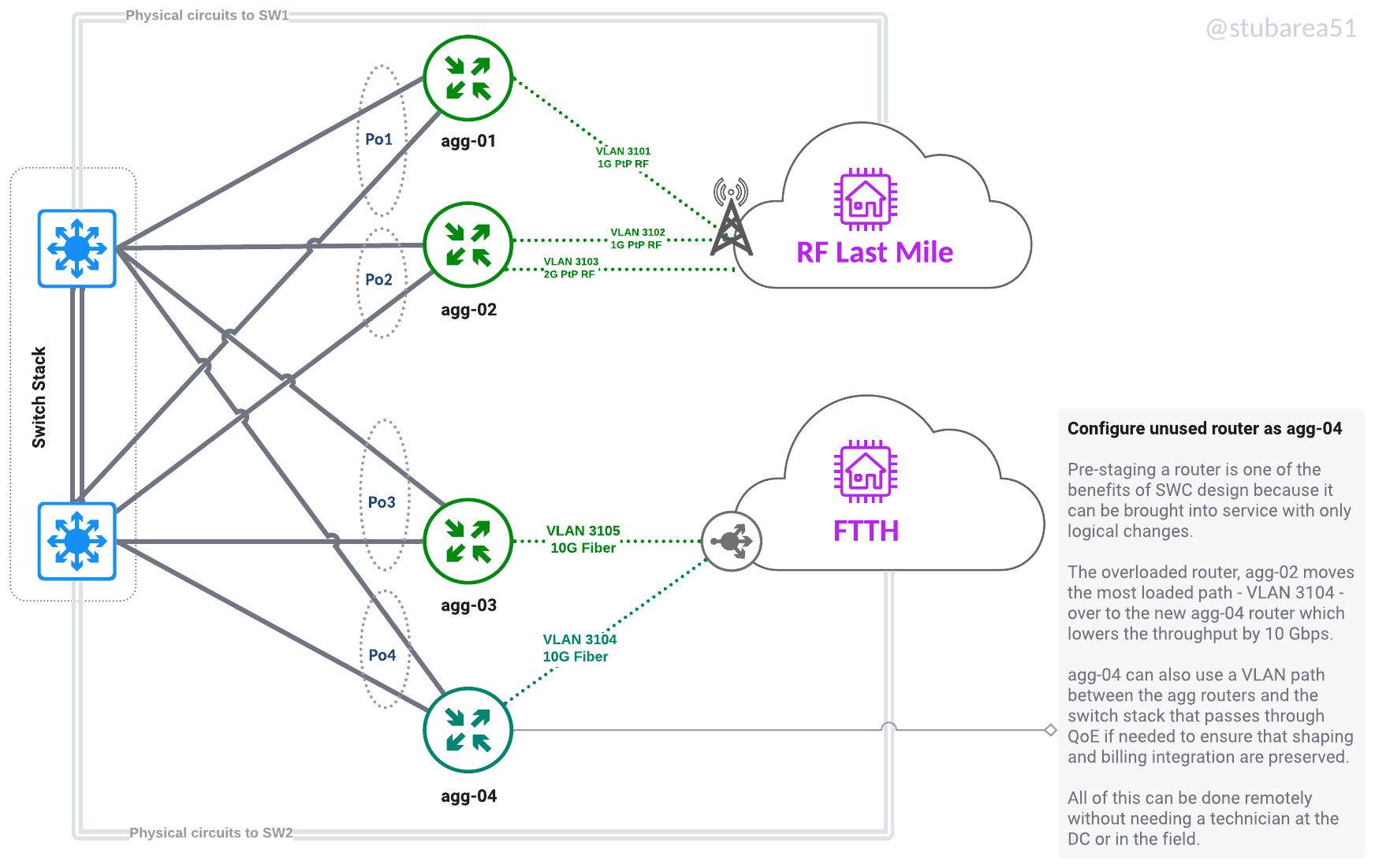
Move workloads between routers without recabling or even going onsite. Keep a spare router online and ready to replace a failed one. Move a router that is maxxed out to a different role like from border to VPN aggregator. Also moving last mile connectivity logically allows for aggregation capacity to be more efficiently spread across routers.
If a router is being replaced, config migration is also easier – because everything is tied to VLANs and the VLANs are tied to an LACP channel. Migrating a config with thousands of lines only requires 2 to 3 lines of changes – the physical ports that are LACP members.
Move workloads logically to efficiently use capacity
Move workloads between routers without recabling or even going onsite. Keep a spare router online and ready to replace a failed one. Move a router that is maxxed out to a different role like from border to VPN aggregator. Also moving last mile connectivity logically allows for aggregation capacity to be more efficiently spread across routers.
Security Appliances
Inserting security appliances and visibility in path is much easier because all traffic flows through the stack. This also allows the switch to drop attacks in hardware before it hits the border router if desired.
L2 inline appliance
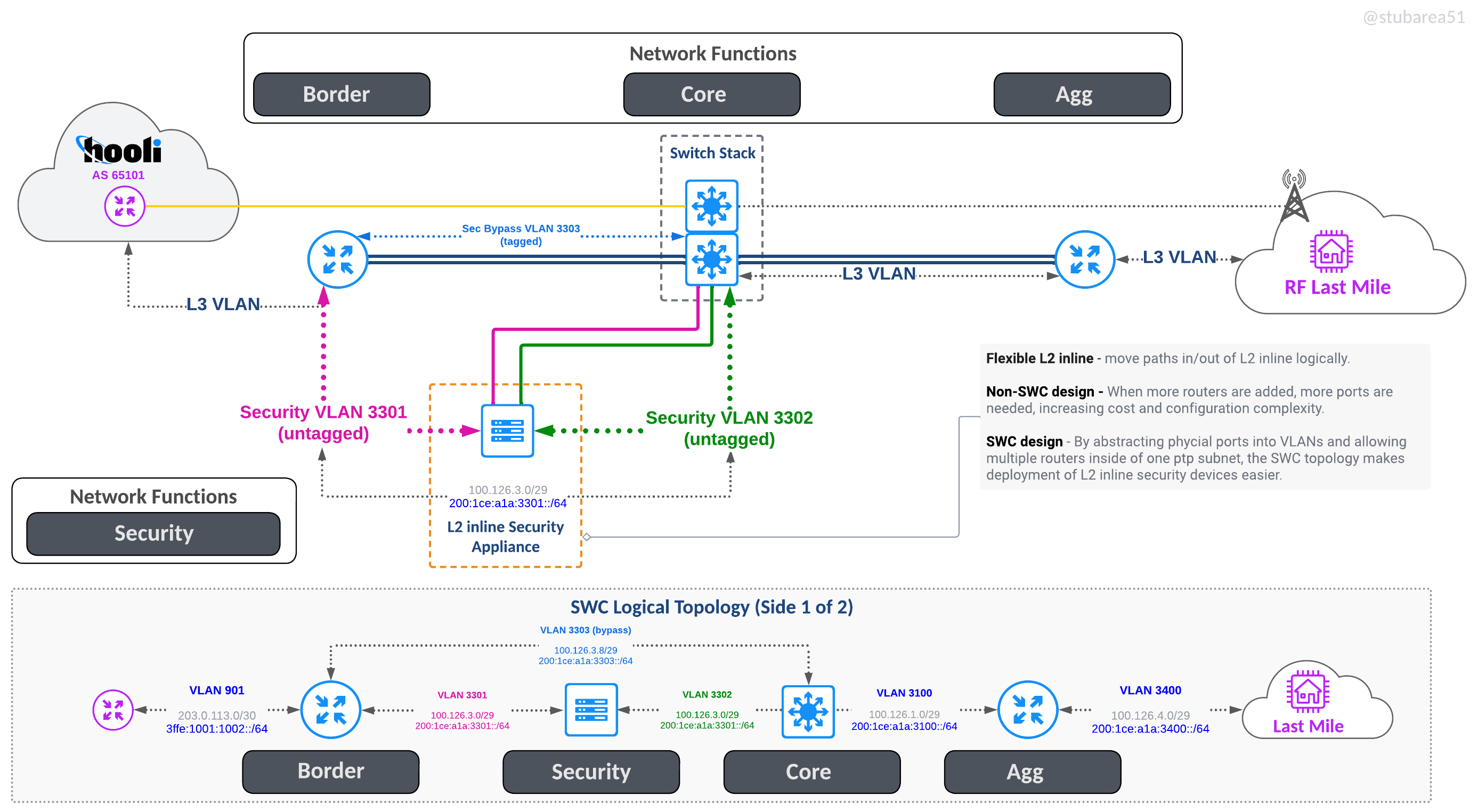
One Arm Off appliance
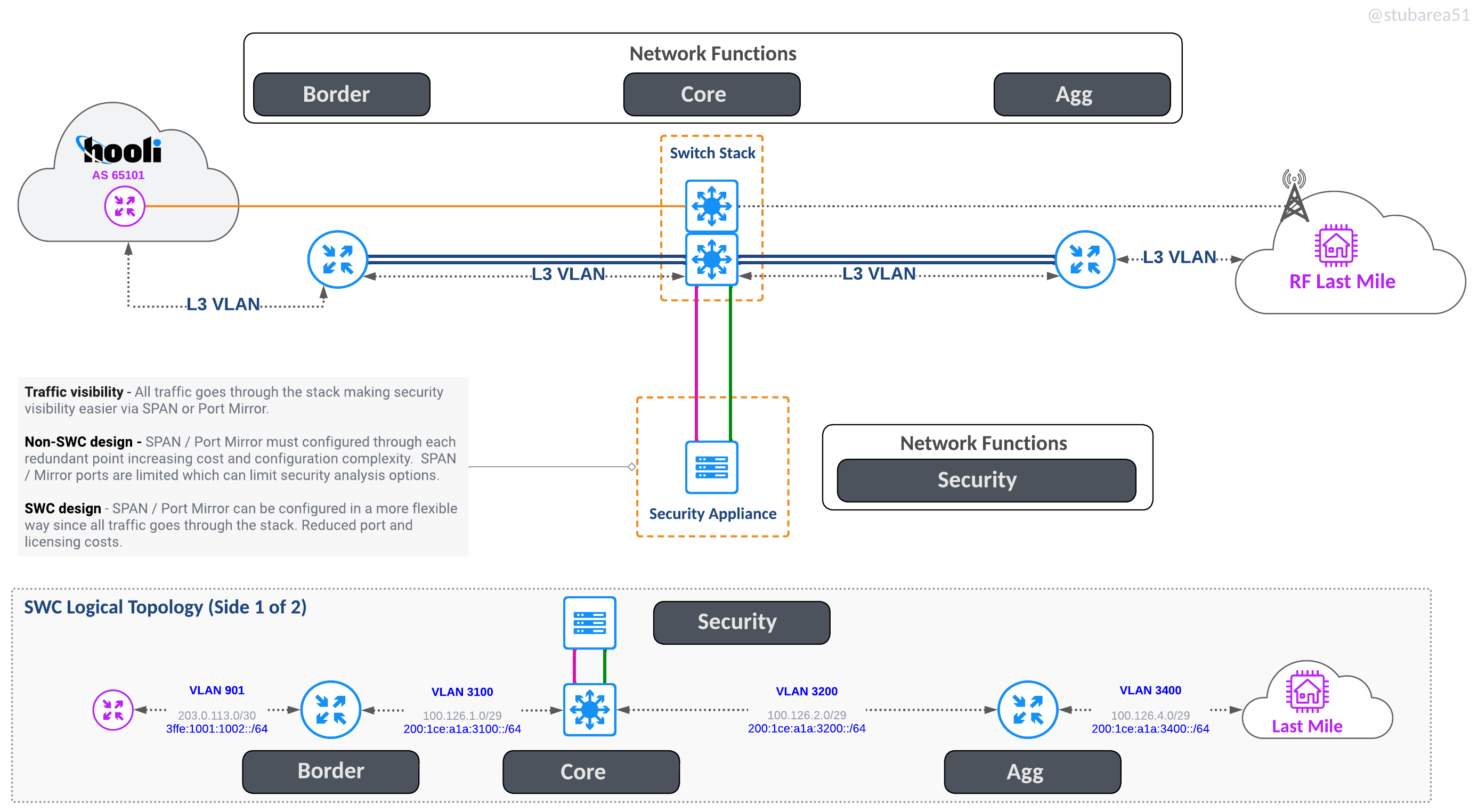
QoE
Inserting QoE is easier because you don’t have to worry about how many ports you need – just use 2 x 10G , 2 x 40G or 2 x 100G and hang it off the core stack with offset VLANs to force routing through it
QoE without NAT
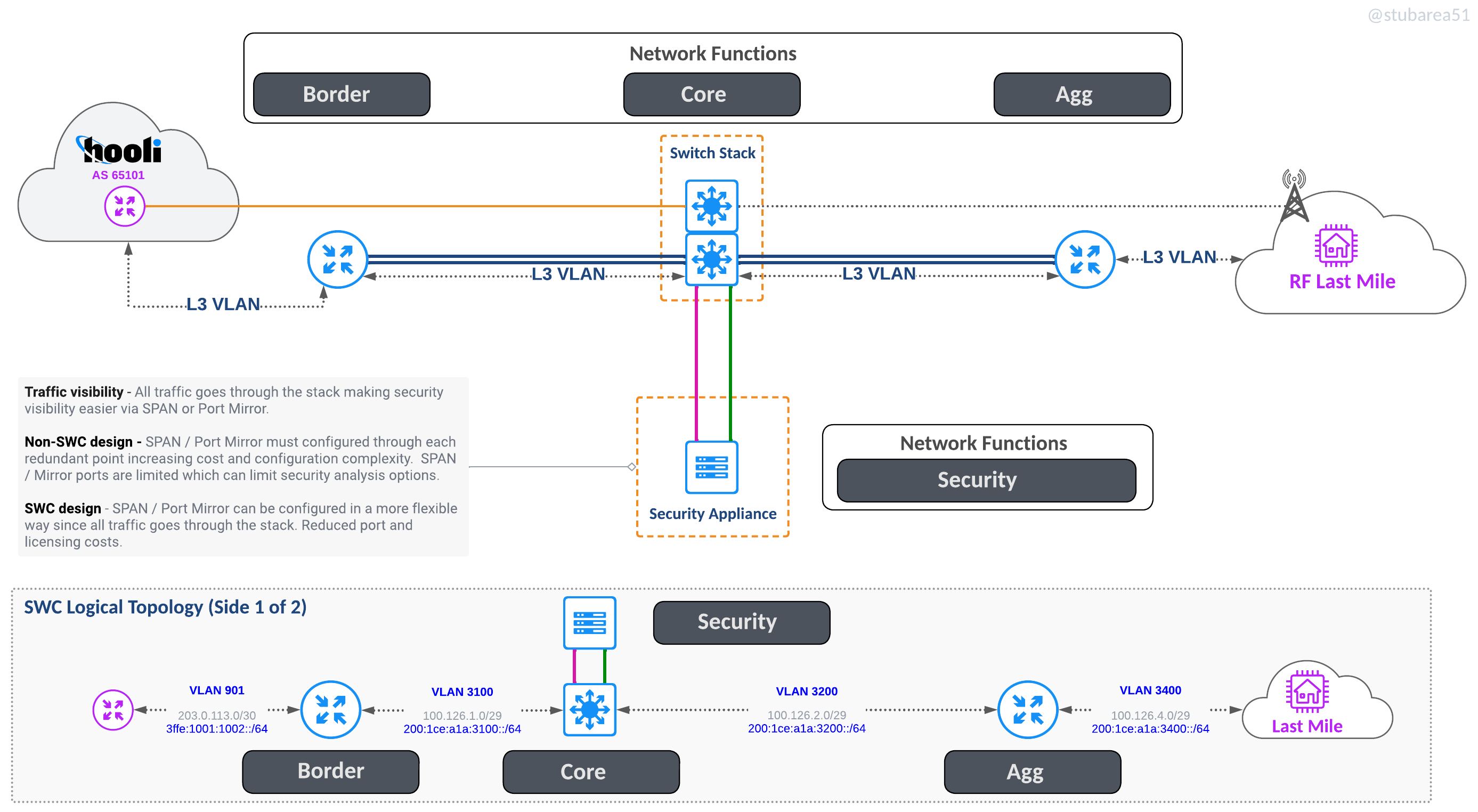
QoE with NAT
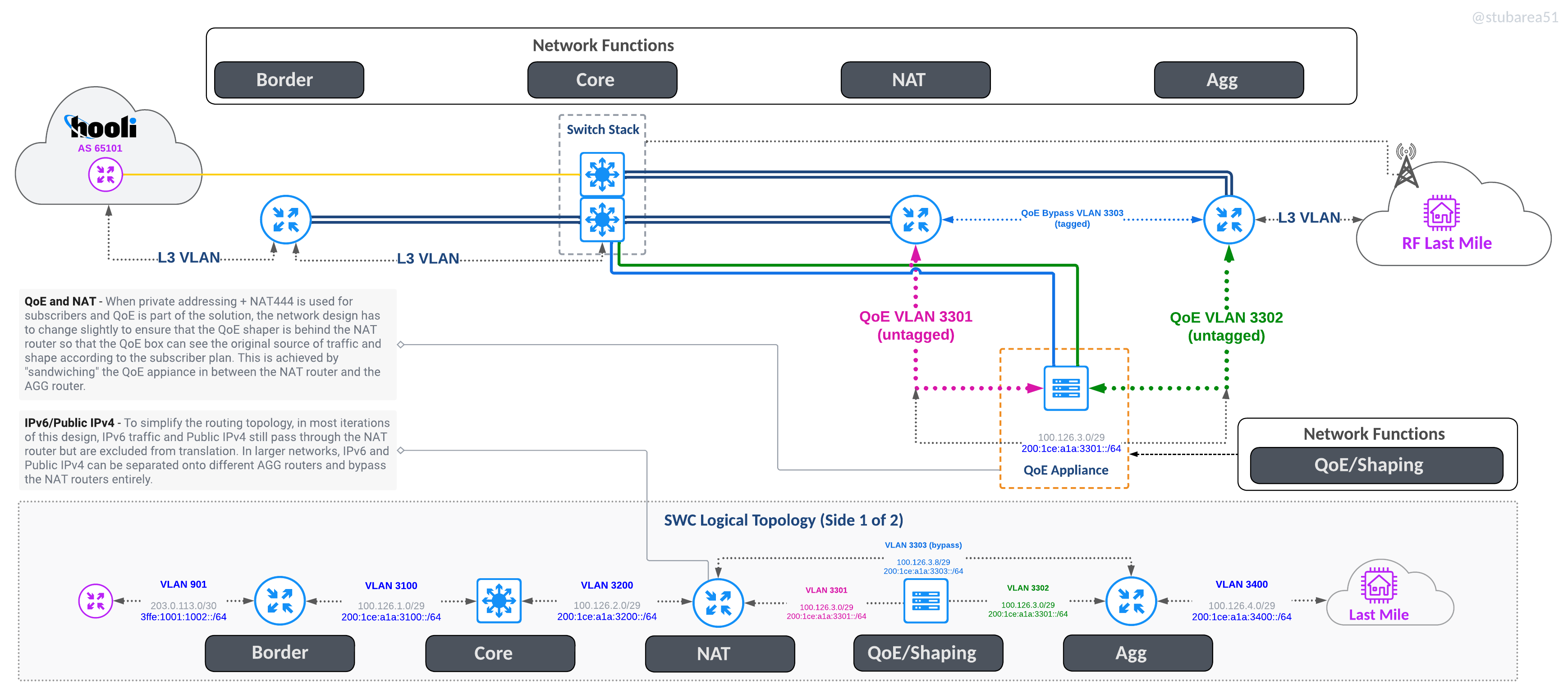
Other benefits
Simplified cabling – everything goes to the core switches in pairs except for single links like a transit circuit- Add link capacity without disruption or need to configure more routing. You can go from 2 x 10G to 4 x 10G LAG in a few minutes without having to add more PTP subnets, routing config and/or ECMP.
OPEX Value – start up and small ISPs derive a lot of value from being able to utilize a design that minimizes the “truck rolls” required to modify, extend and operate the network. The more logical changes can be made instead of physical, the more value the ISP is getting in OPEX savings.
Incremental HA – Defer the cost of a fully “HA” design by starting with (1) border router, (1) core switch and (1) agg router and then adding the redundant routers at a later time with minimal cabling challenges or disruption. Because the HA design is already planned for, it’s a pretty easy addition.
Unused / cold standby routers can be used for on-demand tasks like mirror port receiver for pcap analysis.
Why use a chassis or a stack at all – what about using small 1U/2U boxes in a routed design along with MPLS?
This is a good question and if you go back to the network topologies section, you’ll see that listed as one of the topologies because it’s a valid option.
SWC depends on abstraction of the physical layer which can also be accomplished using MPLS capable routers. Some of the more advanced MPLS overlay/HA technologies like EVPN multihoming are only available on much more expensive equipment although whitebox is starting to change that.
When selecting a design for a WISP/FISP, it really depends on a lot of different factors that are technical, financial and even geographic.
Consider these scenarios:
Urban FISP
A more Urban FISP that operates in smaller geographic area may not have the same cost to add cabling to a router instead of adding a VLAN in a SWC design. Going further, if they don’t use QoE or NAT and are selling only 1G residential Internet access, a purely routed design with MPLS could make sense.
Rural WISP
However, a rural WISP may have 100 times (or more) the geographic area to cover and the cost of sending a technician to a site to add cabling vs. adding a VLAN remotely could end up significantly raising OPEX when it’s done regularly. Add to that a need for QoE and the ability to add capacity remotely if the data center is several hours away – a common scenario in rural ISPs.
Remote WISP
In the most extreme example, some of the WISP/FISPs I work for operate in extremely remote locations like Alaska and may require a helicopter flight to add a cable or other physical move. The ability to make logical changes can be the difference between Internet or no Internet for weeks in a location like Alaska.
Where things get murkier is the cost of 100G ports for peering, SWC design saves quite a bit of money by using peering routers with low 100G port density but making the rest of the network SWC is challenging because very few 100G capable stacks exist.
This is why I came up with a “Hybrid SWC Design” where the peering edge is SWC and the rest of the network is routed with MPLS. It’s the best of both worlds and allows MPLS to provide the abstractions I’d otherwise use SWC for.
SWC Tradeoffs:
There are always tradeoffs when making design choices and SWC has tradeoffs and limitations like any other network deisgn.
– single control plane (vs dual control plane with MLAG)
– upgrade downtime
– traffic passes twice through the switching backplane (not as big of an issue in modern switches)
– harder to find stacking for 100G and beyond
– harder to find advanced features like MPLS if needed
For context, most of these tradeoffs are used as a reason to avoid stacking in large enterprise or carrier environments. But as with all things in network engineering, it depends.
What’s frequently overlooked in using stacking for WISPs/FISPs is the business value of a switch centric design compared to the network engineering trade-offs. Network engineers are quick to jump into the limitations of stacking but forget to consider the comparative value of the benefits to OPEX.
Where to put your money?
I put out a survey on the Facebook group WISP Talk in April 2023 to get an idea of how much WISPs/FISPs spent in year 1 for their total budget to include CAPEX and OPEX. While not perfect or likely scientifically accurate, it’s still pretty enlightening.
48 ISPs responded and the results are listed below:
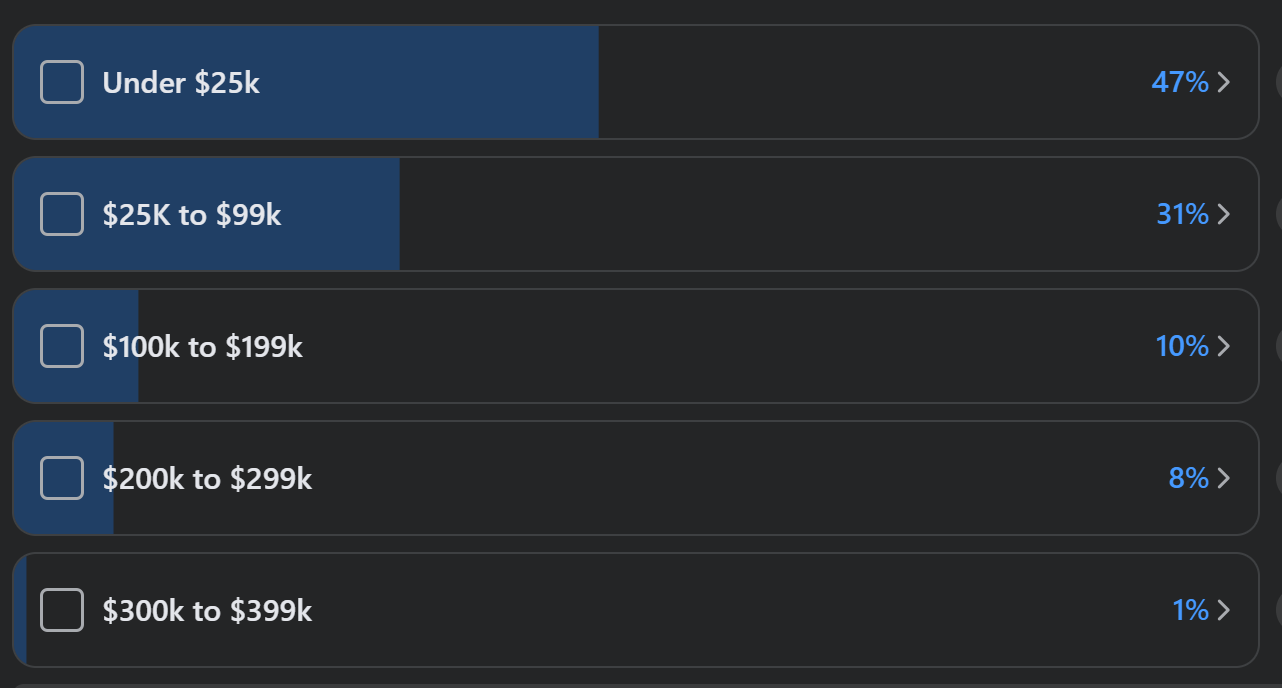
78% spent under $100k in year 1. That means equipment, services, tower leases, duct tape, etc all have to be accounted for.
It’s easy as a network geek to sit and argue for the merits of specific protocols, equipment and design as the “right way” to do something in network engineering.
It’s much harder to determine if that path is the “right way” at the right time for the business.
Since the context of this article is focused on WISPs and FISPs, getting a new chassis with support is very expensive. Even getting a new 1RU device from a mainstream vendor is expensive.
Fiber is becoming a part of most WISP deployments and is considered much more of an asset than what brand of network gear is being used.
It’s much easier, financially speaking, to buy different network gear in year 2 or 3 than to run new fiber over any distance so minimizing the cost of the network equipment is often a primary driver for new WISPs/FISPs in year 1.
This is where SWC design really shines – not only can it meet the budget target, it’s not going to require a drastic redesign in 12 months.
The most precious commodity startups have is often not money but time. Being able to avoid trips to the DC or remote sites is invaluable in small start-ups with one or two people. Even as the team grows, avoiding unnecessary trips can accumulate into significant cost savings over a year.
Assuming a $100K budget, if the network core and first tower/fiber cabinet can be kept to 10% or less of the total budget, that’s a win.
SWC Bill of Materials
$10,000 is unlikely to get a single router or switch from major vendors to say nothing of building out an entire DC and service location.
The core design below uses 4 MikroTik CCR 2116 routers and 2 FiberStore FS5860-20Q switches in a stack for a grand total of $7,178 at list price.
If the budget can’t support redundant devices for every function, there is also the option to just build the “A” side of the network with 1 border, 1 core switch and 1 aggregation router. The “B” side can be added later when budget permits.
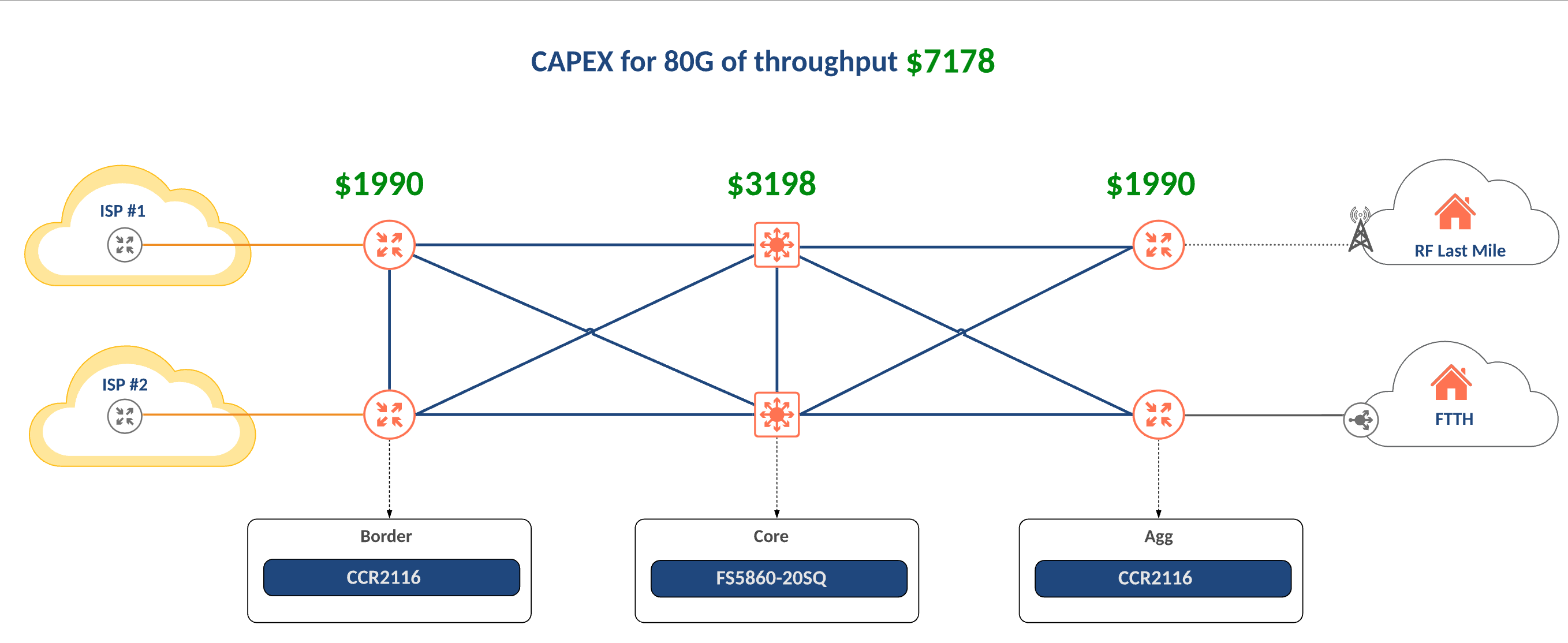
Conclusions
SWC is a great choice for many WISPs/FISPs and I’ve deployed hundreds of them in the last decade. It’s a mature, stable and scalable solution.
While it’s not the right choice for every network, it’s a solid foundation to consider and evaluate the tradeoffs as compared to other network topologies.
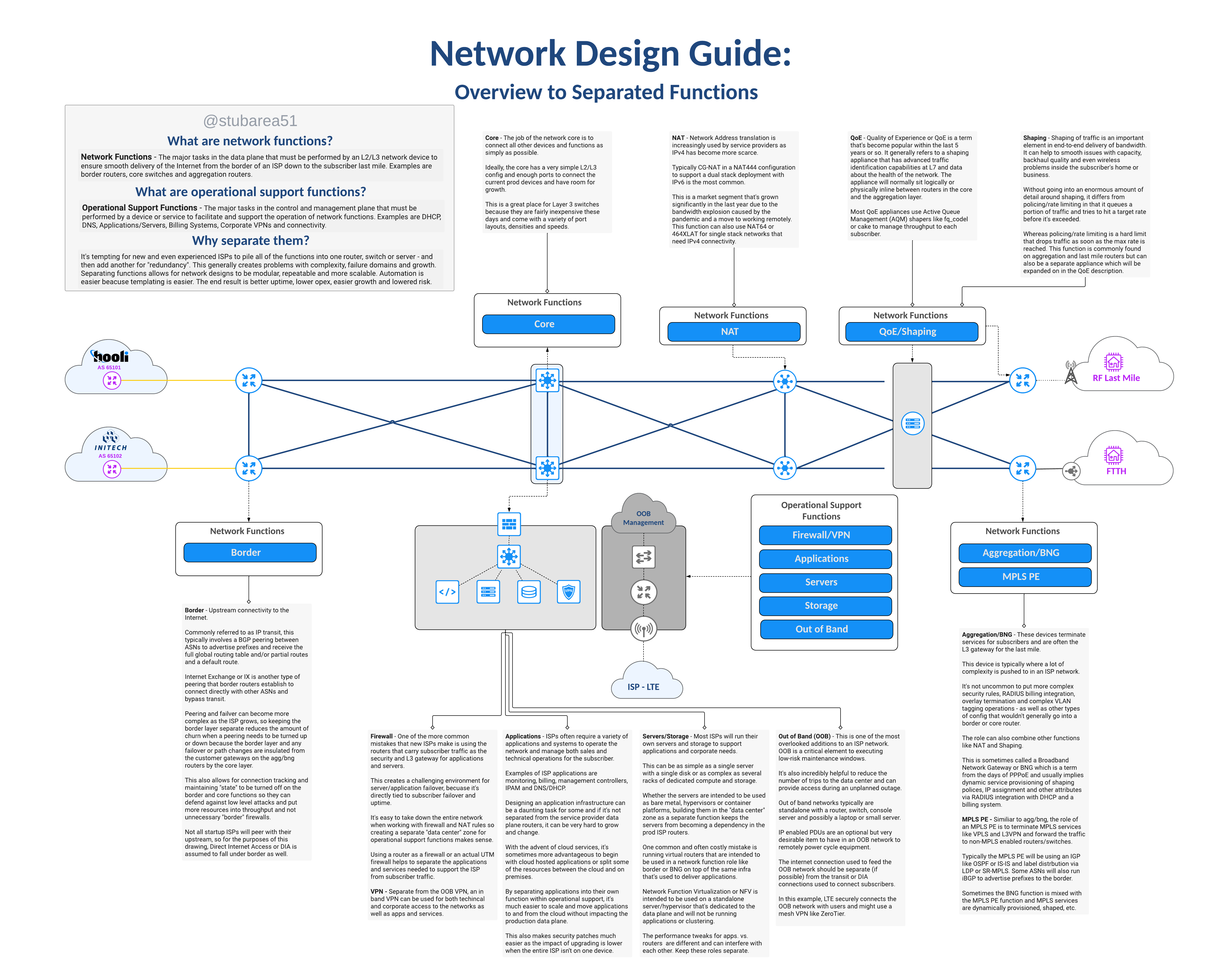
PDF link is here
A reference guide for new & existing ISPs that need to understand network functions and separation.
“How do I add redundancy?”
“How do I scale?”
“How do I reduce downtime and operational costs?”
These are questions that I get asked practically every day as a consulting network architect that designs and builds ISPs.
In most cases the answer is the same whether the ISP uses fixed wireless broadband, copper or fiber to deliver the last mile – separation of network functions.
This illustrated guide is intended to define the topic and create visual context for each function using a network drawing. It’s the first in a new series on this subject.
A new series of content
This topic is deep and there is a lot to unpack so this will be the first segment in a series of blog posts and videos covering function separation.
Large ISPs typically already embrace the philosophy of separating network functions, so the focus of this series will be to help new or growing regional ISPs understand the design intent and the challenges/costs of running networks that don’t separate network functions.
Overview
Routing filters have been a hot topic lately in the world of RouterOSv7. The first implementation of routing filters in ROSv7 was difficult to work with and documented in the two articles below:
MikroTik – RouterOSv7 first look – Dynamic routing with IPv6 and OSPFv3/BGP
MikroTik RouterOS – v7.0.3 stable (chateau) and status of general release
MikroTik then made some changes and opened up discussion to get feedback. I did a lot of work and testing using ROS 7.1beta7 which never made it to public release and was close to publishing the results when 7.1rc1 came out so this post will use that version.

RouterOSv7.1rc1 syntax example
Here is an example of the latest syntax in ROSv7.1rc1
CLI
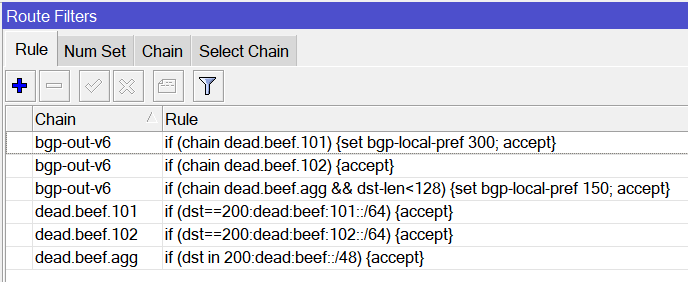
### MikroTik RouterOS 7.1rc1 ###
/routing filter rule
add chain=dead.beef.101 rule="if (dst==200:dead:beef:101::/64) {accept}"
add chain=dead.beef.102 rule="if (dst==200:dead:beef:102::/64) {accept}"
add chain=dead.beef.agg rule="if (dst in 200:dead:beef::/48) {accept}"
add chain=bgp-out-v6 rule="if (chain dead.beef.101) {set bgp-local-pref 300; accept}"
add chain=bgp-out-v6 rule="if (chain dead.beef.102) {accept}"
add chain=bgp-out-v6 rule="if (chain dead.beef.agg && dst-len<128) {set bgp-local-pref 150; accept}"Winbox
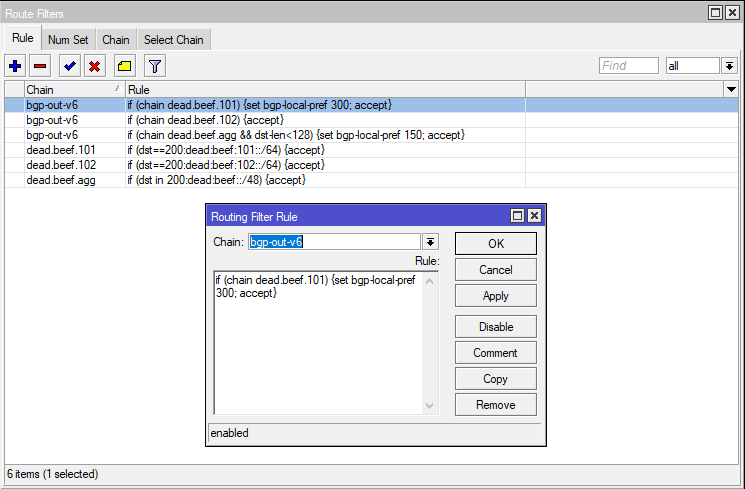
And the corresponding routes received (for the v7 filter rules)
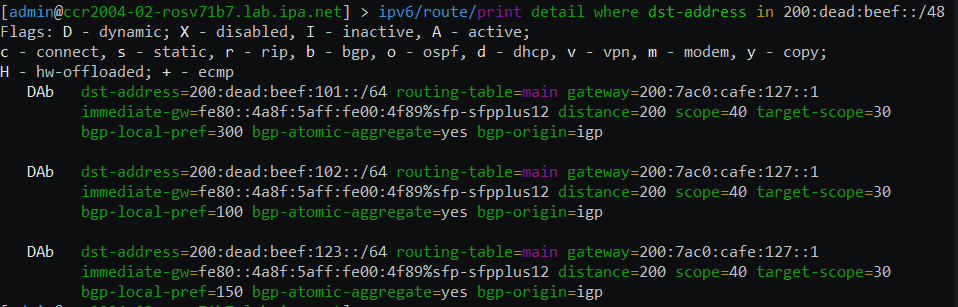
Comparable syntax in ROSv6 (note: recursive routing is not supported in IPv6 so the iBGP routes used to test v7rc1 would not be possible)
### MikroTik RouterOS 6.48.10 (long-term) ###
/routing filter
add action=accept chain=dead.beef.101 prefix=200:dead:beef:101::/64
add action=accept chain=dead.beef.102 prefix=200:dead:beef:102::/64
add action=accept chain=dead.beef.agg prefix=200:dead:beef::/48
add action=accept chain=bgp-out-v6 match-chain=dead.beef.101 set-bgp-local-pref=300
add action=accept chain=bgp-out-v6 match-chain=dead.beef.102
add action=accept chain=bgp-out-v6 match-chain=dead.beef.agg prefix-length=48-128 set-bgp-local-pref=150
Challenges and Feedback
- Coding vs. Network CLI – The single biggest resistance to the new style of filtering is the string format is hard to work with. It requires knowledge of the match and action statements as well as how to write an expression to correctly parse them. Network engineers are not software engineers and route filtering (much like firewalling) has the capacity to be complex and require many lines of config – which means the format should align with v6 route filters and/or firewall rules.
- Tab complete – The lack of tab complete is a big gap. Network engineers, admins and technicians expect to be able to tab complete when creating a config. This is rumored to be in the works and hopefully it will make it into later release candidates.
- Using context sensitive help with “?” – There are a couple issues with context sensitive help in ROS 7.1rc1. The first issue is using the F1 key for help in any part of ROSv7 (not just filtering) instead of the ‘?’. This should at least be an option that can be set.
The second issue is the lack of context sensitive help for the routing filters – if an engineer is unsure of the syntax, it’s currently not possible to get help from the command line.
This has been a fundamental part of CLI based network operating systems for over 30 years. It needs to be added back.
Conclusions
One thing is clear, everyone I discussed it with on Facebook, Reddit, MikroTik Forums and with clients and engineers on my team did not like the new format.
It’s worth noting that MikroTik equipment is often used in remote locations where it isn’t practical to pull up the help docs and engineers in the field rely on the ability to use tab-complete and context sensitive help to finish configuration tasks. This is a critical feature for a network operating system to have.
To MikroTik – please consider implementing the filters so that at a minimum, the features in ROSv6 (like tab-complete, context sensitive help and a non-coding syntax) are maintained while allowing for new functionality.
Examples of filtering in other well-known operating systems
Here are some examples of the same filtering rules in different network operating systems for comparison. All of them support tab-complete and context sensitive help.
Free Range Routing is probably one of my favorites because it’s open and is being actively developed. JunOS is very popular from a filtering standpoint because the OS is easy to work with programatically.
Cisco is included because they are pervasive but isn’t at the top of my list because the syntax isn’t anything special and IOS-XR equipment tends to be incredibly expensive even though bugs are still commonplace – so it’s not a great value.

Free Range Routing (https://frrouting.org)
### Free Range Routing v6.0.2 ###
ipv6 prefix-list dead.beef.101 seq 10 permit 200:dead:beef:101::/64
ipv6 prefix-list dead.beef.102 seq 10 permit 200:dead:beef:102::/64
ipv6 prefix-list dead.beef.agg seq 10 permit 200:dead:beef::/48 le 128
!
route-map bgp-out-v6 permit 10
match ipv6 address prefix-list dead.beef.101
set local-preference 300
!
route-map bgp-out-v6 permit 20
match ipv6 address prefix-list dead.beef.102
!
route-map bgp-out-v6 permit 30
match ipv6 address prefix-list dead.beef.agg
set local-preference 150
### Free Range Routing v6.x ###!Juniper Networks JunOS (https://junipernetworks.com)
### Juniper JunOS 18.x ###
policy-options {
prefix-list dead.beef.101 {
200:dead:beef:101::/64;
}
prefix-list dead.beef.102 {
200:dead:beef:102::/64;
}
prefix-list dead.beef.agg {
200:dead:beef::/48;
}
policy-statement bgp-out-v6 {
term dead.beef.101 {
from {
prefix-list dead.beef.101;
}
then {
local-preference 300;
accept;
}
}
term dead.beef.102 {
from {
prefix-list dead.beef.102;
}
then accept;
}
term dead.beef.agg {
from {
prefix-list-filter dead.beef.agg orlonger;
}
then {
local-preference 150;
accept;
}
}
}
}Cisco Networks IOS XR (https://cisco.com)
### Cisco IOS-XR x.x ###
prefix-set dead.beef.101
200:dead:beef:101::/64
end-set
!
prefix-set dead.beef.102
200:dead:beef:102::/64
end-set
!
prefix-set dead.beef.agg
200:dead:beef::/48 le 128
end-set
!
route-policy bgp-out-v6
if destination in dead.beef.101 then
set local-preference 300
pass
elseif destination in dead.beef.102 then
pass
elseif destination in dead.beef.agg then
set local-preference 150
pass
endif
end-policy
If you don’t already use it, the MIkroTik v7 BETA forum (forum.mikrotik.com) is a fantastic source of information
When will stable be released?
This is the million dollar question. Technically, it already has been for one hardware platform…
!! Spoiler Alert – There is *already* a stable release of ROSv7 – v7.0.3!!
The Chateau 5G router originally shipped with a beta version of ROSv7 but was quietly moved to a stable version that’s developed specifically for that platform.

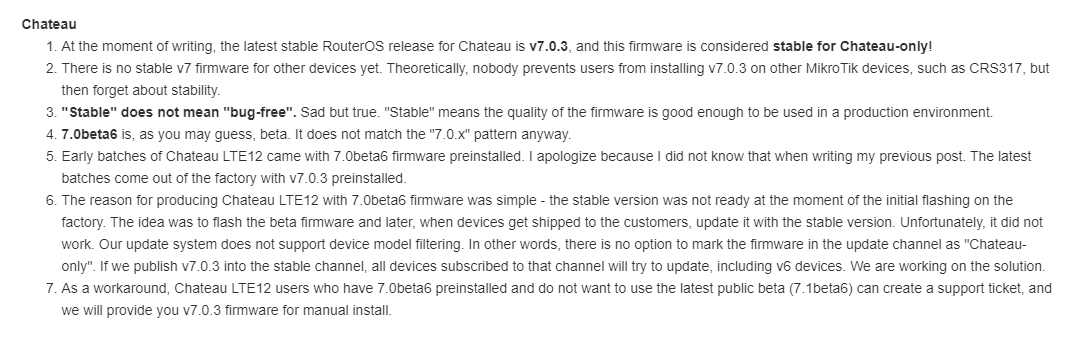
Because of the way MikroTik’s code repo works, this version can’t easily be added to the main download page and support provides the software:
ROSv7.0.3 Stable Download (!!! Chateau Only – will brick other hardware !!!)
https://box.mikrotik.com/f/7e3cad5779804d0b878d/?dl=1
It’s worth repeating MikroTik’s warning about using this on any platform other than the Chateau

What’s holding up v7 from being released?
If you’ve been around MikroTik for a while, then you know that version 7 has been in the works for a long time to add new functionality and address limitations of the older Linux kernel in ROSv6.
MikroTik recently added a detailed update on where the development roadmap is at and what the challenges are:
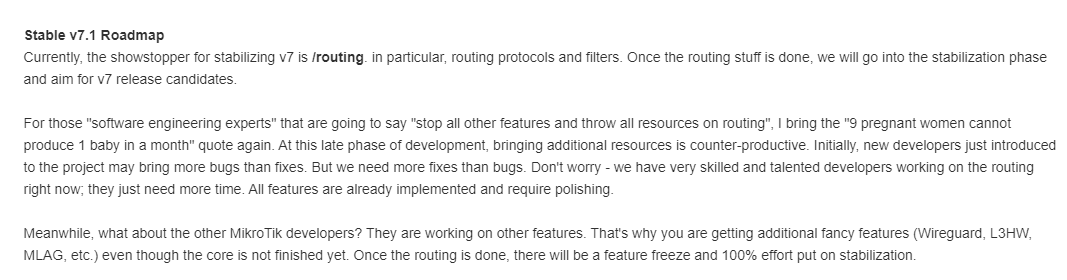
What does this mean?
- Routing filters need to be rewritten to simplify the syntax and operation – there were a lot of complaints with the original syntax.
- Routing protocols like OSPF and BGP have been unstable in beta1 through beta6 and need some work to stabilize them.
What’s the issue with routing filters?
The original v7 routing filters were very complicated to work with and had esoteric terms for operations like ‘subsumes’ and required ‘rule’ and ‘select-rule’ config to actually reference the filter in the routing process.
Previous filter syntax:

I wrote an article in late 2020 on IPv6 with BGP/OSPF using beta2 and captured a few screenshots that aren’t in the online docs anymore.
More details are in the article here:
MikroTik – RouterOSv7 first look – Dynamic routing with IPv6 and OSPFv3/BGP – StubArea51.net
New syntax?
If the current filter documentation represents the newer style, there are several differences in the format. The more complicated language like ‘subsumes’ is gone and only one filter rule is required to use the filter in the routing process – the ‘select-rule’ syntax is gone.

The new filter syntax appears to have made it onto help.mikrotik.com under /routing/filter but this may change in the coming weeks.
Example:
Similar to the OSPF example above, this is the example listed under the filter section for the new format.

The options below represent the matching order and the possible readable and set parameters.
Accepted Syntax:
if ( [matchers] ) { [actions] } else { [actions] }
[matchers]:
[prop readable] [bool operator] [prop readable]
[actions]:
[action] [prop writeable] [value]
Accepted parameters:
[num prop readable]
dst-len
bgp-path-len
bgp-input-local-as
bgp-input-remote-as
bgp-output-local-as
bgp-output-remote-as
ospf-metric
ospf-tag
rip-metric
rip-tag
[num prop writable]
distance
scope
scope-target
bgp-weigth
bgp-med
bgp-out-med
bgp-local-pref
bgp-igp-metric
bgp-path-peer-prepend
bgp-path-prepend
ospf-ext-metric
ospf-ext-tag
rip-ext-metric
rip-ext-tag
[flag prop readable]
active
bgp-attomic-aggregate
bgp-communities-empty
bgp-communities-ext-empty
bgp-communities-large-empty
bgp-network
ospf-dn
[flag prop writable]
ospf-ext-dn
blackhole
use-te-nexthop
[predicate]
bgp-communities|bgp-communities-ext|bgp-communities-large
equal|any|includes|subset
{inline set}
equal-set|any-set|includes-set|subset-set
{set name}
any-regexp|subset-regexp
{regexp}
comment
text|find|regexp
{string}
chain
{chain name}
vrf
{vrf}
rtab
{rtab}
gw-interface
{interface}
gw-check
none|arp|icmp|bfd|bfd-mh
afi
ipv4|ipv6|l2vpn|l2vpn-cisco|vpnv4|vpnv6
,...
protocol
connected|static|bgp|ospf|rip|dhcp|fantasy|modem|vpn
,...
bpg-origin
igp|egp|incomplete
,...
bgp-as-path
{regexp}
rpki
valid|invalid|unknown
ospf-type
intra|inter|ext1|ext2|nssa1|nssa2
ospf-ext-type
type1|type2
[num prop readable]
in
{int..int}|{int-int}
==|!=|<=|>=|<|>
{int}
[prfx prop readable]
!=|==|in
{address 46/}
[flag prop readable]
[block]
if ([predicate] &&/|| ...) { [block] } [ else {[block]} ]
accept|reject|return
jump {chain name}
unset
pref-src|bgp-med|bgp-out-med|bgp-local-pref
bgp-communities|bgp-communities-ext|bgp-communities-large
append|replace|filter-in|filter-not-in
{inline community set}
append-set|replace-set|filter-in-set|filter-not-in-set
{set name}
filter-in-regexp|filter-not-in-regexp
{regexp}
delete
wk|other <-- for communities
,...
rt|soo|other <-- for ext-communities
,...
all <-- for large-communities
rpki-verify
{rpki group name}
comment
set|append
{string}
set
[num prop writable]
[num prop readable]|[num prop writable]
+/-
[num prop readable]|[num prop writable]
gw
interface
{interface}
{address 46i}
gw-check
none|arp|icmp|bfd|bfd-mh
pref-src
{address 46}
bgp-origin
igp|egp|incomplete
ospf-ext-fwd
{address 46}
ospf-ext-type
type1|type2
[num prop readable]
in
{int..int}|{int-int}
==|!=|<=|>=|<|>
{int}
[num prop readable]What are the problems with routing protocols?
The routing stack has been completely re-written for ROSv7 from what we are told. This takes some time.
When I was last out in Silicon Valley, I met with a company that just emerged from stealth and had designed a new Network OS. They spent 3 years in stealth working on nothing but the OS with no actual product being sold – just coding and development.
So it’s not surprising this process has taken a while.
Stabilizing protocol issues
There are a number of bugs we’ve seen in the early versions of ROSv7 beta for routing protocols that are being worked through. Things like OSPF checksum, interface templates, high cpu when areas are disabled/enabled….etc.
Now that we know routing protocols are a priority and the new filter syntax is taking shape, I would expect to see some improvement across the next 2 to 3 beta releases to get routing protocols stable with simple configs.
L3 Switching
From talking to a lot of people that write code for Network OSes and work on the interaction with the ASIC, this is one of the hardest areas to get right – pushing routes from the RIB down into the HW FIB.
MikroTik hired new developers to meet this challenge:

MikroTik has updated the L3 HW doc pages to provide a roadmap of features and functionality for the beta series.
It appears that Jumbo MTU is the next major feature to be added for L3 HW in ROSv7.1beta7
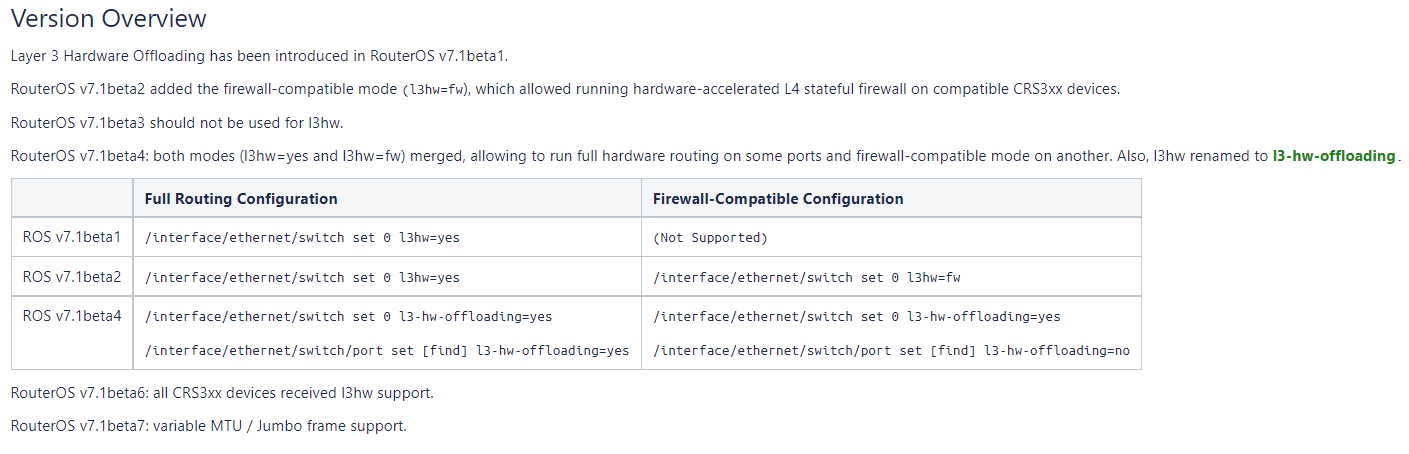
When will ROSv7 move to release candidate and then stable?
When asked about the state of ROSv7, my typical answer has been that we’ll see a stable version in mid 2022 based on the pace of development.
I think that’s still a fair answer based on the pace of development.
It seems like the routing protocols and filters we need a few more beta versions to get working and then they’ll move to release candidates – my estimate is to look for the RCs towards the end of 2021.
Hopefully this has been helpful…i’ll probably write another summary on the state of ROSv7 once more progress has been made.
In the world of network engineering, learning a new syntax for a NOS can be daunting if you need a specific config quickly. Juniper is a popular option for service providers/data centers and is widely deployed across the world.
This is a continuation of the Rosetta stone for network operating systems series. In this article we will be covering multi-protocol label switching (MPLS) using label distribution protocol (LDP). We are sticking with LDP as MikroTik does not have wide support for RSVP-TE.
You can find the first two articles of the series here:
Juniper to MikroTik – BGP commands
Juniper to MikroTik – OSPF commands
While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
Using EVE-NG for testing
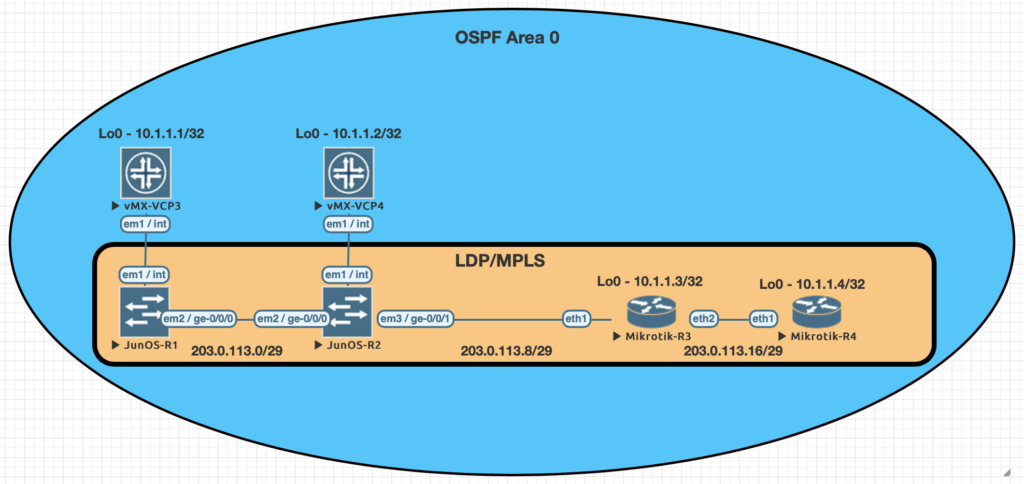
We conducted utilized EVE-NG for all of the testing with the topology seen below.
| Juniper Command | MikroTik Command |
|---|---|
| show ldp neighbor | mpls ldp neighbor print |
| show ldp interface | mpls ldp interface print |
| show route forwarding-table family mpls | mpls forwarding-table print |
| show ldp database | mpls remote-bindings print |
| show ldp database | mpls local-bindings print |
| show mpls label usage | mpls print |
| set interfaces ge-0/0/0 unit 0 family mpls set protocols ldp interface ge-0/0/0.0 | /mpls ldp interface add interface=ether1 |
| set routing-options router-id 10.1.1.1 | /mpls ldp set enabled=yes lsr-id=10.1.1.3 |
Examples of the commands above
This first command will show you some basic information about your MPLS LDP neighbors. On juniper you can add the keyword detail to the end for additional information on the neighbors.
[admin@MikroTik-R3] > mpls ldp neighbor print

root@JUNOS-R2> show ldp neighbor

This command will list all of the interfaces that are currently enabled for LDP.
[admin@MikroTik-R3] > mpls ldp interface print

root@JUNOS-R2> show ldp interface

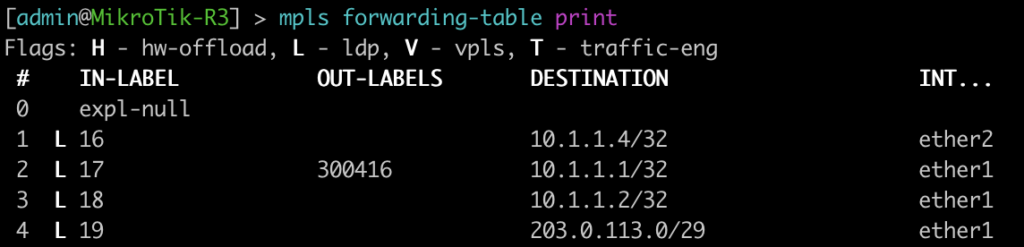
Use this command to display the MPLS forwarding table which shows what labels are assigned, the interface used and the next-hop. It will also tell you the action taken such as pop, swap, or push.
[admin@MikroTik-R3] > mpls forwarding-table print
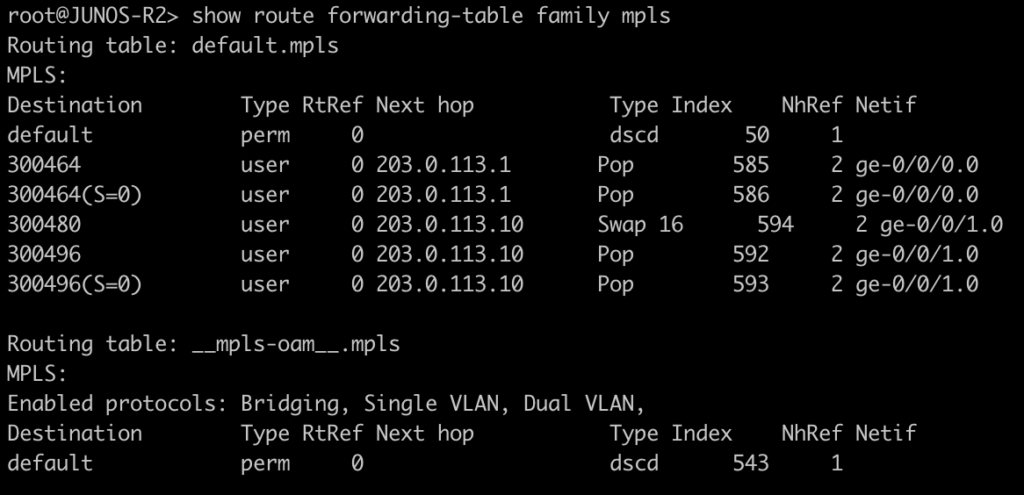
root@JUNOS-R2> show route forwarding-table family mpls
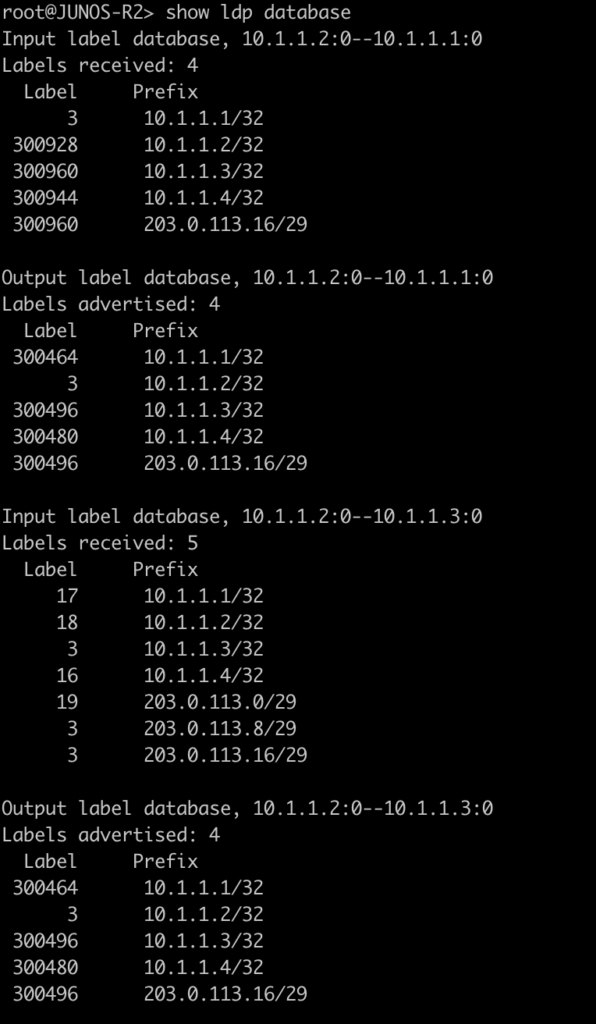
The next two commands will be combined since juniper only has one command to be equivalent to mikrotiks output. This is will show the advertised and received labels for all of the prefixes known to LDP as well as the label associated with it and where it was learned from. On JunOS you will notice label 3. This is juiper’s method to signal implicit null and request label popping by the downstream router.
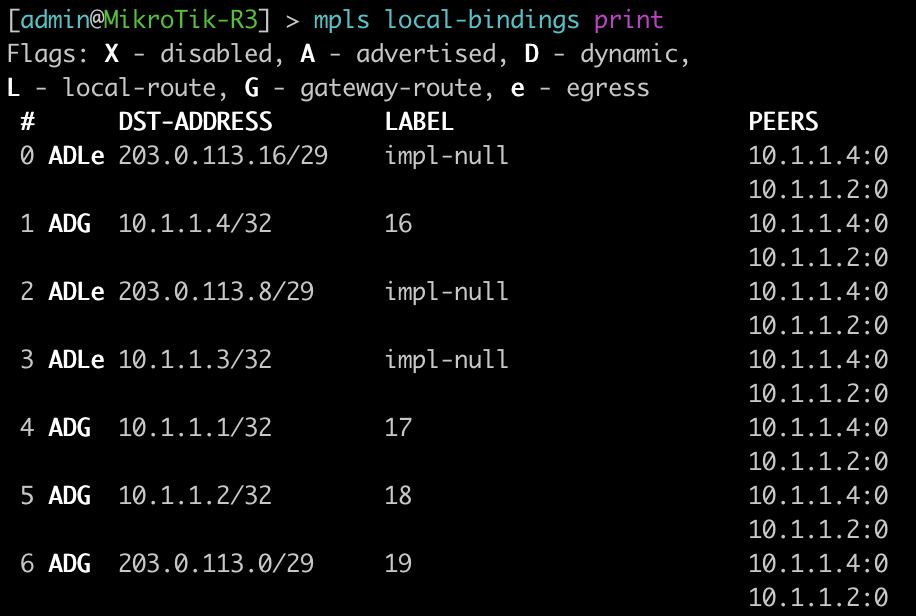
[admin@MikroTik-R3] > mpls remote-bindings print
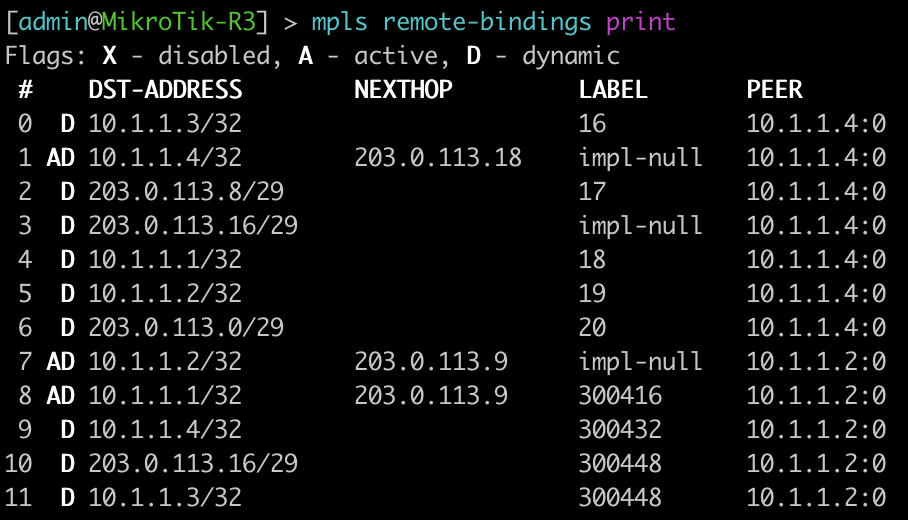
[admin@MikroTik-R3] > mpls local-bindings print
root@JUNOS-R2> show ldp database
This last command will show the label ranges and what they are used for.
[admin@MikroTik-R3] > mpls print
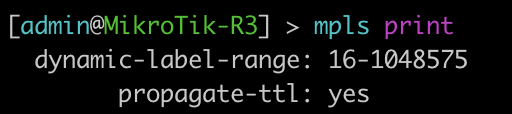
root@JUNOS-R2> show mpls label usage

Configurations
root@JUNOS-R1# show | display set
set version 18.2R1.9
set system root-authentication encrypted-password "$6$iCt/DOMc$lQFrIQdrjot1m0lIY5A2eUaOmat87oAqbNZWd/3KPij2QWTlBQEyYlVbb1/emd2N9VKN6NL0olk.kJK7mLcgM0"
set system host-name JUNOS-R1
set system syslog user * any emergency
set system syslog file messages any notice
set system syslog file messages authorization info
set system syslog file interactive-commands interactive-commands any
set system processes dhcp-service traceoptions file dhcp_logfile
set system processes dhcp-service traceoptions file size 10m
set system processes dhcp-service traceoptions level all
set system processes dhcp-service traceoptions flag packet
set interfaces ge-0/0/0 unit 0 family inet address 203.0.113.1/29
set interfaces ge-0/0/0 unit 0 family mpls
set interfaces fxp0 unit 0 family inet dhcp vendor-id Juniper-vmx-VM6015C6C2F2
set interfaces lo0 unit 0 family inet address 10.1.1.1/32
set routing-options router-id 10.1.1.1
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0
set protocols ospf area 0.0.0.0 interface lo0.0 passive
set protocols ldp interface ge-0/0/0.0root@JUNOS-R2# show | display set
set version 18.2R1.9
set system root-authentication encrypted-password "$6$x.MmgodX$XG1D3lCYPC8VpIhE8NXxdRJaoZS8sYB2PB0v50POrrx6Mi.nhnTB/41NGFk1zL8RDQBdR/lCPG2NazFDYgzNf/"
set system host-name JUNOS-R2
set system syslog user * any emergency
set system syslog file messages any notice
set system syslog file messages authorization info
set system syslog file interactive-commands interactive-commands any
set system processes dhcp-service traceoptions file dhcp_logfile
set system processes dhcp-service traceoptions file size 10m
set system processes dhcp-service traceoptions level all
set system processes dhcp-service traceoptions flag packet
set interfaces ge-0/0/0 unit 0 family inet address 203.0.113.2/29
set interfaces ge-0/0/0 unit 0 family mpls
set interfaces ge-0/0/1 unit 0 family inet address 203.0.113.9/29
set interfaces ge-0/0/1 unit 0 family mpls
set interfaces fxp0 unit 0 family inet dhcp vendor-id Juniper-vmx-VM6015C6C3B3
set interfaces lo0 unit 0 family inet address 10.1.1.2/32
set routing-options router-id 10.1.1.2
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0
set protocols ospf area 0.0.0.0 interface ge-0/0/1.0
set protocols ospf area 0.0.0.0 interface lo0.0 passive
set protocols ldp interface ge-0/0/0.0
set protocols ldp interface ge-0/0/1.0[admin@MikroTik-R3] > export
# jan/31/2021 20:52:19 by RouterOS 6.46.8
# software id =
#
#
#
/interface bridge
add name=Loopback0
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip address
add address=203.0.113.10/29 interface=ether1 network=203.0.113.8
add address=10.1.1.3 interface=Loopback0 network=10.1.1.3
add address=203.0.113.17/29 interface=ether2 network=203.0.113.16
/ip dhcp-client
add disabled=no interface=ether2
add disabled=no interface=ether1
/mpls ldp
set enabled=yes lsr-id=10.1.1.3
/mpls ldp interface
add interface=ether1
add interface=ether2
/routing ospf network
add area=backbone network=203.0.113.8/29
add area=backbone network=10.1.1.3/32
add area=backbone network=203.0.113.16/29
/system identity
set name=MikroTik-R3[admin@MikroTik-R4] > export
# jan/31/2021 21:06:10 by RouterOS 6.46.8
# software id =
#
#
#
/interface bridge
add name=Loopback0
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip address
add address=203.0.113.18/29 interface=ether1 network=203.0.113.16
add address=10.1.1.4 interface=Loopback0 network=10.1.1.4
/ip dhcp-client
add disabled=no interface=ether2
add disabled=no interface=ether1
/mpls ldp
set enabled=yes lsr-id=10.1.1.4
/mpls ldp interface
add interface=ether1
/routing ospf network
add area=backbone network=203.0.113.16/29
add area=backbone network=10.1.1.4/32
/system identity
set name=MikroTik-R4Thanks for joining us for this series and check back soon for more posts.
]]>In the world of network engineering, learning a new syntax for a NOS can be daunting if you need a specific config quickly. Juniper is a popular option for service providers/data centers and is widely deployed across the world.
This is a continuation of the Rosetta stone for network operating systems series. In this portion of the series we will be covering Open Shortest Path First, OSPF, version 2 which is a popular interior gateway protocol (IGP).
You can find the first article of the series Juniper to Mikrotik – BGP Commands here.
While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
Using EVE-NG for testing
We conducted all testing on EVE-NG utilizing the topology seen below.
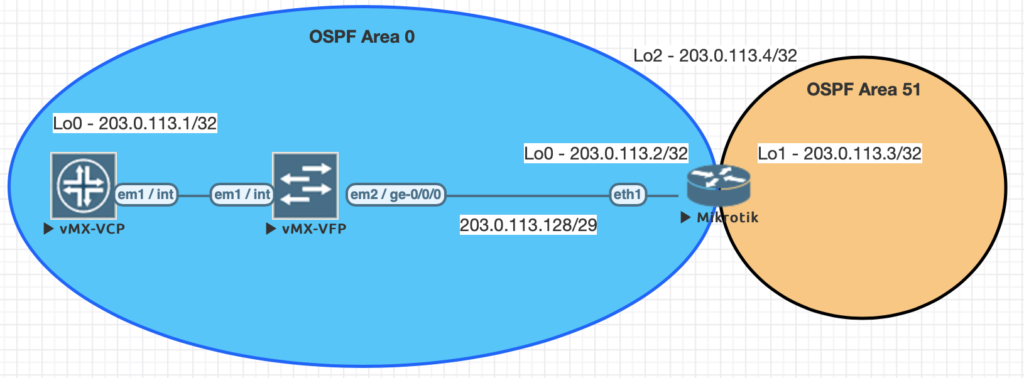
| JunOS Command | MikroTik Command |
|---|---|
| show ospf neighbor | routing ospf neighbor print |
| show ospf interface | routing ospf interface print |
| show ospf overview brief | routing ospf instance print detail |
| show ospf database | routing ospf lsa print |
| show route protocol ospf | ip route print where ospf=yes |
| show ospf route abr | routing ospf area-border-router print |
| show ospf route asbr | routing ospf as-border-router print |
| edit protocols ospf | /routing ospf instance |
| set routing-options router-id 203.0.113.1 | /routing ospf instance set 0 router-id=203.0.113.2 |
| set protocols ospf area 0.0.0.0 interface lo0.0 | /routing ospf network add area=backbone network=203.0.113.2/32 |
| set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 | /routing ospf network add area=backbone network=203.0.113.128/29 |
| set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 interface-type p2p set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 hello-interval 1 set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 dead-interval 4 | /routing ospf interface add dead-interval=4s hello-interval=1s interface=ether1 network-type=point-to-point |
Examples of the commands above
This first command will show you all of the routers you have an OSPF neighbor adjacency with.
[admin@MIKROTIK-OSPF] > routing ospf neighbor print

root@JUNOS-OSPF> show ospf neighbor

This next command lists all of the interface enabled for OSPF as well as some basic information such as cost, priority, and network type. Juniper displays slightly different information such as area, DR info, and number of neighbors. Juniper does not have the concept of a network statement so interfaces explicitly configured for OSPF will appear here. You can optionally add the detail command on JunOS for more information.
[admin@MIKROTIK-OSPF] > routing ospf interface print
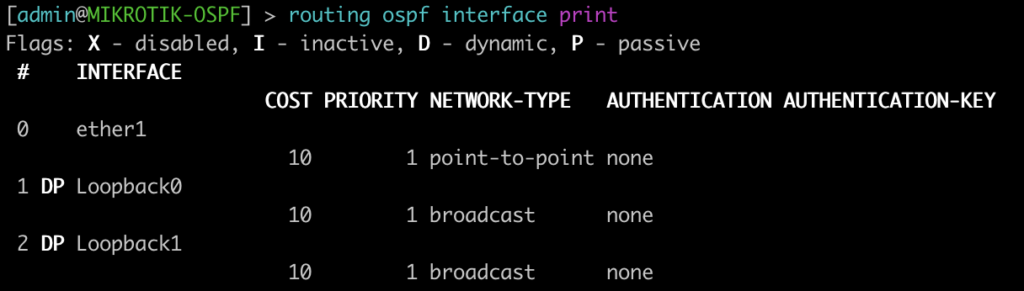
root@JUNOS-OSPF> show ospf interface

This command will list all of the details regarding the OSPF instances running on the router.
[admin@MIKROTIK-OSPF] > routing ospf instance print

root@JUNOS-OSPF> show ospf overview brief
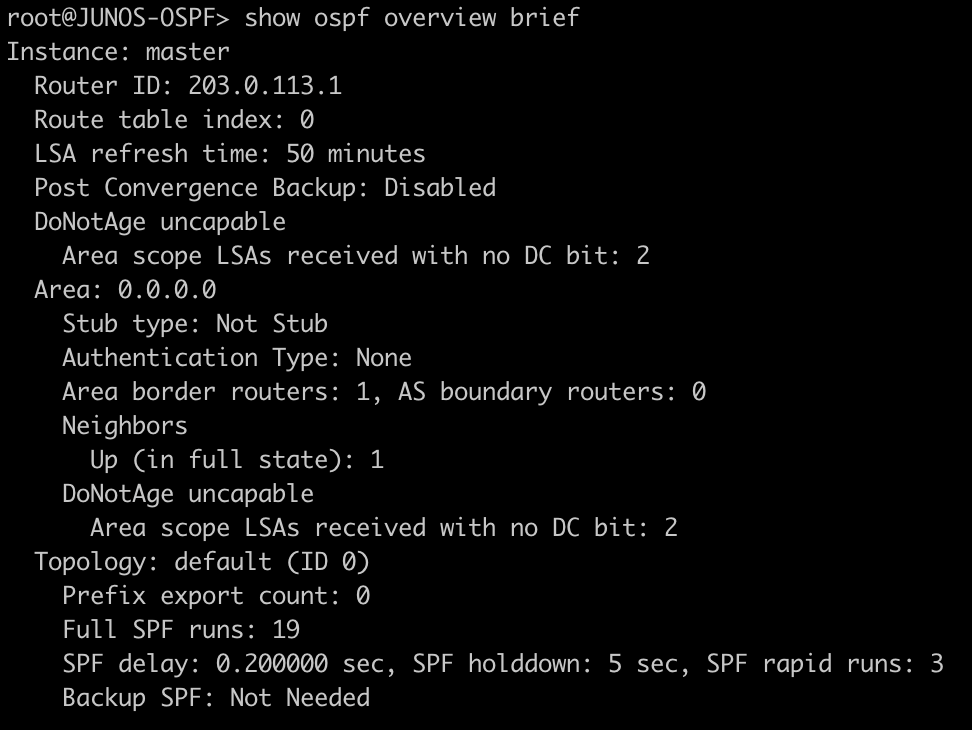
This command lists all of the OSPF LSAs as well as some details about them.
[admin@MIKROTIK-OSPF] > routing ospf lsa print
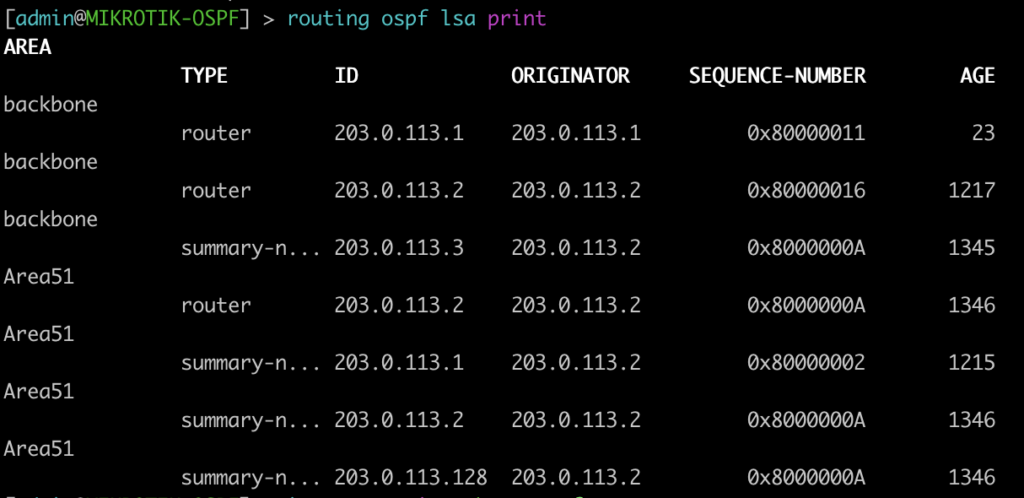
root@JUNOS-OSPF> show ospf database
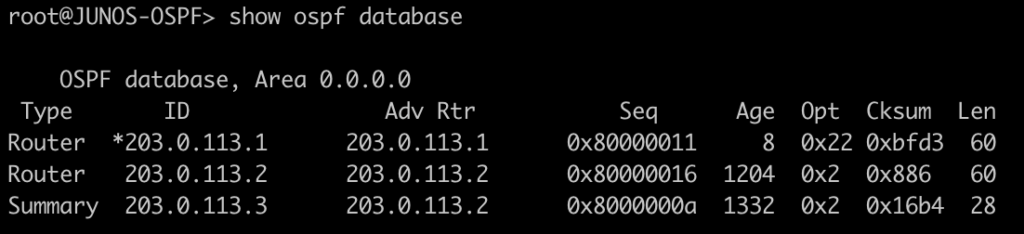
This next command will show all of the OSPF routes in the routing table.
[admin@MIKROTIK-OSPF] > ip route print where ospf=yes

root@JUNOS-OSPF> show route protocol ospf
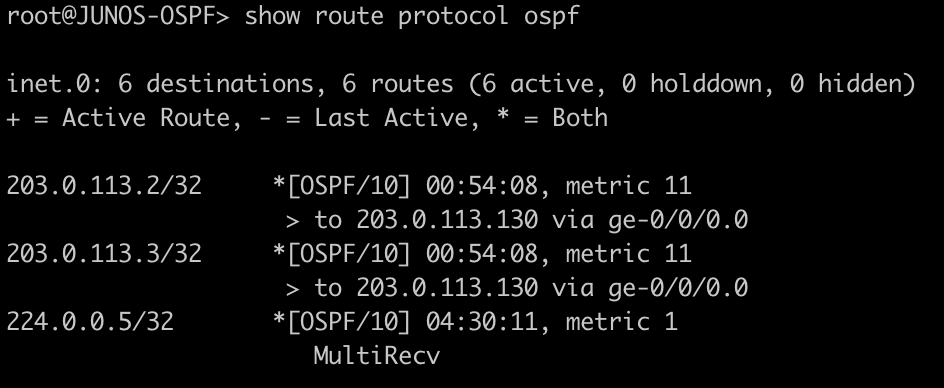
This next set of commands will show you the area-border-routers or autonomous-system-boundary routers. We injected a connected route into OSPF to generate a type-5 LSA for an external route.
[admin@MIKROTIK-OSPF] > routing ospf area-border-router print
[admin@MIKROTIK-OSPF] > routing ospf as-border-router print

root@JUNOS-OSPF> show ospf route abr

root@JUNOS-OSPF> show ospf route asbr

Mikrotik OSPF configuration
/interface bridge
add name=Loopback0
add name=Loopback1
add name=Loopback2
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/routing ospf area
add area-id=0.0.0.51 name=Area51
/routing ospf instance
set [ find default=yes ] redistribute-connected=as-type-1 router-id=203.0.113.2
/ip address
add address=203.0.113.2 interface=Loopback0 network=203.0.113.2
add address=203.0.113.3 interface=Loopback1 network=203.0.113.3
add address=203.0.113.4 interface=Loopback2 network=203.0.113.4
add address=203.0.113.130/29 interface=ether1 network=203.0.113.128
/ip dhcp-client
add dhcp-options=hostname,clientid disabled=no interface=ether1
/routing ospf interface
add dead-interval=4s hello-interval=1s interface=ether1 network-type=point-to-point
/routing ospf network
add area=backbone network=203.0.113.2/32
add area=backbone network=203.0.113.128/29
add area=Area51 network=203.0.113.3/32
/system identity
set name=MIKROTIK-OSPFJuniper OSPF configuration
set interfaces ge-0/0/0 unit 0 family inet address 203.0.113.129/29
set interfaces lo0 unit 0 family inet address 203.0.113.1/32
set routing-options router-id 203.0.113.1
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 interface-type p2p
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 hello-interval 1
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 dead-interval 4
set protocols ospf area 0.0.0.0 interface lo0.0 passiveMore Juniper to MikroTik articles are on the way!
This article covered some of basic and common OSPF commands. Check back in the future for examples of more advanced features and capabilities. Also stay tuned for our upcoming Juniper to MikroTik MPLS command translation.
]]>In the world of network engineering, learning a new syntax for a NOS can be daunting if you need a specific config quickly. Juniper is a popular option for service providers/data centers and is widely deployed across the world.
This is a continuation of the Rosetta stone for network operating systems series. We’ll be working through several protocols over series of posts to help you quickly move between different environments.
While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
Using EVE-NG for testing
We conducted all of this testing utilizing EVE-NG and the topology seen below.
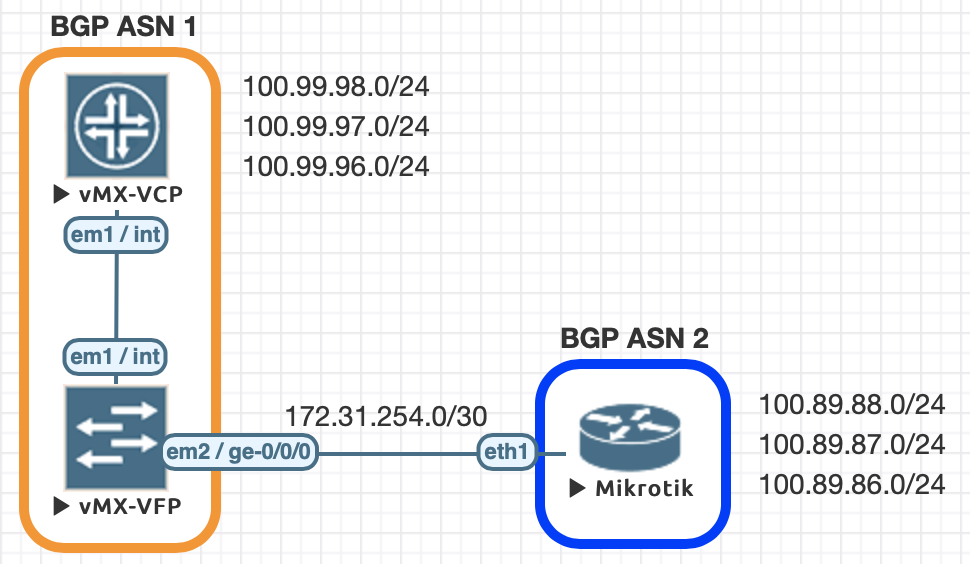
| Juniper Command | MikroTik Command |
|---|---|
| show bgp summary | routing bgp peer print brief |
| show bgp neighbor | routing bgp peer print status |
| show route advertising-protocol bgp 172.31.254.2 | routing bgp advertisements print peer=peer_name |
| show route receive-protocol bgp 172.31.254.2 | ip route print where received-from=peer_name |
| show route protocol bgp | ip route print where bgp=yes |
| clear bgp neighbor 172.31.254.2 soft-inbound | routing bgp peer refresh peer_name |
| clear bgp neighbor 172.31.254.2 soft | routing bgp peer resend peer_name |
| set routing-options autonomous-system 1 | /routing bgp instance set default as=2 |
| set protocols bgp group EBGP type external set protocols bgp group EBGP peer-as 2 set protocols bgp group EBGP neighbor 172.31.254.2 | /routing bgp peer add name=PEER-1 remote-address=172.31.254.1 remote-as=1 |
| set policy-options policy-statement REDIS-CONNECTED term 1 from protocol direct set policy-options policy-statement REDIS-CONNECTED term 1 then accept set protocols bgp group EBGP export REDIS-CONNECTED | /routing bgp network add network=100.89.88.0/24 add network=100.89.87.0/24 add network=100.89.86.0/24 |
| set routing-options static route 0.0.0.0/0 discard set protocols bgp group EBGP export SEND-DEFAULT set policy-options policy-statement SEND-DEFAULT term 1 from protocol static set policy-options policy-statement SEND-DEFAULT term 1 from route-filter 0.0.0.0/0 exact set policy-options policy-statement SEND-DEFAULT term 1 then accept | /routing bgp peer add default-originate-always name=PEER-1 remote-address=172.31.254.1 remote-as=1 |
Examples of the commands above
This is a quick way to get a list of the peers/ASN and their status
[admin@MIKROTIK-BGP] > routing bgp peer print brief

root@JUNOS-BGP> show bgp summary

This next command will show you more information about a peer. In this case we did not specify the peer as there is only one. On a peering router with multiple peers it is recommended to look only at specific peer information to not be overwhelmed with irrelevant information.
[admin@MIKROTIK-BGP] > routing bgp peer print status

root@JUNOS-BGP> show bgp neighbor
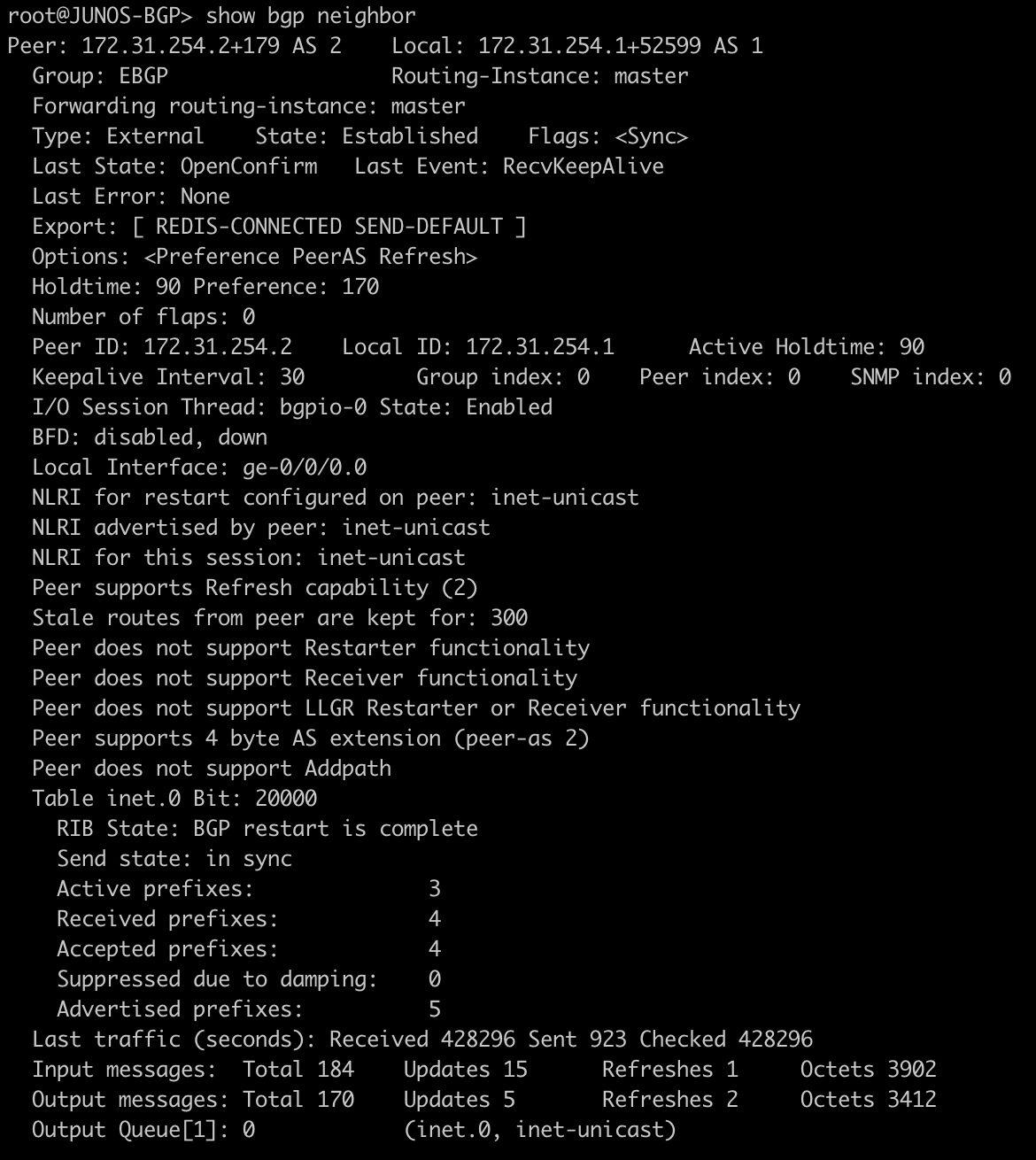
The next command allows you to see the prefixes that are sent to your peer as well as the next-hop associated with it.
[admin@MIKROTIK-BGP] > routing bgp advertisements print peer=PEER-1

root@JUNOS-BGP> show route advertising-protocol bgp 172.31.254.2
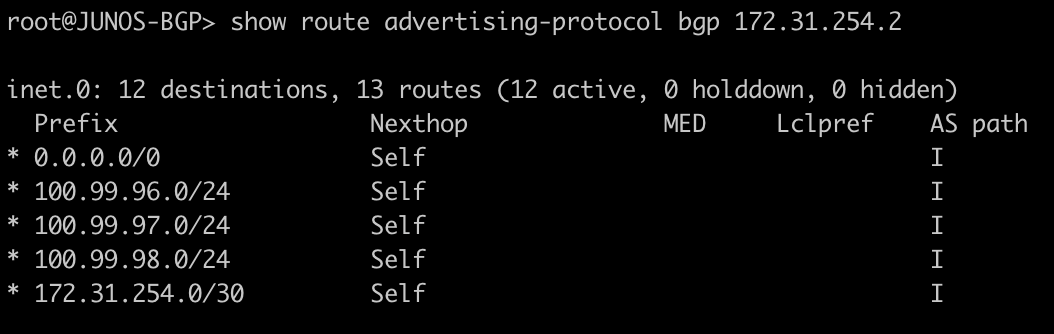
This next one will show you what routes were received from the peer and the next-hop you will advertise.
[admin@MIKROTIK-BGP] > ip route print where received-from=PEER-1
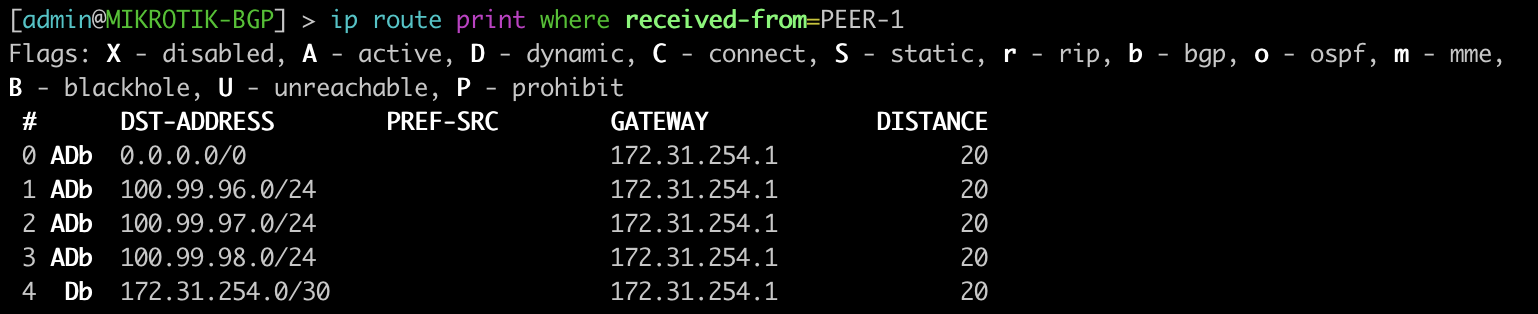
root@JUNOS-BGP> show route receive-protocol bgp 172.31.254.2

Here we will see the BGP prefixes that are in the routing table – both active and not. On junOS you will see the count for hidden routes in the output but you will not see the hidden entries. This will require the use of “show route protocol bgp hidden” to see the hidden entries. On mikrotik you will see this type of route in the route table as inactive.
[admin@MIKROTIK-BGP] > ip route print where bgp=yes

root@JUNOS-BGP> show route protocol bgp
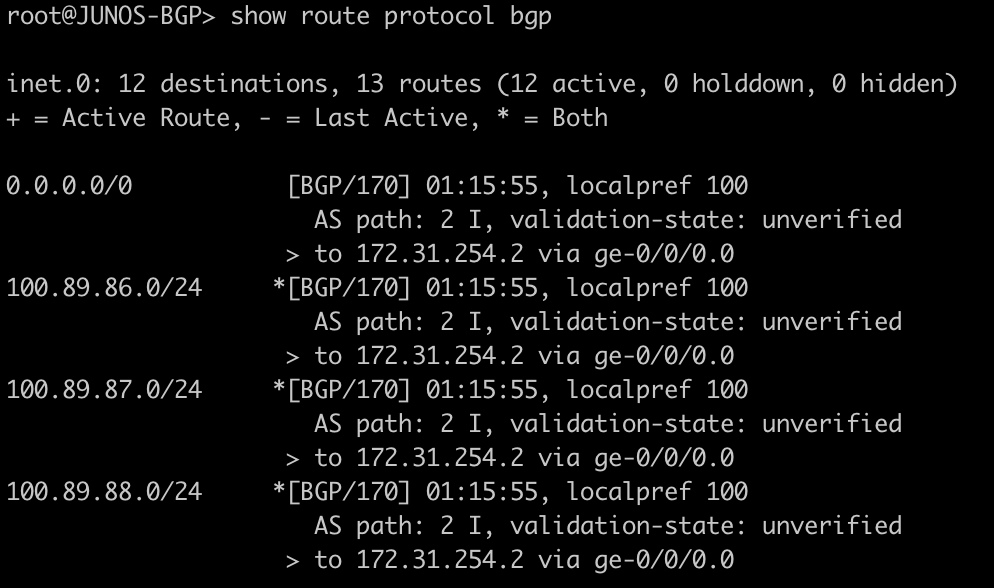
Configure BGP instance, peering, and originate a default route.
Here is a very basic BGP peering configuration to establish a peer, advertise a few routes, and originate a default route.
Let’s look at some of the differences in the configuration.
It’s worth noting that everything in CAPS was manually defined .
On junOS there is no concept of the “network” command that you might see in MikroTik or Cisco.
To accomplish the same functionality in this example I used a policy-statement named REDIS-CONNECTED that matched any connected route for redistribution.
This is then applied as an export statement into the EBGP peer group. Likewise, there is not a construct for “default-originate”. In order to accomplish the same functionality, we created a static route to discard and exported this to the EBGP peer.
MikroTik BGP Configuration
/routing bgp instance
set default as=2
/routing bgp network
add network=100.89.88.0/24
add network=100.89.87.0/24
add network=100.89.86.0/24
/routing bgp peer
add default-originate=always name=PEER-1 remote-address=172.31.254.1 remote-as=1Juniper BGP Configuration
set interfaces lo0 unit 0 family inet address 100.99.98.1/24
set interfaces lo0 unit 0 family inet address 100.99.97.1/24
set interfaces lo0 unit 0 family inet address 100.99.96.1/24
set routing-options static route 0.0.0.0/0 discard
set routing-options autonomous-system 1
set protocols bgp group EBGP type external
set protocols bgp group EBGP export REDIS-CONNECTED
set protocols bgp group EBGP export SEND-DEFAULT
set protocols bgp group EBGP peer-as 2
set protocols bgp group EBGP neighbor 172.31.254.2
set policy-options policy-statement REDIS-CONNECTED term 1 from protocol direct
set policy-options policy-statement REDIS-CONNECTED term 1 then accept
set policy-options policy-statement SEND-DEFAULT term 1 from protocol static
set policy-options policy-statement SEND-DEFAULT term 1 from route-filter 0.0.0.0/0 exact
set policy-options policy-statement SEND-DEFAULT term 1 then acceptMore to come
There are so many commands to consider for BGP, we probably could have added close to 100, but we decided to list the commands we use most often to start with and will be adding to the list of BGP commands as well as other like OSPF, MPLS, and VLANs in future posts.
]]>
Overview
One of the long awaited benefits of RouterOS version 7 is a new routing protocol stack that enables new capabilities and fixes limitations in RouterOSv6 caused by the use of a very old Linux kernel.
The new routing stack in v7 has created quite a buzz in the MikroTik community as lab tests have shown that it’s significantly more efficient in processing large numbers of BGP routes.
The ability to use MikroTik’s new generation of CCR routers with ARM64 to quickly process BGP routes is a blog post all to itself and we’ll tackle that in the future – however, the information below provides a quick look into the performance comparison between ROS v6 and v7.

The new routing stack also paves the way to add a number of features that have been needed for a long time like RPKI and large community support.
Using a lab based on EVE-NG, we’ll take a look at configuration changes and iBGP using the IPv6 AFI with OSPFv3 as the IGP for loopback/next hop reachability. Prior to 7.1beta2, this has been nonfunctional for years due to routing recursion limitations.
v7 Routing Protocol Status
For the most up to date information about features and capabilities in v7, MikroTik created a page that tracks feature status across the different beta releases
https://help.mikrotik.com/docs/display/ROS/v7+Routing+Protocol+Status
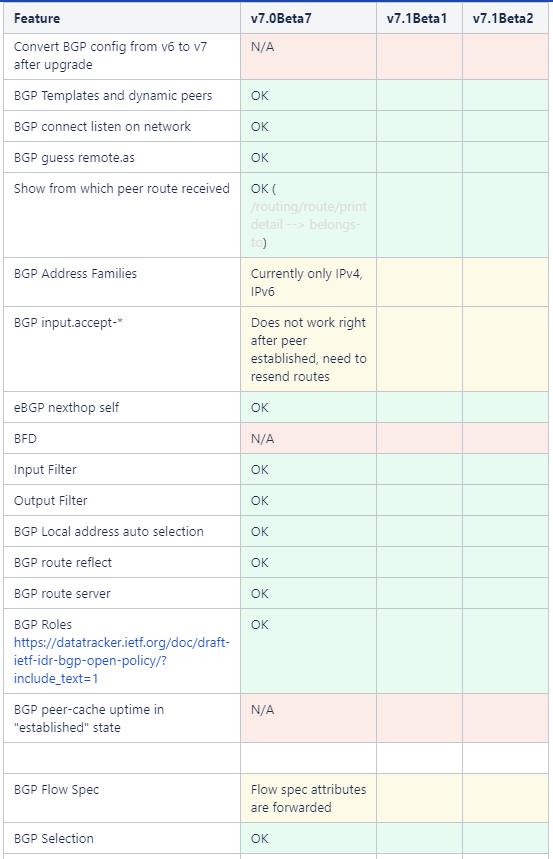
Lab design
ROS Version: 7.1beta2 (7.1beta3 was released just before I published this – at some point i’ll update with testing on beta3)
Network Modeling: EVE-NG Pro
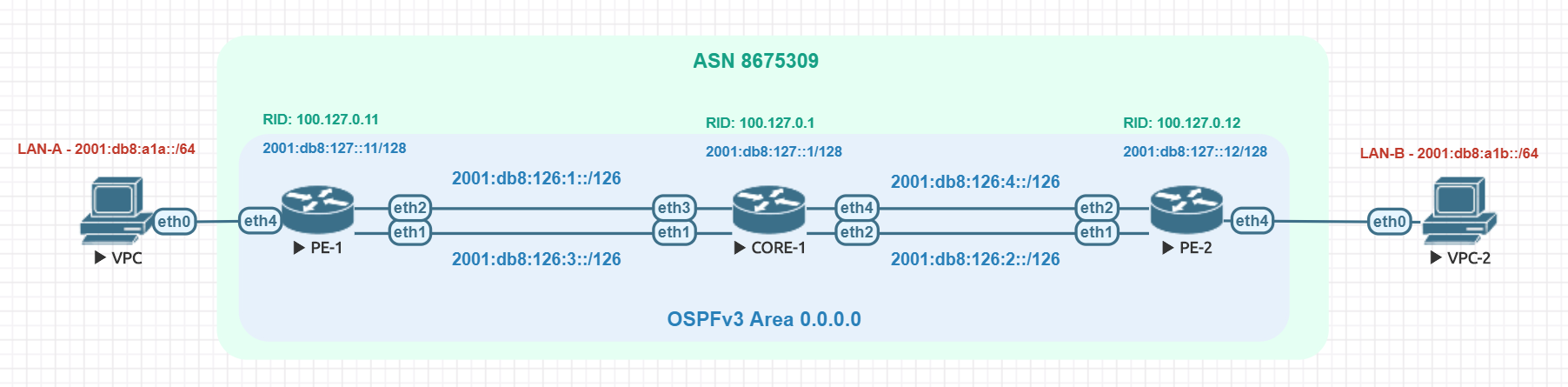
OSPFv3
One of the biggest changes in OSPF for both version 2 (IPv4) and version 3 (IPv6) is the consolidation of menus into a single location for OSPF configuration.
In ROSv7, all configuration occurs under /routing/ospf/ and instances can be created for v2 or v3.
Change from ROSv6: OSPF Menu options have changed in ROSv7, this is partly due to combining OPSFv2 and OSPFv3 into a single configuration framework.
OSPF command options in ROSv6 for OSPFv2 and OSPFv3
OSPF command options in ROSv7 for both versions of OSPF

Change from ROSv6: There is a new flag in the IPv6 routing table for ECMP and no flag for RIP
When looking at the new output for the routing table, a few things stand out. ECMP has a new flag using the “+” symbol to denote two or more equal paths.
ECMP in IPv6 is a feature limitation that RouterOSv6 had and this will make it easier to deploy IPv6 networks with MikroTik.
RIP or Routing Internet Protocol is missing from the routing flags. It’s unclear at this point whether RIPv2 or RIP-NG will make it into RouterOSv7 since it’s not used very often anymore in prod networks.
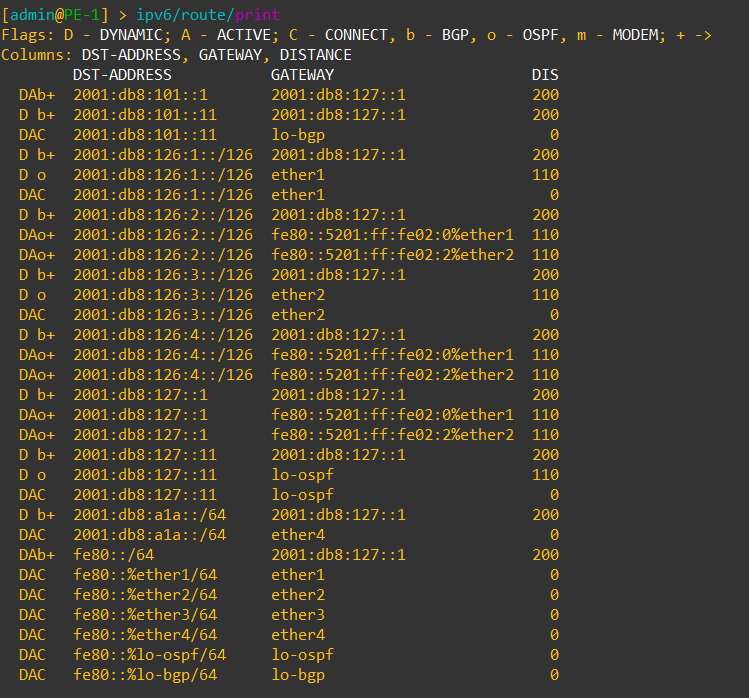
Correcting issues with recursive routing in IPv6.
Being able to use recursive routing for advertising loopbacks and using iBGP with IPv6 has been a limitation of ROSv6 for a long time due to the older linux kernel in use.
Now that ROSv7 has added the initial support for OSPF and BGP, we are able to test IPv6 routing recursion.
Here is a test from PE-1 to PE-2 (2001:db8:101::12) using iBGP
It works!
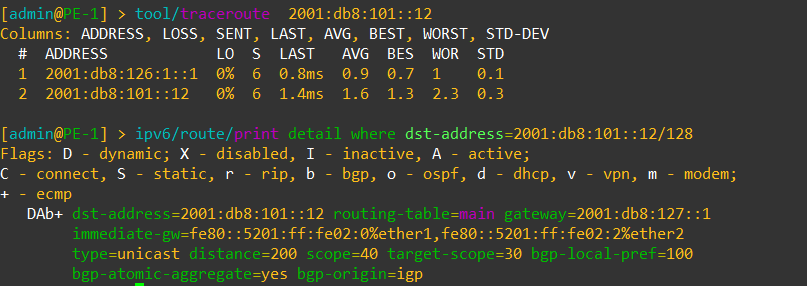
Change from ROSv6: Using filters in OSPF
One of the first major challenges I had to solve when working with ROSv7 was figuring out why every route available became advertised into OSPF.
At first it looked like a bug, but when I dug deeper, I came across this snippet in the new MikroTik help docs
ROSv7 Basic Routing Examples – RouterOS – MikroTik Documentation
As it turns out, the default behavior is to advertise all routes in the absence of an outbound filter.
The next challenge was figuring out the new filtering syntax.
/routing filter rule add chain=OSPF-permit-only-configured /routing filter select-rule add chain=OSPF-permit-only-configured_select do-where=\ OSPF-permit-only-configured
In order to use a rule in ROSv7, the “/routing filter select-rule” command must be used and reference the filter rule or no action will be taken.
In the example above, only interfaces that have been configured for OSPF will be advertised.
OSPF Config
Here is a summary of the OSPF configuration from the PE-1 router
/routing ospf instance add name=IPv6 out-filter=OSPF-permit-only-configured_select router-id=\ 100.127.0.11 version=3 /routing ospf area add area-id=0.0.0.0 instance=IPv6 name=area-0 /routing filter rule add chain=OSPF-permit-only-configured /routing filter select-rule add chain=OSPF-permit-only-configured_select do-where=\ OSPF-permit-only-configured /routing ospf interface add area=area-0 network=ether1 network-type=point-to-point add area=area-0 network=ether2 network-type=point-to-point add area=area-0 network=lo-ospf network-type=broadcast
BGP
As with OSPF, BGP saw a change in menu structure.
In ROSv7, BGP configuration has been revamped and is much closer to the style of configuration that Cisco/Juniper use with config elements that can be nested and reused.
Considering all the work that’s being done to improve full table convergence time on ROSv7, this change is a step in the right direction to allow MikroTik to compete with larger network vendors in the area of peering and transit.
Change from ROSv6: BGP Menu options have changed in ROSv7 to accommodate new features like Templates and RPKI
BGP command options in ROSv6
BGP command options in ROSv7

New Feature: BGP Roles
This is a new capability in BGP as of July 2020 and MikroTik was one of the first to have it implemented.
draft-ietf-idr-bgp-open-policy-13 – Route Leak Prevention using Roles in Update and Open messages

The main goal is to classify peerings into different roles that prevent inadvertent route leaks by adopting some basic filtering policies as a component of the role assignment.
Acceptable pairings are:

Here is an example of role types in ROSv7

This is an overview of how the roles deal with route advertisements and filtering.

New Feature: BGP Templates
BGP Templates allow specific settings for a peer connection to be reused in the connection configuration.
This saves quite a bit of time when deploying a large number of iBGP peerings, transit peerings, IX peerings, etc
Options available to set in templates
Here is a BGP template as configured in the lab for this post. The template is referenced by the connection config (aka peer config)
/routing bgp template add address-families=ipv6 as=8675309 instance=bgp name=ASN-8675309 /routing bgp connection add local.address=2001:db8:127::11 .role=ibgp-rr-client remote.address=\ 2001:db8:127::1 .as=8675309 template=ASN-8675309
New Feature: iBGP ECMP for IPv6
ECMP has been working in ROSv6 for a ling time, but due to kernel limitations, it hasn’t been available in IPv6 due to the problems in routing recursion and making iBGP operational.
Now that routing recursion is fixed for IPv6, ECMP is possible.
ECMP capable IPV6 routes in BGP noted by the new “+” symbol in the routing table for ECMP.
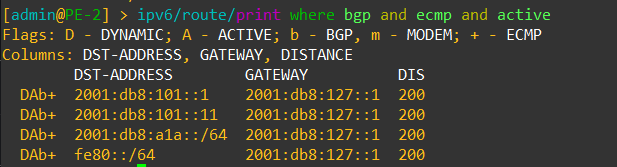
Here is an example of a traceroute to the same prefix that’s using two different paths with ECMP.
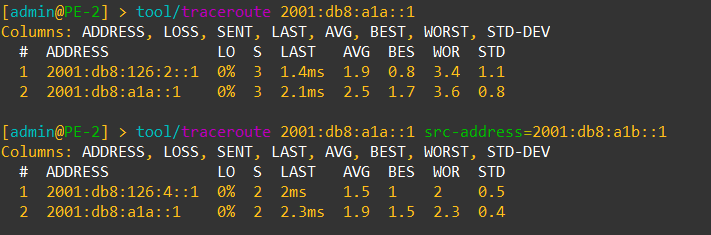
BGP Configuration
Here is an overview of the BGP configuration for PE-1
/routing instance add id=100.127.0.11 name=bgp /routing bgp template add address-families=ipv6 as=8675309 instance=bgp name=ASN-8675309 /routing bgp connection add local.address=2001:db8:127::11 .role=ibgp-rr-client remote.address=\ 2001:db8:127::1 .as=8675309 template=ASN-8675309
Lab configurations
All Lab configs for ROSv7 are listed below (tested in 7.1beta2)
PE-1
/interface bridge
add name=lo-bgp
add name=lo-ospf
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip vrf
add list=all name=main
/routing instance
add id=100.127.0.11 name=bgp
/routing bgp template
add address-families=ipv6 as=8675309 instance=bgp name=ASN-8675309
/routing ospf instance
add name=IPv6 out-filter=OSPF-permit-only-configured_select router-id=\
100.127.0.11 version=3
/routing ospf area
add area-id=0.0.0.0 instance=IPv6 name=area-0
/ip dhcp-client
add disabled=no interface=ether1
/ipv6 address
add address=2001:db8:126:1::2/126 advertise=no interface=ether1
add address=2001:db8:127::11/128 advertise=no interface=lo-ospf
add address=2001:db8:101::11/128 advertise=no interface=lo-bgp
add address=2001:db8:126:3::2/126 advertise=no interface=ether2
add address=2001:db8:a1a::1 interface=ether4
/routing bgp connection
add local.address=2001:db8:127::11 .role=ibgp-rr-client remote.address=\
2001:db8:127::1 .as=8675309 template=ASN-8675309
/routing filter rule
add chain=OSPF-permit-only-configured
/routing filter select-rule
add chain=OSPF-permit-only-configured_select do-where=\
OSPF-permit-only-configured
/routing ospf interface
add area=area-0 network=ether1 network-type=point-to-point
add area=area-0 network=ether2 network-type=point-to-point
add area=area-0 network=lo-ospf network-type=broadcast
/system identity
set name=PE-1CORE-1
/interface bridge
add name=lo-bgp
add name=lo-ospf
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip vrf
add list=all name=main
/routing instance
add id=100.127.0.1 name=bgp
/routing bgp template
add address-families=ipv6 as=8675309 instance=bgp name=ASN-8675309
/routing ospf instance
add name=IPv6 router-id=100.127.0.1 version=3
/routing ospf area
add area-id=0.0.0.0 instance=IPv6 name=area-0
/ip dhcp-client
add disabled=no interface=ether1
/ipv6 address
add address=2001:db8:126:1::1/126 advertise=no interface=ether1
add address=2001:db8:127::1/128 advertise=no interface=lo-ospf
add address=2001:db8:126:2::1/126 advertise=no interface=ether2
add address=2001:db8:126:3::1/126 advertise=no interface=ether3
add address=2001:db8:101::1/128 advertise=no interface=lo-bgp
add address=2001:db8:126:4::1/126 advertise=no interface=ether4
/routing bgp connection
add listen=yes local.address=2001:db8:127::1 .role=ibgp-rr remote.address=\
2001:db8:127::11 template=ASN-8675309
add listen=yes local.address=2001:db8:127::1 .role=ibgp-rr remote.address=\
2001:db8:127::12 template=ASN-8675309
/routing filter rule
add chain=OSPFv3-in match-prfx-value=dst<equal>2001:db8:101::/128
add chain=OSPFv3-in match-prfx-value=dst<equal>2001:db8:101::/128
/routing ospf interface
add area=area-0 network=ether1 network-type=point-to-point
add area=area-0 network=ether2 network-type=point-to-point
add area=area-0 network=ether3 network-type=point-to-point
add area=area-0 network=lo-ospf network-type=broadcast
add area=area-0 network=ether4 network-type=point-to-point
/system identity
set name=CORE-1PE-2
/interface bridge
add name=lo-bgp
add name=lo-ospf
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip vrf
add list=all name=main
/routing instance
add id=100.127.0.12 name=bgp
/routing bgp template
add address-families=ipv6 as=8675309 instance=bgp name=ASN-8675309
/routing ospf instance
add name=IPv6 out-filter=OSPF-permit-only-configured_select router-id=\
100.127.0.12 version=3
/routing ospf area
add area-id=0.0.0.0 instance=IPv6 name=area-0
/ip dhcp-client
add disabled=no interface=ether1
/ipv6 address
add address=2001:db8:126:2::2/126 advertise=no interface=ether1
add address=2001:db8:127::12/128 advertise=no interface=lo-ospf
add address=2001:db8:101::12/128 advertise=no interface=lo-bgp
add address=2001:db8:a1b::1 interface=ether4
add address=2001:db8:126:4::2/126 advertise=no interface=ether2
/routing bgp connection
add local.address=2001:db8:127::12 .role=ibgp-rr-client remote.address=\
2001:db8:127::1 .as=8675309 template=ASN-8675309
/routing filter rule
add chain=OSPF-permit-only-configured
/routing filter select-rule
add chain=OSPF-permit-only-configured_select do-where=\
OSPF-permit-only-configured
/routing ospf interface
add area=area-0 network=ether1 network-type=point-to-point
add area=area-0 network=lo-ospf network-type=broadcast
add area=area-0 network=ether2 network-type=point-to-point
/system identity
set name=PE-2VxLAN support added in 7.0beta5
MikroTik announced VxLAN support on Valentine’s Day (Feb 14th) of 2020.
This is a significant feature addition for RouterOSv7 as it will pave the way for a number of other additions like EVPN in BGP.
It will also give MikroTik the ability to appeal to enterprises and data centers that might need cost-effective VxLAN capable devices.
Service Providers are also moving towards VxLAN as a future replacement for VPLS so this is helpful for that market as well.
Download the OVA here:
https://download.mikrotik.com/routeros/7.0beta5/chr-7.0beta5.ova
Implementation
The initial release of VxLAN is based on unicast and multicast to deliver Layer 2 frames.
As there is no EVPN support, the VTEPs must be manually configured for each endpoint in a full mesh configuration.
The VxLAN interface can then be bridged to a physical ethernet port or VLAN interface to deliver the traffic to the end host.
Lab Example
Here is an overview lab in EVE-NG with a basic setup using 3 linux servers on the same 10.1.1.0/24 subnet which is carried as an overlay by VxLAN.
VxLAN reachability for VTEPs is acheived with OSPFv2 and loopback addresses.
VNI: 100
Multicast Group: 239.0.0.1
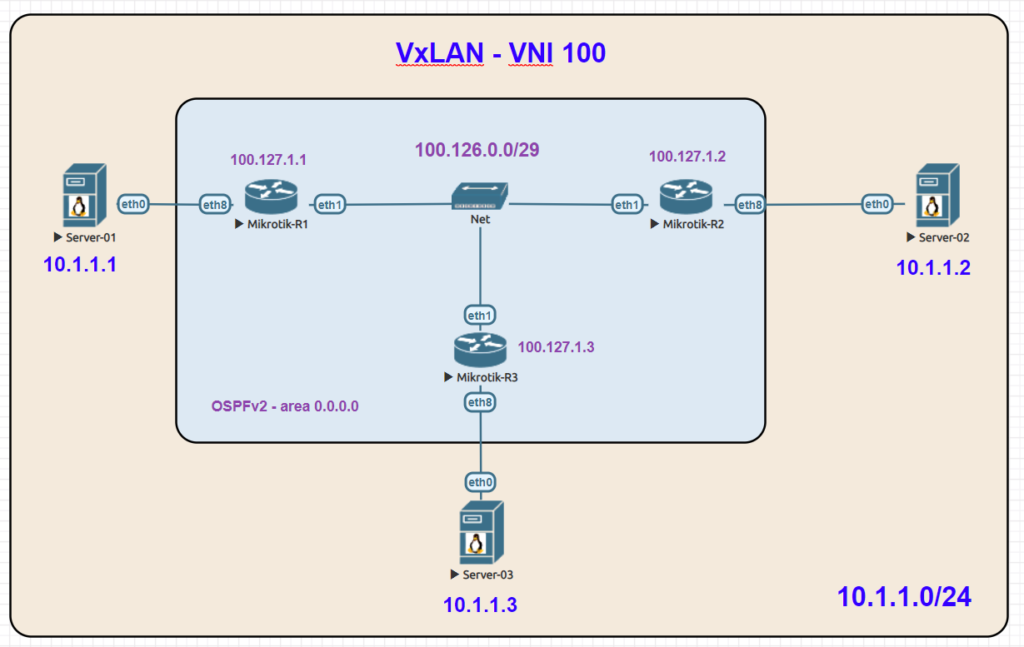
Lab Validation
In the following packet capture, traffic to UDP port 8472 can be seen between two endpoints.
The ICMP ping test between server 1 (10.1.1.1) and server 2 (10.1.1.2) is also visible
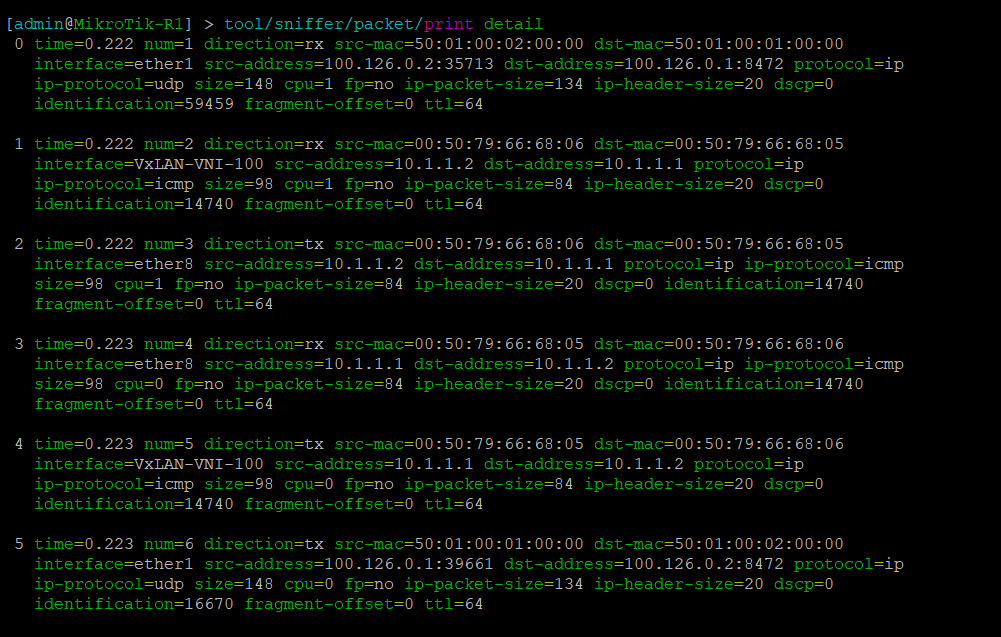
Pings between Server 1 and Servers 2 & 3
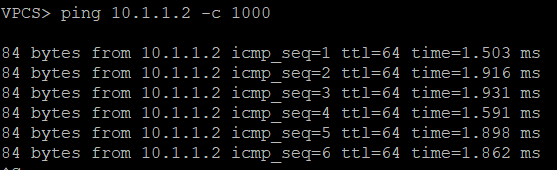
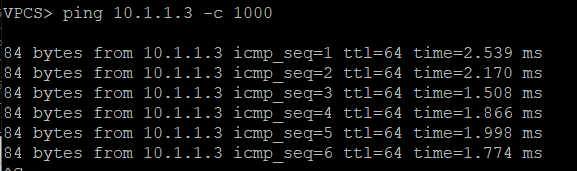
Configurations
R1
/interface bridge add name=Bridge-VxLAN-VNI-100 add name=Lo0 /interface vxlan add group=239.0.0.1 interface=ether1 mtu=1400 name=VxLAN-VNI-100 port=8472 vni=100 /routing ospf instance add name=ospf-instance-1 router-id=100.127.1.1 version=2 /routing ospf area add area-id=0.0.0.0 instance=ospf-instance-1 name=ospf-area-1 /interface bridge port add bridge=Bridge-VxLAN-VNI-100 interface=ether8 add bridge=Bridge-VxLAN-VNI-100 interface=VxLAN-VNI-100 /interface vxlan vteps add interface=VxLAN-VNI-100 remote-ip=100.127.1.2 add interface=VxLAN-VNI-100 remote-ip=100.127.1.3 /ip address add address=100.127.1.1 interface=Lo0 network=100.127.1.1 add address=100.126.0.1/29 interface=ether1 network=100.126.0.0 /routing ospf interface add area=ospf-area-1 instance-id=0 network=100.126.0.0/29 add area=ospf-area-1 instance-id=0 network=100.127.1.1 /system identity set name=MikroTik-R1
R2
/interface bridge add name=Bridge-VxLAN-VNI-100 add name=Lo0 /interface vxlan add group=239.0.0.1 interface=ether1 mtu=1400 name=VxLAN-VNI-100 port=8472 vni=100 /routing ospf instance add name=ospf-instance-1 router-id=100.127.1.2 version=2 /routing ospf area add area-id=0.0.0.0 instance=ospf-instance-1 name=ospf-area-1 /interface bridge port add bridge=Bridge-VxLAN-VNI-100 interface=ether8 add bridge=Bridge-VxLAN-VNI-100 interface=VxLAN-VNI-100 /interface vxlan vteps add interface=VxLAN-VNI-100 remote-ip=100.127.1.1 add interface=VxLAN-VNI-100 remote-ip=100.127.1.3 /ip address add address=100.127.1.2 interface=Lo0 network=100.127.1.2 add address=100.126.0.2/29 interface=ether1 network=100.126.0.0 /routing ospf interface add area=ospf-area-1 instance-id=0 network=100.126.0.0/29 add area=ospf-area-1 instance-id=0 network=100.127.1.2 /system identity set name=MikroTik-R2
R3
/interface bridge
add name=Bridge-VxLAN-VNI-100
add name=Lo0
/interface vxlan
add group=239.0.0.1 interface=ether1 mtu=1400 name=VxLAN-VNI-100 port=8472
vni=100
/routing ospf instance
add name=ospf-instance-1 router-id=100.127.1.3 version=2
/routing ospf area
add area-id=0.0.0.0 instance=ospf-instance-1 name=ospf-area-1
/interface bridge port
add bridge=Bridge-VxLAN-VNI-100 interface=ether8
add bridge=Bridge-VxLAN-VNI-100 interface=VxLAN-VNI-100
/interface vxlan vteps
add interface=VxLAN-VNI-100 remote-ip=100.127.1.1
add interface=VxLAN-VNI-100 remote-ip=100.127.1.2
/ip address
add address=100.127.1.3 interface=Lo0 network=100.127.1.3
add address=100.126.0.3/29 interface=ether1 network=100.126.0.0
/routing ospf interface
add area=ospf-area-1 instance-id=0 network=100.126.0.0/29
add area=ospf-area-1 instance-id=0 network=100.127.1.3
/system identity
set name=MikroTik-R3
]]>Juniper to MikroTik – a new series
Previously, I’ve written a number of articles that compared syntax between Cisco and MikroTik and have received some great feedback on them.
As such, I decided to begin a series on Juniper to MikroTik starting with MPLS and L3VPN interop as it related to a project I was working on last year.
In the world of network engineering, learning a new syntax for a NOS can be overwhelming if you need a specific set of config in a short timeframe. The command structure for RouterOS can be a bit challenging if you are used to Juniper CLI commands.
If you’ve worked with Juniper gear and are comfortable with how to deploy that vendor, it is helpful to draw comparisons between the commands, especially if you are trying to build a network with a MikroTik and Juniper router.
Lab Overview
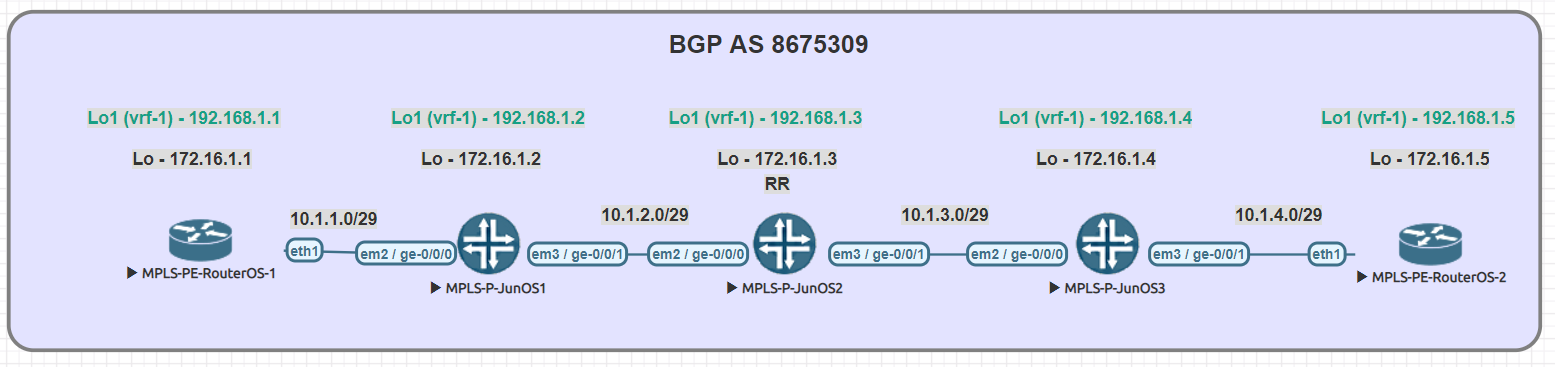
The lab consists of (3) Juniper P routers and (2) MikroTik PE routers. Although we did not get into L3VPN in this particular lab, the layout is the same.
A note on route-targets
It seems that the format of the route-target has some bearing on this being successful. Normally i’ll use a format like 8675309:1 but in this case, I had some interop issues with making that work so we used dotted decimal.
Some of the results when searching seem to suggest that platforms like Juniper and Cisco reverse the RT string in the packet while MikroTik uses it in sequential order
To work around that, the format we used was the same forwards and backwards – 1.1.1.1:1
MPLS and VPNv4 use case
MPLS is often used in service provider and data center networks to provide multi-tenancy.
VPNv4 specifically allows for separate routing tables to be created (VRFs) and advertised via BGP using the VPNv4 address family.
This address family relies on MPLS to assign a VPN label and route target as an extended community to the route which keeps it isolated from routes in other VRFs.
Practical Use
Many service provider networks rely on Juniper for the edge and core roles.
However, increasingly, ISPs want to save money on last mile and smaller aggregation points.
MikroTik is an effective choice for more simplistic MPLS capabilities as it’s inexpensive and interops with Juniper.
This creates a variety of low cost deployment options as a manged CE router, GPON aggregation in the last mile, managed CE for enterprise customers….and so on.
Command comparison
| Juniper command | MikroTik Command |
|---|---|
| > show ldp neighbor | mpls ldp neighbor print |
| > show mpls interface | mpls ldp interface print |
| > show route table mpls.0 | mpls forwarding-table print |
| > show ldp database | mpls remote-bindings print |
| > show ldp database | mpls local-bindings print |
| > show mpls label usage label-range | mpls print |
| > show ldp overview | mpls ldp print |
| # set interfaces ge-0/0/0 unit 0 family mpls # set protocols mpls interface ge-0/0/0.0 # set protocols ldp interface ge-0/0/0.0 | /mpls ldp interface add interface=ether1 |
| { inherited from loopback } | /mpls ldp set enabled=yes lsr-id=10.1.1.3 |
Testing connectivity
MikroTik – mpls forwarding table and vrf routes
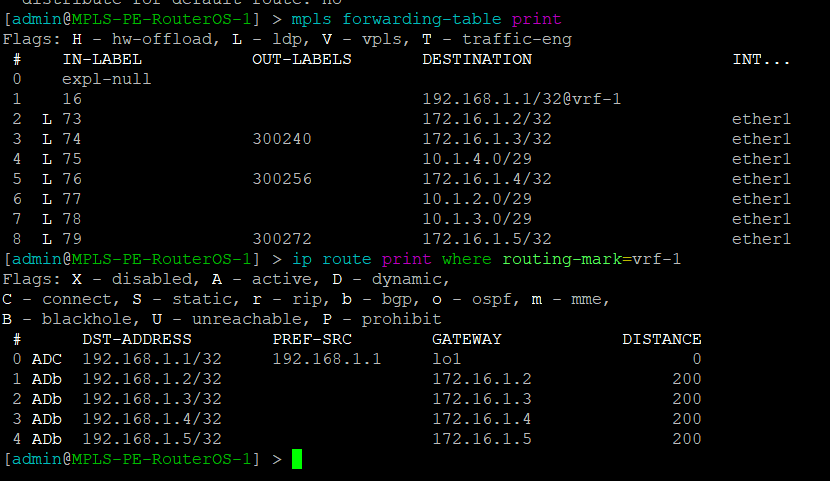
MikroTik – Ping PE2 through Juniper MPLS network
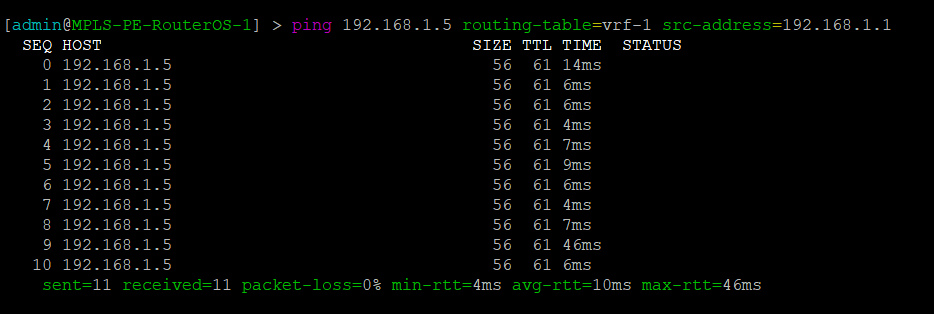
Juniper – mpls forwarding table and vrf routes
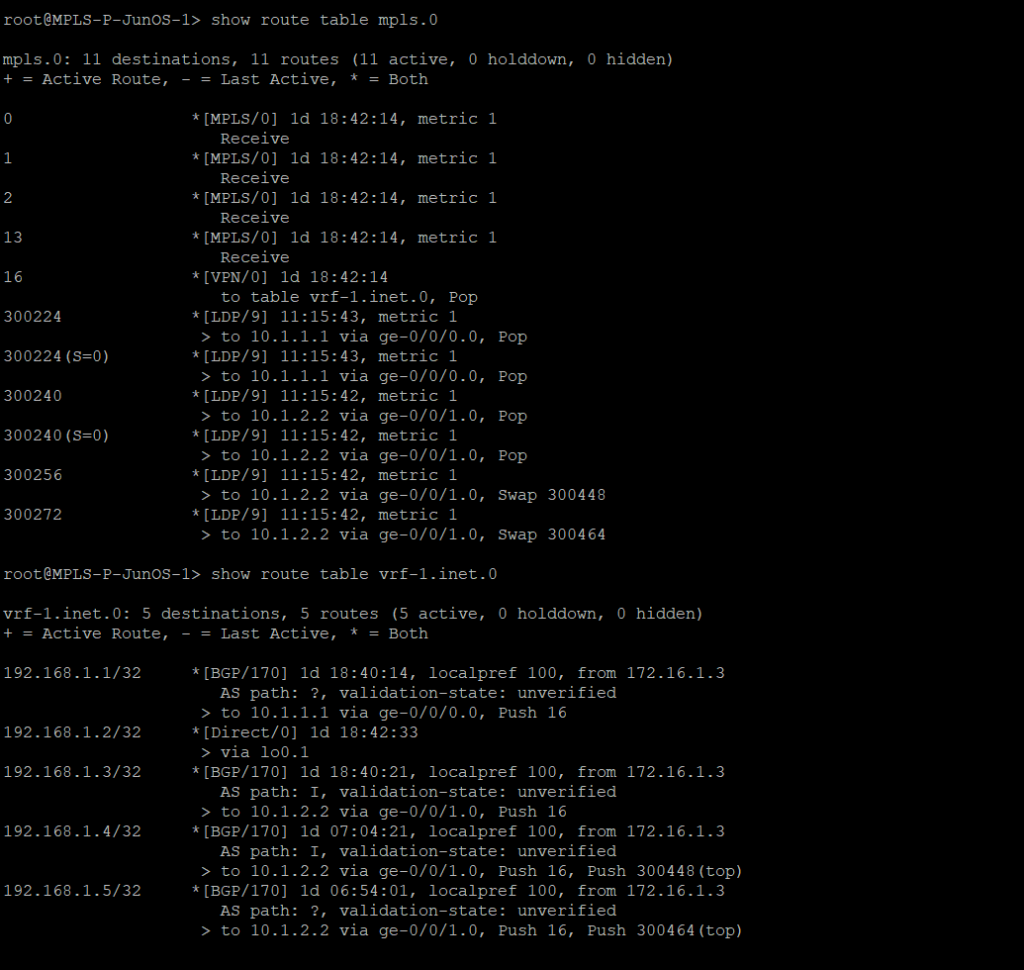
Juniper – Ping PE2 from Juniper MPLS network
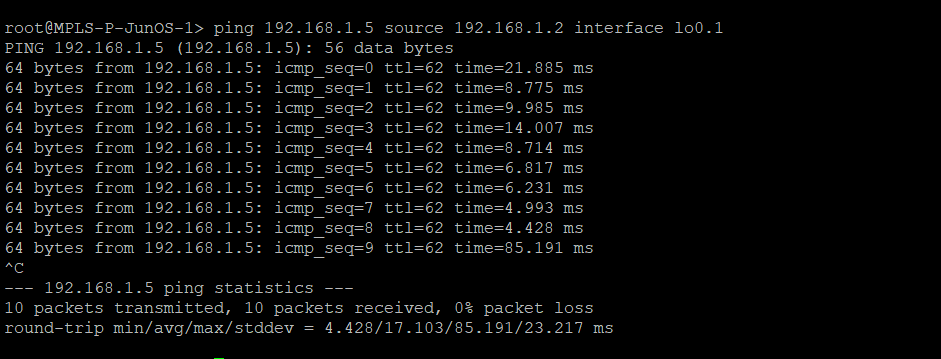
Router configs
MPLS-PE-RouterOS-1
/interface bridge
add name=lo0
add name=lo1
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/routing bgp instance
set default as=8675309
/ip address
add address=10.1.1.1/29 interface=ether1 network=10.1.1.0
add address=192.168.1.1 interface=lo1 network=192.168.1.1
add address=172.16.1.1 interface=lo0 network=172.16.1.1
/ip dhcp-client
add disabled=no interface=ether1
/ip route vrf
add export-route-targets=1.1.1.1:1 import-route-targets=1.1.1.1:1 interfaces=\
lo1 route-distinguisher=1.1.1.1:1 routing-mark=vrf-1
/mpls ldp
set enabled=yes lsr-id=172.16.1.1 transport-address=172.16.1.1
/mpls ldp interface
add interface=ether1
/routing bgp instance vrf
add redistribute-connected=yes routing-mark=vrf-1
/routing bgp peer
add address-families=ip,vpnv4 name=peer1 remote-address=172.16.1.3 remote-as=\
8675309 update-source=lo0
/routing ospf network
add area=backbone network=10.1.1.0/29
add area=backbone network=172.16.1.1/32
/system identity
set name=MPLS-PE-RouterOS-1
MPLS-PE-RouterOS-2
/interface bridge add name=lo0 add name=lo1 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /routing bgp instance set default as=8675309 /ip address add address=10.1.4.2/29 interface=ether1 network=10.1.4.0 add address=192.168.1.5 interface=lo1 network=192.168.1.5 add address=172.16.1.5 interface=lo0 network=172.16.1.5 /ip dhcp-client add disabled=no interface=ether1 /ip route vrf add export-route-targets=1.1.1.1:1 import-route-targets=1.1.1.1:1 interfaces=lo1 route-distinguisher=1.1.1.1:1 routing-mark=vrf-1 /mpls ldp set enabled=yes lsr-id=172.16.1.5 transport-address=172.16.1.5 /mpls ldp interface add interface=ether1 /routing bgp instance vrf add redistribute-connected=yes routing-mark=vrf-1 /routing bgp peer add address-families=ip,vpnv4 name=peer1 remote-address=172.16.1.3 remote-as=8675309 update-source=lo0 /routing ospf network add area=backbone network=10.1.4.0/29 add area=backbone network=172.16.1.5/32 /system identity set name=MPLS-PE-RouterOS-2
MPLS-P-JunOS-1
version 14.1R1.10;
system {
host-name MPLS-P-JunOS-1;
root-authentication {
encrypted-password "$1$kj9Pva8c$R0knN0l873H.UaBUUNYA00"; ## SECRET-DATA
}
syslog {
user * {
any emergency;
}
file messages {
any notice;
authorization info;
}
file interactive-commands {
interactive-commands any;
}
}
}
interfaces {
ge-0/0/0 {
unit 0 {
family inet {
address 10.1.1.2/29;
}
family mpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 10.1.2.1/29;
}
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 172.16.1.2/32;
}
}
unit 1 {
family inet {
address 192.168.1.2/32;
}
}
}
}
routing-options {
router-id 172.16.1.2;
route-distinguisher-id 172.16.1.2;
autonomous-system 8675309;
}
protocols {
mpls {
traffic-engineering mpls-forwarding;
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
bgp {
group rr {
type internal;
local-address 172.16.1.2;
family inet-vpn {
unicast;
}
neighbor 172.16.1.3 {
peer-as 8675309;
}
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface ge-0/0/0.0;
interface ge-0/0/1.0;
interface lo0.0;
}
}
ldp {
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
}
routing-instances {
vrf-1 {
instance-type vrf;
interface lo0.1;
route-distinguisher 1.1.1.1:1;
vrf-target target:1.1.1.1:1;
vrf-table-label;
}
}
MPLS-P-JunOS-2
version 14.1R1.10;
system {
host-name MPLS-P-JunOS-2;
root-authentication {
encrypted-password "$1$g6tJMNPd$f35BMnnPgit/YLshrXd/L1"; ## SECRET-DATA
}
services {
ssh;
}
syslog {
user * {
any emergency;
}
file messages {
any notice;
authorization info;
}
file interactive-commands {
interactive-commands any;
}
}
}
interfaces {
ge-0/0/0 {
unit 0 {
family inet {
address 10.1.2.2/29;
}
family mpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 10.1.3.1/29;
}
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 172.16.1.3/32;
}
}
unit 1 {
family inet {
address 192.168.1.3/32;
}
}
}
}
routing-options {
router-id 172.16.1.3;
route-distinguisher-id 172.16.1.3;
autonomous-system 8675309;
}
protocols {
mpls {
traffic-engineering mpls-forwarding;
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
bgp {
group rr {
type internal;
local-address 172.16.1.3;
family inet-vpn {
unicast;
}
cluster 1.1.1.1;
neighbor 172.16.1.2 {
peer-as 8675309;
}
neighbor 172.16.1.1 {
peer-as 8675309;
}
neighbor 172.16.1.3 {
peer-as 8675309;
}
neighbor 172.16.1.4 {
peer-as 8675309;
}
neighbor 172.16.1.5 {
peer-as 8675309;
}
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface ge-0/0/0.0;
interface ge-0/0/1.0;
interface lo0.0;
}
}
ldp {
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
}
policy-options {
policy-statement import-vrf1 {
term import-term-connected {
from protocol direct;
then accept;
}
term term-reject {
then reject;
}
}
}
routing-instances {
vrf-1 {
instance-type vrf;
interface lo0.1;
route-distinguisher 1.1.1.1:1;
vrf-target target:1.1.1.1:1;
vrf-table-label;
}
}
MPLS-P-JunOS-3
version 14.1R1.10;
system {
host-name MPLS-P-JunOS-3;
root-authentication {
encrypted-password "$1$kj9Pva8c$R0knN0l873H.UaBUUNYA00"; ## SECRET-DATA
}
syslog {
user * {
any emergency;
}
file messages {
any notice;
authorization info;
}
file interactive-commands {
interactive-commands any;
}
}
}
interfaces {
ge-0/0/0 {
unit 0 {
family inet {
address 10.1.3.2/29;
}
family mpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 10.1.4.1/29;
}
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 172.16.1.4/32;
}
}
unit 1 {
family inet {
address 192.168.1.4/32;
}
}
}
}
routing-options {
router-id 172.16.1.4;
route-distinguisher-id 172.16.1.4;
autonomous-system 8675309;
}
protocols {
mpls {
traffic-engineering mpls-forwarding;
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
bgp {
group rr {
type internal;
local-address 172.16.1.4;
family inet-vpn {
unicast;
}
neighbor 172.16.1.3 {
peer-as 8675309;
}
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface ge-0/0/0.0;
interface ge-0/0/1.0;
interface lo0.0;
}
}
ldp {
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
}
routing-instances {
vrf-1 {
instance-type vrf;
interface lo0.1;
route-distinguisher 1.1.1.1:1;
vrf-target target:1.1.1.1:1;
vrf-table-label;
}
}
]]>One of the most difficult configuration challenges for MikroTik equipment seems to be switching and VLANs in the CRS series. Admittedly, the revamp of VLAN configuration for MikroTik CRS switches in early 2018 made things a lot easier. But, sometimes there is still confusion on how to configure VLANs and IP addresses in VLANs with MikroTik RouterOS operating on a switch.
This will only cover VLAN configuration for CRS 3xx series switches in RouterOS as SwitchOS is not nearly as common in operational deployments.
CRS 1xx/2xx series use an older style of configuration and seem to be on the way out so I’m not 100% sure whether or not i’ll write a similar guide on that series.
If you’ve been in networking for a while, you probably started with learning the Cisco CLI. Therefore, it is helpful to compare the commands if you want to implement a network with a MikroTik and Cisco switches.
This is the fourth post in a series that creates a Rosetta stone between IOS and RouterOS. Here are some of the others:
Click here for the first article in this series – “Cisco to MikroTik BGP command translation”
Click here for the second article in this series – “Cisco to MikroTik OSPF command translation”
Click here for the third article in the series – “Cisco to MikroTik MPLS command translation”
While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
Hardware for testing
In the last article, we began using EVE-NG instead of GNS3 to emulate both Cisco IOS and RouterOS so we could compare the different commands and ensure the translation was as close as possible. However in switching, we still have to use real hardware at least in the realm of MikroTik – Cisco has IOSvL2 images that can be used in EVE-NG for switching.

Notes on hardware bridging in the CRS series
Bridging is a very confusing topic within the realm of MikroTik equipment. It is often associated with CPU forwarding and is generally seen as something to be avoided if at all possible.
There are a few reasons for this…
1. Within routers, bridging generally does rely on the CPU for forwarding and the throughput is limited to the size of the CPU.
2. In the previous generation of CRS configuration, bridging was not the best way to configure the switch – using the port master/slave option would trigger hardware forwarding.
After MikroTik revamped the switch config for VLANs in 2018 to utilize the bridge, it more closely resembles the style of configuration for Metro Ethernet Layer 2 as well as vendors like Juniper that use the ‘bridge-domain’ style of config.
Using the bridge for hardware offload of L2 traffic
Note the Hw. Offload verification under this bridge port in the CRS317
It is important to realize that bridging in the CRS, when used for VLAN configuration is actually using the switch ASIC to forward traffic and not the CPU.
In this instance, the bridge is merely used as a familiar configuration tool to tie ports and VLANs together but does in fact allow for the forwarding of traffic in hardware at wirespeed.
Cisco to MikroTik – command translation
| Cisco command | MikroTik Command |
|---|---|
| interface FastEthernet5/0/47 switchport access vlan 100 switchport mode access end | /interface bridge port add bridge=bridge1 interface=sfp-sfpplus1 pvid=100 |
| interface GigabitEthernet5/0/4 switchport trunk encapsulation dot1q switchport trunk allowed vlan 200 switchport mode trunk end | /interface bridge vlan add bridge=bridge1 tagged=sfp-sfpplus1 vlan-ids=200 |
| interface Vlan200 ip address 172.16.1.254 255.255.255.0 end | /interface vlan add interface=bridge1 name=vlan200 vlan-id=200 /interface bridge vlan add bridge=bridge1 tagged=sfp-sfpplus1,bridge1 vlan-ids=200 /ip address add address=172.16.1.254/24 interface=vlan200 network=172.16.1.0 |
| spanning-tree mode mst | /interface bridge add fast-forward=no name=bridge1 priority=0 protocol-mode=mstp region-name=main vlan-filtering=yes |
| interface FastEthernet5/0/47 switchport access vlan 200 switchport mode access spanning-tree portfast end | interface bridge port set edge=yes-discover |
| interface GigabitEthernet5/0/4 switchport trunk encapsulation dot1q switchport trunk allowed vlan 200 switchport mode trunk channel-group 1 mode active end interface Port-channel1 switchport trunk encapsulation dot1q switchport trunk allowed vlan 200 switchport mode trunk end | interface bonding add mode=802.3ad name=Po1 slaves=sfp-sfpplus1,sfp-sfpplus3 \ transmit-hash-policy=layer-2-and-3 /interface bridge vlan add bridge=bridge1 tagged=Po1,bridge1 vlan-ids=200 |
| show mac address-table | interface bridge host print |
| show mac address-table vlan 200 | interface bridge host print where vid=200 |
| show mac address-table interface Gi5/0/4 | interface bridge host print where interface=sfp-sfpplus1 |
| show interfaces trunk show vlan | interface bridge vlan print |
| show spanning-tree | interface bridge monitor |
| show etherchannel summary | interface bonding print detail |
Examples of the MikroTik RouterOS commands from the table above
Untagged switch port
This command will create an untagged or “access” switch port on VLAN 100
[admin@MikroTik] > /interface bridge port add bridge=bridge1 interface=sfp-sfpplus1 pvid=100
Tagged switch port
This command will create a tagged or “trunk” switch port on VLAN 200. Additional VLANs can be tagged on a port by using the same syntax and adding a new VLAN number.
[admin@MikroTik] > /interface bridge vlan add bridge=bridge1 tagged=sfp-sfpplus1 vlan-ids=200
Layer 3 VLAN Interface
Similar to a Cisco SVI (but dependent on the CPU and not an ASIC) this command will create a layer 3 interface on VLAN 200
[admin@MikroTik] > /interface vlan add interface=bridge1 name=vlan200 vlan-id=200 /interface bridge vlan add bridge=bridge1 tagged=sfp-sfpplus1,bridge1 vlan-ids=200 /ip address add address=172.16.1.254/24 interface=vlan200 network=172.16.1.0
Multiple STP
This command will set the bridge loop prevention protocol to Multiple Spanning Tree. As a general observation, MSTP tends to be the most compatible across vendors as some vendors like Cisco use a proprietary version of Rapid STP.
[admin@MikroTik] > /interface bridge add fast-forward=no name=bridge1 priority=0 protocol-mode=mstp region-name=main vlan-filtering=yes
STP Edge port
This is referred to as “portfast” in the Cisco world and allows a port facing a device that isn’t a bridge or a switch to transition immediately to forwarding but if it detects a BPDU, it will revert to normal STP operation. (this is the difference between edge=yes and edge=yes-discover)
[admin@MikroTik] > /interface bridge port set edge=yes-discover
LACP Bonding
This command will create a bonding interface which is similar to a Port Channel in Cisco’s switches. Two or more physical interfaces can be selected to bond together and then the 802.3ad mode is selected which is LACP. You can also select the hashing policy and ideally it should match what the device on the other end is set for to get the best distribution of traffic and avoid interoperability issues.
[admin@MikroTik] > /interface bonding add mode=802.3ad name=Po1 slaves=sfp-sfpplus1,sfp-sfpplus3 \ transmit-hash-policy=layer-2-and-3 /interface bridge vlan add bridge=bridge1 tagged=Po1,bridge1 vlan-ids=200
View the MAC table of the switch
This print command will show all learned MAC addresses and associated VLANs in the CAM table of the switch
[admin@IPA-LAB-CRS-317] > interface bridge host print Flags: X - disabled, I - invalid, D - dynamic, L - local, E - external # MAC-ADDRESS VID ON-INTERFACE BRIDGE AGE 0 DL 64:D1:54:F0:0E:46 Po1 bridge1 1 DL 64:D1:54:F0:0E:47 sfp-sfpplus2 bridge1 2 D E 04:FE:7F:5C:5D:9C 1 Po1 bridge1 3 DL 64:D1:54:F0:0E:46 1 Po1 bridge1 4 D 00:0C:42:B2:A6:3D 200 sfp-sfpplus2 bridge1 52s 5 D E 4C:5E:0C:23:DF:50 200 Po1 bridge1 6 DL 64:D1:54:F0:0E:46 200 bridge1 bridge1 7 DL 64:D1:54:F0:0E:47 200 sfp-sfpplus2 bridge1
View the MAC table for VLAN 200 in the switch
This print command will show all learned MAC addresses in VLAN 200.
[admin@IPA-LAB-CRS-317] > interface bridge host print where vid=200 Flags: X - disabled, I - invalid, D - dynamic, L - local, E - external # MAC-ADDRESS VID ON-INTERFACE BRIDGE AGE 0 D 00:0C:42:B2:A6:3D 200 sfp-sfpplus2 bridge1 51s 1 D E 4C:5E:0C:23:DF:50 200 Po1 bridge1 2 DL 64:D1:54:F0:0E:46 200 bridge1 bridge1 3 DL 64:D1:54:F0:0E:47 200 sfp-sfpplus2 bridge1
View the MAC table for bonding interface Po1 in the switch
This print command will show all learned MAC addresses on port Po1.
[admin@IPA-LAB-CRS-317] > interface bridge host print where interface=Po1 Flags: X - disabled, I - invalid, D - dynamic, L - local, E - external # MAC-ADDRESS VID ON-INTERFACE BRIDGE AGE 0 DL 64:D1:54:F0:0E:46 Po1 bridge1 1 D E 04:FE:7F:5C:5D:9C 1 Po1 bridge1 2 DL 64:D1:54:F0:0E:46 1 Po1 bridge1 3 D E 4C:5E:0C:23:DF:50 200 Po1 bridge1
View the current VLANs configured in the switch
The bridge vlan print command will show all configured VLANs in the switch.
[admin@IPA-LAB-CRS-317] > interface bridge vlan print
Flags: X - disabled, D - dynamic
# BRIDGE VLAN-IDS CURRENT-TAGGED CURRENT-UNTAGGED
0 bridge1 200 bridge1 sfp-sfpplus2
Po1
1 D bridge1 1 bridge1
Po1
View Bridge Spanning Tree information
The bridge monitor command will show the configuration details and current state of spanning tree including the root bridge and root port
[admin@IPA-LAB-CRS-317] > interface bridge monitor
numbers: 0
state: enabled
current-mac-address: 64:D1:54:F0:0E:46
root-bridge: yes
root-bridge-id: 0.64:D1:54:F0:0E:46
regional-root-bridge-id: 0.64:D1:54:F0:0E:46
root-path-cost: 0
root-port: none
port-count: 2
designated-port-count: 2
mst-config-digest: ac36177f50283cd4b83821d8ab26de62
LACP Bonding information
This command will show the details of the LACP configuration and whether the bonding interface is running which indicates a valid LACP neighbor.
[admin@IPA-LAB-CRS-317] > interface bonding print detail
Flags: X - disabled, R - running
0 R name="Po1" mtu=1500 mac-address=64:D1:54:F0:0E:46 arp=enabled arp-timeout=auto
slaves=sfp-sfpplus1,sfp-sfpplus3 mode=802.3ad primary=none link-monitoring=mii
arp-interval=100ms arp-ip-targets="" mii-interval=100ms down-delay=0ms up-delay=0ms
lacp-rate=30secs transmit-hash-policy=layer-2-and-3 min-links=0
]]>The challenge of adding IPv6 to your WISP
IPv6 is one of those technologies that can feel pretty overwhelming, but it doesn’t have to be. Many of the same ideas and concepts learned in IPv4 networking still apply.
This guide is meant to give you an overview of an example IPv6 addressing plan for an entire WISP as well as the config needed in MikroTik to deploy IPv6 from a core router all the way to a subscriber device.
Benefits of adding IPv6
- Public addressing for all subscribers – reduced need for NAT
- Regulatory compliance – public addressing that is persistent makes it much easier to be compliant for things like CALEA
- Reduced complaints from gamers – Xbox and Playstation both have IPv6 networks and prefer IPv6. This reduces complaints from customers who have gaming consoles that have detected an “improper” NAT configuration.
- Increased security – IPv6, while not impervious to security threats makes it much harder for attackers to scan IPs due to the sheer size of the IP space. If using privacy extensions with SLAAC, it also makes it much harder to target someone online as the IP address seen on the internet changes randomly.
- Improved real time communications – one way audio and video issues are often caused by NAT. Using end to end connectivity on public addressing improves the reliability of IP voice and video when used on IPv6
- Web scale content (Netflix, Facebook, Google, etc) is IPv6 enabled which means a large portion of your traffic will shift to native IPv6 once dual stack is enabled.
IPv6 Addressing
One of the things i’ve learned about IPv6 is that addressing plans seem to spark epic debates about the waste of addresses and what size prefix an end subscriber should get.
Although this lab could have easily been done with a /56 at the tower and /53 at each AP, I decided to use RIPEs recommendations from their guide on IPv6 best operational practices.
This is mainly to keep the focus of the article on actually getting IPv6 deployed and not focusing on the addressing.
Dual Stack
For simplicity, the IPv4 config is not shown, but the recommended design for an operational WISP is to implement IPv4 and IPv6 side by side in a Dual Stack configuration.
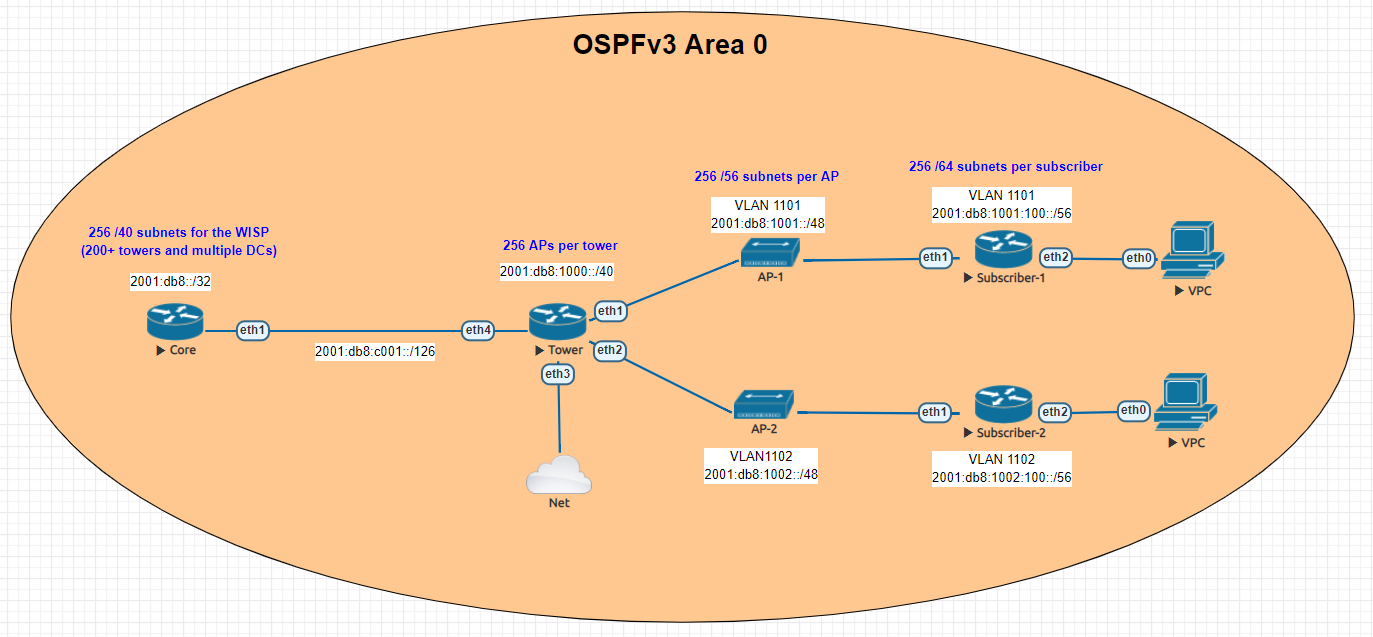
Lab Overview
The lab is designed to illustrate most of the operational aspects of IPv6 in a WISP using MikroTik CHR routers in EVE-NG. This includes:
- DHCPv6 and Prefix Delegation (PD)
- OSPFv3 single area configuration and origination of a default route
- Subscriber router example with SLAAC
Core Router

In the lab, the core router is shown directly connected to the tower for simplicity, in your WISP, there may be multiple towers between the core and the end of the network.
The concept, however is the same – use /126 addressing to connect towers for OSPFv3.
Note that OSPFv3 still requires a router-id in dotted decimal format, even though the address you put int doesn’t have to actually exist – for consistency however, use the IPv4 loopback of the router for the router id.
The internet connectivity isn’t shown in this lab, but your ISP will give you a /126 address to connect to your border router and either peer with BGP or the provider can route the /32 prefix to you.
Config
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/routing ospf-v3 instance
set [ find default=yes ] distribute-default=always-as-type-1 router-id=\
100.127.1.1
/ip dhcp-client
add disabled=no interface=ether1
/ipv6 address
add address=2001:db8:c001::1/126 advertise=no interface=ether1
/routing ospf-v3 interface
add area=backbone interface=ether1
/system identity
set name=Core
/tool romon
set enabled=yes
Tower Router
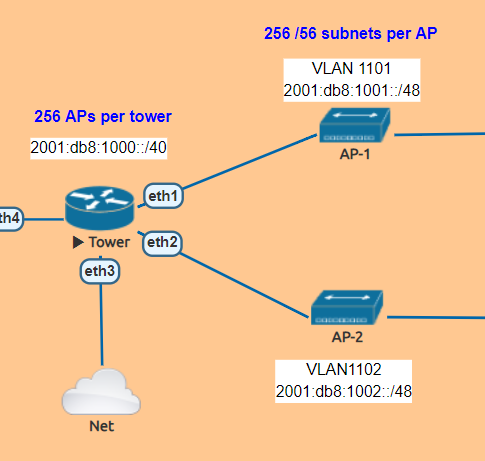
The tower router is handling most of the work as it is responsible for DHCPv6 and Prefix Delegation as well as advertising the /48 AP subnets into OSPF
In this lab , the APs are split into separate VLANs (with dual stack, IPv4 would exist on the same VLAN).
The router is configured to hand out /56 prefixes to the end subscriber using a pool of /48 per AP.
Because Prefix Delegation is being utilized, a dynamic static route is created for each /56 the DHCPv6 server hands out which eliminates the need to use a routing protocol.
Prefix Delegation in action
This example shows the prefixes allocated by the router and the dynamic static routes created
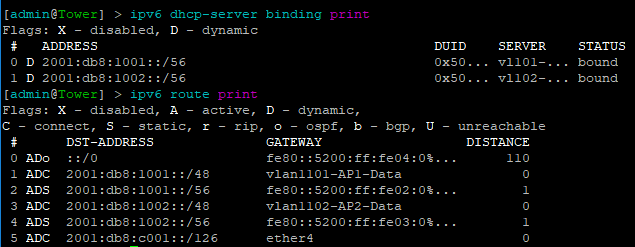
Config
/interface bridge
add name=Lo0
/interface vlan
add interface=ether1 name=vlan1101-AP1-Data vlan-id=1101
add interface=ether2 name=vlan1102-AP2-Data vlan-id=1102
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ipv6 dhcp-server
add address-pool=vl101-v6-pd-pool interface=vlan1101-AP1-Data name=\
vl101-v6-pd
add address-pool=vl102-v6-pd-pool interface=vlan1102-AP2-Data name=\
vl102-v6-pd
/ipv6 pool
add comment="VLAN1101 IPv6 prefix delegation pool" name=vl101-v6-pd-pool \
prefix=2001:db8:1001::/48 prefix-length=56
add comment="VLAN1102 IPv6 prefix delegation pool" name=vl102-v6-pd-pool \
prefix=2001:db8:1002::/48 prefix-length=56
/routing ospf-v3 instance
set [ find default=yes ] router-id=100.127.1.2
/ip dhcp-client
add disabled=no interface=ether1
/ipv6 address
add address=2001:db8:1001::1/48 advertise=no interface=vlan1101-AP1-Data
add address=2001:db8:1002::1/48 advertise=no interface=vlan1102-AP2-Data
add address=2001:db8:c001::2/126 advertise=no interface=ether4
/ipv6 nd
add interface=vlan1101-AP1-Data managed-address-configuration=yes \
other-configuration=yes
add interface=vlan1102-AP2-Data managed-address-configuration=yes \
other-configuration=yes
/ipv6 nd prefix
add autonomous=no interface=vlan1101-AP1-Data
add autonomous=no interface=vlan1102-AP2-Data
/routing ospf-v3 interface
add area=backbone interface=ether4
add area=backbone interface=vlan1101-AP1-Data
add area=backbone interface=vlan1102-AP2-Data
add area=backbone passive=yes
/system identity
set name=Tower
/tool romon
set enabled=yes
Subscriber Routers

For simplicity, MikroTik is used as the Subscriber or CPE router to provide an example of how the /56 prefix is received from the tower router and handed off to devices inside the subscriber’s home.
In this lab, the “WAN” interface or ether1 has a DHCPv6 client configured to receive the prefix from the tower router.
Ether2 or the “LAN” side, which would include a bridge of the the wireless/wired interfaces in a real router is configured with a dynamic /64 from the /56 pool and is set for SLAAC to give devices on this segment an IPv6 address.
DHCPv6 client and subscriber addresses/routes
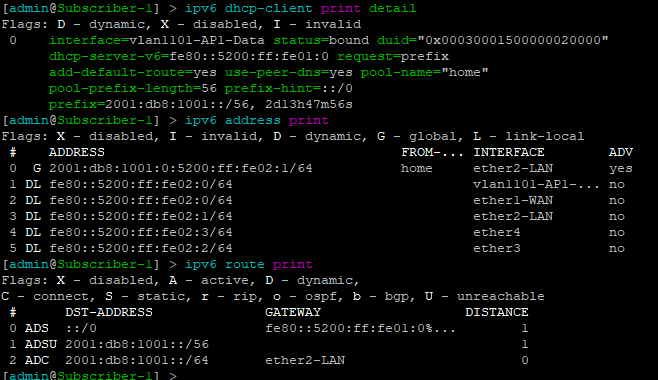
Config – Subscriber 1
/interface ethernet
set [ find default-name=ether1 ] name=ether1-WAN
set [ find default-name=ether2 ] name=ether2-LAN
/interface vlan
add interface=ether1-WAN name=vlan1101-AP1-Data vlan-id=1101
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip dhcp-client
add disabled=no interface=ether1-WAN
/ipv6 address
add eui-64=yes from-pool=home interface=ether2-LAN
/ipv6 dhcp-client
add add-default-route=yes interface=vlan1101-AP1-Data pool-name=home \
pool-prefix-length=56 request=prefix
/ipv6 nd
add hop-limit=64 interface=ether2-LAN
/system identity
set name=Subscriber-1
/tool romon
set enabled=yes
Config – Subscriber 2
/interface ethernet
set [ find default-name=ether1 ] name=ether1-WAN
set [ find default-name=ether2 ] name=ether2-LAN
/interface vlan
add interface=ether1-WAN name=vlan1102-AP2-Data vlan-id=1102
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/ip dhcp-client
add disabled=no interface=ether1-WAN
/ipv6 address
add eui-64=yes from-pool=home interface=ether2-LAN
/ipv6 dhcp-client
add add-default-route=yes interface=vlan1102-AP2-Data pool-name=home \
pool-prefix-length=56 request=prefix
/ipv6 nd
add hop-limit=64 interface=ether2-LAN
/system identity
set name=Subscriber-2
/tool romon
set enabled=yes
Subscriber Device
EVE-NG has a small Linux image that can be used as a host called VPC or virtual PC. This allows us to put a device on ether2 and test end to end reachability back to the core router.
SLAAC addressing example

Ping test back to the core router
Success!!!!!!!!
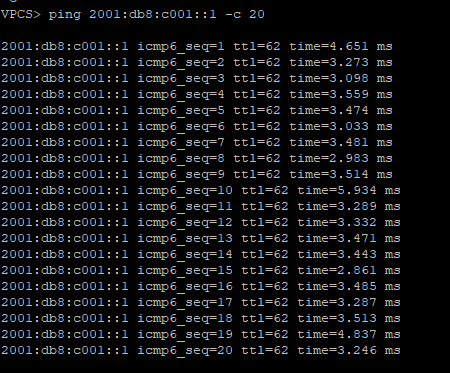
ISPs that use MikroTik are always looking for new ways to deliver services to customers and expand their offerings. Delivering Layer 2 at scale for customers is a design challenge that comes up frequently.
While it’s easy enough to build a VLAN nested inside of another VLAN (see below), this requires you to build all of the VLANs a customer wants to use into the PE router or handoff switch.
However, if you have a client that needs a layer 2 service delivered to two or more points and wants to be able to treat it just like an 802.1q trunk and add VLANs in an ad-hoc way, then using the S-Tag feature in RouterOS along with VPLS transport is a great option.
What’s the S-tag do???
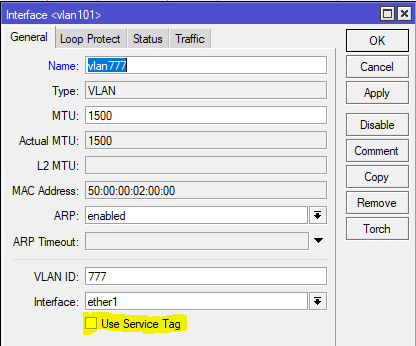
Clients will often ask me “what’s the S-Tag check box for?”
So a little background on this, there is a protocol for using outer and inner VLAN tags specified in IEEE 802.1ad that uses Service Tag (or S-Tag) to denote the outer VLAN tag used to transport Customer Tags (or C-Tags).
What makes the S-Tag/C-Tag a little bit different is that it actually changes the ethertype of the Frame.
| Protocol | Ethertype |
|---|---|
| 802.1q (Normal VLAN Tags) | 0x8100 |
| 802.1ad (S-tag) | 0x88a8 |
Here is an overview of the frame format of each and links to the Metro Ethernet Forum Wiki for more info.
S-Tag
https://wiki.mef.net/display/CESG/S-Tag
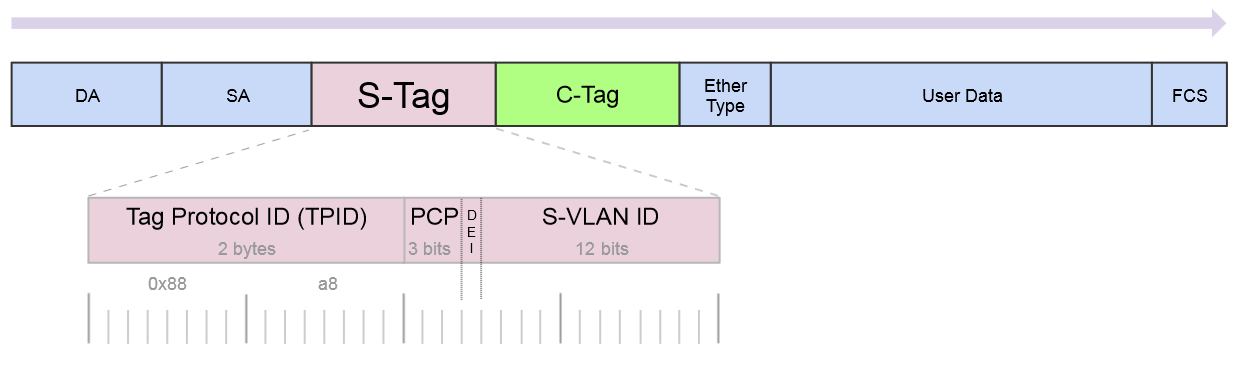
C-Tag
https://wiki.mef.net/display/CESG/C-Tag
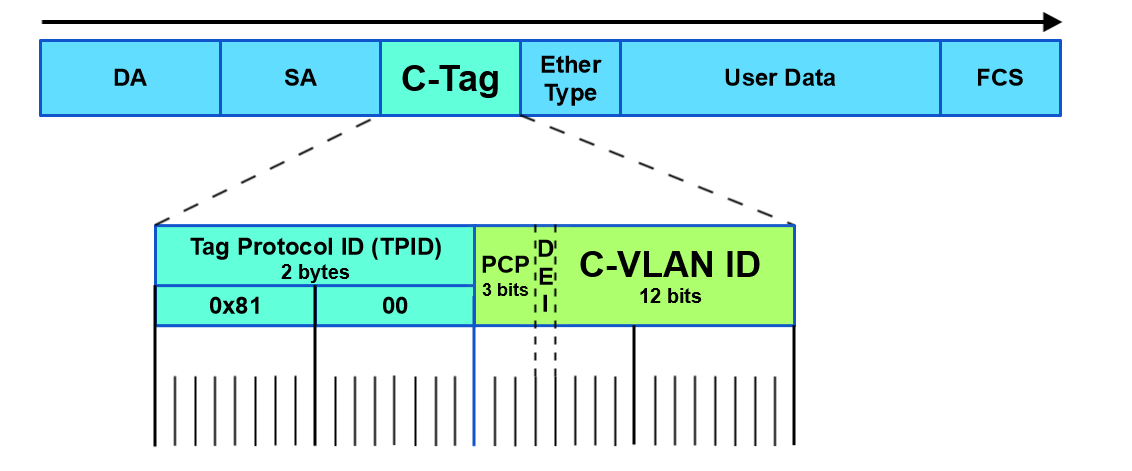
Lab Scenario
Here is a very common example of a deployment for a Layer 2 service to an end customer that rides on top of the ISP MPLS core.
In this lab we are using Cisco switches trunked to each other using VLAN 101 and 201 over a VPLS pseudowire with an S-Tag of 777.
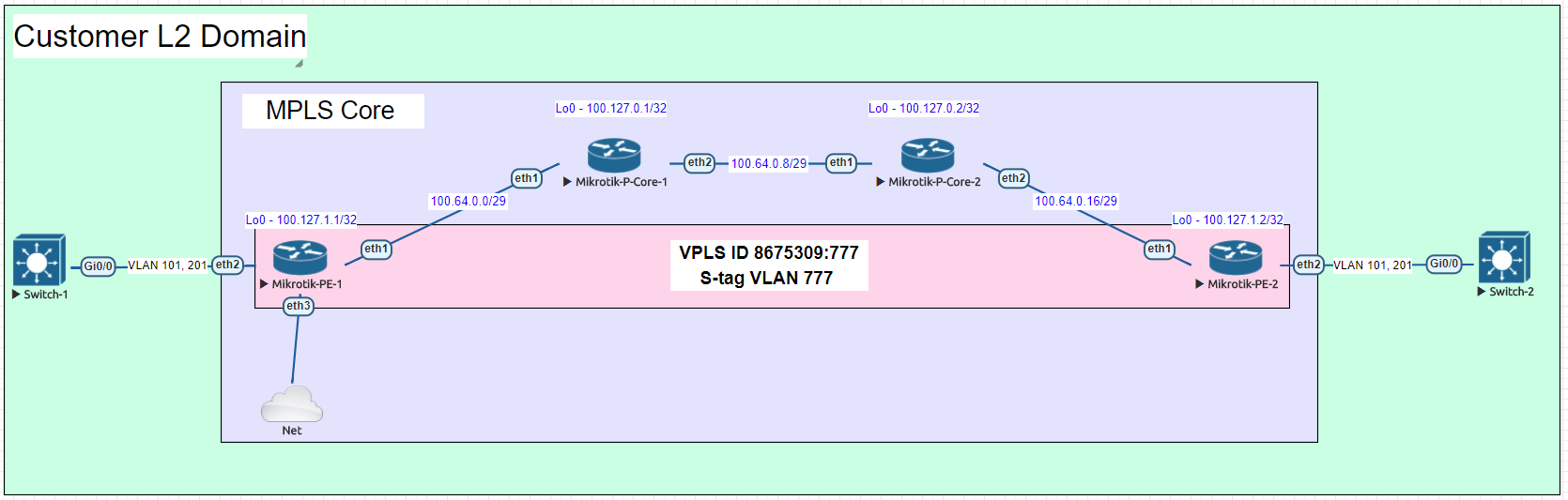
After configuring the P routers, PE routers and Cisco switches, let’s take a look at the Cisco switch and see if we can ping the SVI on the other switch on both trunked VLANs.
Here are the subnets used on the customer side:
Now let’s ping the .2 address for each VLAN on Switch-2
VLAN 101

VLAN 201

Notes on MTU
A note on MTU sizing, in order to hand off a 1500 byte packet with VPLS, you normally need an MPLS and L2MTU of 1530 bytes. In order to pass a second VLAN tag you’ll want to make sure your network equipment can go up to 1534 for Layer 2 and MPLS MTUs to pass 1500 byte packet with S-Tag.
Configs for the lab
In the section below, here are all the configs for this deployment
Cisco Switch-1
version 15.2 service timestamps debug datetime msec service timestamps log datetime msec no service password-encryption service compress-config ! hostname Switch-1 ! boot-start-marker boot-end-marker ! ! ! no aaa new-model ! ! ! ! ! ! ! ! ip cef no ipv6 cef ! ! ! spanning-tree mode pvst spanning-tree extend system-id ! vlan internal allocation policy ascending ! ! ! ! ! ! ! ! ! ! ! ! ! ! interface GigabitEthernet0/0 switchport trunk encapsulation dot1q switchport mode trunk media-type rj45 negotiation auto ! interface GigabitEthernet0/1 media-type rj45 negotiation auto ! interface GigabitEthernet0/2 media-type rj45 negotiation auto ! interface GigabitEthernet0/3 media-type rj45 negotiation auto ! interface GigabitEthernet1/0 media-type rj45 negotiation auto ! interface GigabitEthernet1/1 media-type rj45 negotiation auto ! interface GigabitEthernet1/2 media-type rj45 negotiation auto ! interface GigabitEthernet1/3 media-type rj45 negotiation auto ! interface Vlan101 description customer-vlan ip address 192.168.101.1 255.255.255.0 ! interface Vlan201 description customer vlan 2 ip address 192.168.201.1 255.255.255.0 ! ip forward-protocol nd ! no ip http server no ip http secure-server ! ! ! ! ! ! control-plane ! banner exec ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner incoming ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner login ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C ! line con 0 line aux 0 line vty 0 4 ! ! end
Cisco Switch-2
version 15.2 service timestamps debug datetime msec service timestamps log datetime msec no service password-encryption service compress-config ! hostname Switch-2 ! boot-start-marker boot-end-marker ! ! ! no aaa new-model ! ! ! ! ! ! ! ! ip cef no ipv6 cef ! ! ! spanning-tree mode pvst spanning-tree extend system-id ! vlan internal allocation policy ascending ! ! ! ! ! ! ! ! ! ! ! ! ! ! interface GigabitEthernet0/0 switchport trunk encapsulation dot1q switchport mode trunk media-type rj45 negotiation auto ! interface GigabitEthernet0/1 media-type rj45 negotiation auto ! interface GigabitEthernet0/2 media-type rj45 negotiation auto ! interface GigabitEthernet0/3 media-type rj45 negotiation auto ! interface GigabitEthernet1/0 media-type rj45 negotiation auto ! interface GigabitEthernet1/1 media-type rj45 negotiation auto ! interface GigabitEthernet1/2 media-type rj45 negotiation auto ! interface GigabitEthernet1/3 media-type rj45 negotiation auto ! interface Vlan101 description customer-vlan ip address 192.168.101.2 255.255.255.0 ! interface Vlan201 description customer vlan 2 ip address 192.168.201.2 255.255.255.0 ! ip forward-protocol nd ! no ip http server no ip http secure-server ! ! ! ! ! ! control-plane ! banner exec ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner incoming ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner login ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C ! line con 0 line aux 0 line vty 0 4 ! ! end
MikroTik PE-1
/interface bridge
add name=Lo0
add name=vpls-bridge-vlan-777
/interface vpls
add disabled=no l2mtu=1500 mac-address=02:D5:C2:72:3A:1A name=vpls777
pw-type=tagged-ethernet remote-peer=100.127.1.2 vpls-id=8675309:777
/ip neighbor discovery
set ether2 discover=no
/interface vlan
add interface=vpls777 name=vlan777 use-service-tag=yes vlan-id=777
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/routing ospf instance
add name=ospf1 router-id=100.127.1.1
/interface bridge port
add bridge=Lo0 interface=ether2
add bridge=Lo0 interface=vlan777
/ip address
add address=100.64.0.1/29 interface=ether1 network=100.64.0.0
add address=100.127.1.1 interface=Lo0 network=100.127.1.1
/ip dhcp-client
add disabled=no interface=ether1
/mpls interface
set [ find default=yes ] mpls-mtu=1534
/mpls ldp
set enabled=yes lsr-id=100.127.1.1 transport-address=100.127.1.1
/mpls ldp interface
add interface=ether1 transport-address=100.127.1.1
/routing ospf network
add area=backbone network=100.64.0.0/29
add area=backbone network=100.127.1.1/32
/system identity
set name=MikroTik-PE-1
/tool romon
set enabled=yes
MikroTik PE-2
/interface bridge
add name=Lo0
add name=vpls-bridge-vlan-777
/interface vpls
add disabled=no l2mtu=1500 mac-address=02:C1:71:EB:0E:E7 name=vpls777
pw-type=tagged-ethernet remote-peer=100.127.1.1 vpls-id=8675309:777
/ip neighbor discovery
set ether2 discover=no
/interface vlan
add interface=vpls777 name=vlan777-s-tag use-service-tag=yes vlan-id=777
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/routing ospf instance
add name=ospf1 router-id=100.127.1.2
/interface bridge port
add bridge=Lo0 interface=vlan777-s-tag
add bridge=Lo0 interface=ether2
/ip address
add address=100.64.0.18/29 interface=ether1 network=100.64.0.16
add address=100.127.1.2 interface=Lo0 network=100.127.1.2
/ip dhcp-client
add dhcp-options=hostname,clientid disabled=no interface=ether1
/mpls interface
set [ find default=yes ] mpls-mtu=1534
/mpls ldp
set enabled=yes lsr-id=100.127.1.2 transport-address=100.127.1.2
/mpls ldp interface
add interface=ether1 transport-address=100.127.1.2
/routing ospf network
add area=backbone network=100.64.0.16/29
add area=backbone network=100.127.1.2/32
/system identity
set name=MikroTik-PE-2
/tool romon
set enabled=yes
MikroTik P-CORE-1
/interface bridge add name=Lo0 /interface vlan add interface=ether1 name=vlan101 vlan-id=777 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /routing ospf instance set [ find default=yes ] router-id=100.127.0.1 /ip address add address=100.64.0.2/29 interface=ether1 network=100.64.0.0 add address=100.127.0.1 interface=Lo0 network=100.127.0.1 add address=100.64.0.9/29 interface=ether2 network=100.64.0.8 /ip dhcp-client add dhcp-options=hostname,clientid disabled=no interface=ether1 /mpls interface set [ find default=yes ] mpls-mtu=1534 /mpls ldp set enabled=yes lsr-id=100.127.0.1 transport-address=100.127.0.1 /mpls ldp interface add interface=ether1 transport-address=100.127.0.1 add interface=ether2 transport-address=100.127.0.1 /routing ospf network add area=backbone network=100.64.0.0/29 add area=backbone network=100.127.0.1/32 add area=backbone network=100.64.0.8/29 /system identity set name=MikroTik-P-Core-1 /tool romon set enabled=yes
MikroTik P-CORE-2
/interface bridge add name=Lo0 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /routing ospf instance set [ find default=yes ] router-id=100.127.0.2 /ip address add address=100.64.0.10/29 interface=ether1 network=100.64.0.8 add address=100.127.0.2 interface=Lo0 network=100.127.0.2 add address=100.64.0.17/29 interface=ether2 network=100.64.0.16 /ip dhcp-client add dhcp-options=hostname,clientid disabled=no interface=ether1 /mpls interface set [ find default=yes ] mpls-mtu=1534 /mpls ldp set enabled=yes lsr-id=100.127.0.2 transport-address=100.127.0.2 /mpls ldp interface add interface=ether1 transport-address=100.127.0.2 add interface=ether2 transport-address=100.127.0.2 /routing ospf network add area=backbone network=100.64.0.8/29 add area=backbone network=100.127.0.2/32 add area=backbone network=100.64.0.16/29 /system identity set name=MikroTik-P-Core-2 /tool romon]]>

.
Funding a new WISP
There are a number of ways to fund a startup Wireless Internet Service Provider (WISP), but the two we most commonly see are self-funded by individuals/partners or by leveraging private equity (PE) money.
Private equity has become increasingly popular in the last few years if we are to use our consulting clients as a basis for comparison.
It’s not hard to see why, while you can (and many do) start a WISP on a shoestring budget, getting a significant chunk of initial funding to cover the costs of tower construction/leasing, network equipment, sales/marketing, etc is very attractive as it allows a WISP to build a network that might otherwise take several years of organic growth to achieve.
Network Engineering – the missing ingredient
Many startup WISPs are often borne out of necessity – fast, reliable or economical Internet access – one or more of these is missing in the areas we see WISPs develop.
Typically the stakeholders come from a variety of backgrounds some of which are technical and some aren’t – all of them, however, share a vision of building out Internet access and solving problems that are unique to their corner of the world.
Out of that group, probably less than 5% come out of the ranks of professional network engineers.
And this isn’t to say that you need to be a network engineer to start a successful WISP, quite the contrary, the most successful WISPs are formed by people who understand what a well-run business looks like.
But when you’re in the business of building and selling access to a service provider IP network, at some point, you will benefit from having a network engineer as part of your team – whether that happens in the beginning or down the road is the core focus of this article.

.
Build it and then fix it
Build it and then fix it later is probably the most common approach when it comes to the network design of a new WISP. Many startups (understandably) want to save money anywhere they can – consultants or tech labor costs can be steep when money is only going out and not coming in.
“Let’s just get it up and running so we can get some revenue and then we’ll fix things”
I’ve probably heard this phrase uttered a few hundred times when working with startup WISPs over the last decade.
This is the main reason bridged networks are so commonly found in startup WISPs. The network engineering is far simpler when everything is a single network and broadcast domain.
And it’s easy to see the allure of this approach – No subnetting, VLANs, routing protocols or advanced protocols like MPLS are required.
However, this is often the beginning of a painful journey for many WISPs that will result in an initial network redesign somewhere between 500 to 1000 subscribers as the broadcast domain will reach a point where performance starts to suffer and the mad dash to fix it begins.
The cost of redesign
Network redesigns are costly in the form of equipment, labor, downtime and lost opportunities. One of the key pieces of advice we give to prospective clients whether we work for them or not is to get someone that is a network professional involved with the network design from day one – whether it’s a consultant or an in house network engineer.
When we come in and perform a network redesign, there will be elements we use common to most ISP networks like:
- A Subnet/VLAN plan that allows for both growth at a tower and scaling of multiple towers
- Use of an IPAM/DCIM like Netbox
- When to use RFC 1918 and 6598 IP space vs. Public IP space
- IPv4/IPv6 and CGN
- Capacity planning – what speeds and feeds are needed now and in the future
- L2/L3 design for Data Centers/PoPs
- L2/L3 design for towers and aggregation networks
- Routing architecture design that includes an IGP like OSPF along with BGP and MPLS
- Planning for Billing, DNS, DHCP and other services.
- Security and DDoS planning
Typically, the response we get from most clients is something like “wow, I wish I’d known about all of this before I started and just done it on day one – it would have been cheaper”
The cost of going through the redesign exercise can be substantial, even for a very small WISP, it can exceed $10k and for larger WISPs, it can easily be $100k or more.
It might seem like the list above is fairly complex for a very small network with only one tower and one Internet feed, but the reality is that if you build a design that’s ready to scale and template on day one, it will be far easier to grow quickly and not have to forklift those components in at a later date with large out of pocket costs.

.
How does Private Equity fit in?
When getting private equity firms to fund a new WISP, there are a number of budget items that go into the business plan but a plan to hire network engineers or consultants is rarely among them…why?
Many of the stakeholders involved in WISPs are often savvy tech people that are able to learn and digest new things quickly. I believe there is a perception that it’s less costly to start with a simplistic network design using the existing team and learn ‘on the fly’ rather than hire an experienced networker as a consultant or especially as an employee.
Before I get too much hate mail, there are plenty of success stories of WISPs that were built from the ground up that had to learn on the fly and were able to build a great network – so i’m not trying to paint a picture that it can’t ever be done.
The trial and error approach has a better chance of succeeding when you’re self-funded as you can gauge when you need help instead of getting hammered by investors when the network isn’t working well.
Private equity firms, however, are looking for a predictable return on their investment and skipping proper network design and planning with an experienced professional often puts a huge dent in the projected ROI for a number of reasons like:
- Poor network performance which leads to slow or even negative subscriber growth
- Higher install and truck roll costs due to the use of non-standardized and validated templates for subscribers
- Network redesign costs
- Outages due to lack of HA design
- Excessive purchase of equipment due to lack of formal capacity planning and understanding of equipment use cases.
And the list keeps going. These are just a few of the real-world examples we have seen that get categorized as “unforeseen costs.”
Experience is the key for investors to controlling costs and building a reliable production network that will produce a consistent ROI.
The key takeaway here for private equity firms and entrepreneurs that are seeking money via PE is to get professional network engineering incorporated into the budget at the beginning to minimize the list of “unforseen costs” in the first 180 to 365 days of network operation.
Whether you hire a consulting firm or a a full or part time network engineer to assist with this step, the key is to get someone who has experience with ISP operations and design – with WISPs especially.
The money saved from using a design validated by a professional will be likely be substantial and rapid growth is far easier when the network is built right from the beginning – both of these put the PE Firm and the WISP Owner/Operators in a great position to succeed and return value to investors in a shorter amount of time.
]]>
One of the challenges service providers have faced in the last decade is lowering the cost per port or per MB while maintaining the same level of availability and service level.
And then add to that the constant pressure from subscribers to increase capacity and meet the rising demand for realtime content.
This can be an especially daunting task when routers with the feature sets ISPs need cost an absolute fortune – especially as new port speeds are released.

Whitebox, also called disaggregated networking, has started changing the rules of the game. ISPs are working to figure out how to integrate and move to production on disaggregated models to lower the cost of investing in higher speeds and feeds.
Whitebox often faces the perception problem of being more difficult to implement than traditional vendors – which is exactly why I wanted to highlight some of the work we’ve been doing at iparchitechs.com integrating whitebox into production ISP networks using IP Infusion’s OcNOS.
Things are really starting to heat up in the disaggregagted network space after the announcement by Amazon a few days ago that it intends to build and sell whitebox switches.
As I write this, I’m headed to Networking Field Day 18 where IP Infusion will be presenting and I expect whitebox will again be a hot topic.
This will be the second time IPI has presented at Networking Field Day but the first time that I’ve had a chance to see them present firsthand.
It’s especially exciting for me as I work on implementing IPI on a regular basis and integrating OcNOS into client networks.
What is OcNOS?

IP Infusion has been making network operating systems (NOS) for more than 20 years under the banner of its whitelabel NOS – ZebOS.
As disaggregated networking started to become popular, IPI created OcNOS which is an ONIE compatible NOS using elements and experience from 20 years of software development with ZebOS.
There is a great overview of OcNOS from Networking Field Day 15 here:
What does a production OcNOS based MPLS network look like?
Here is an overview of the EVE-NG lab we built based on an actual implementation.
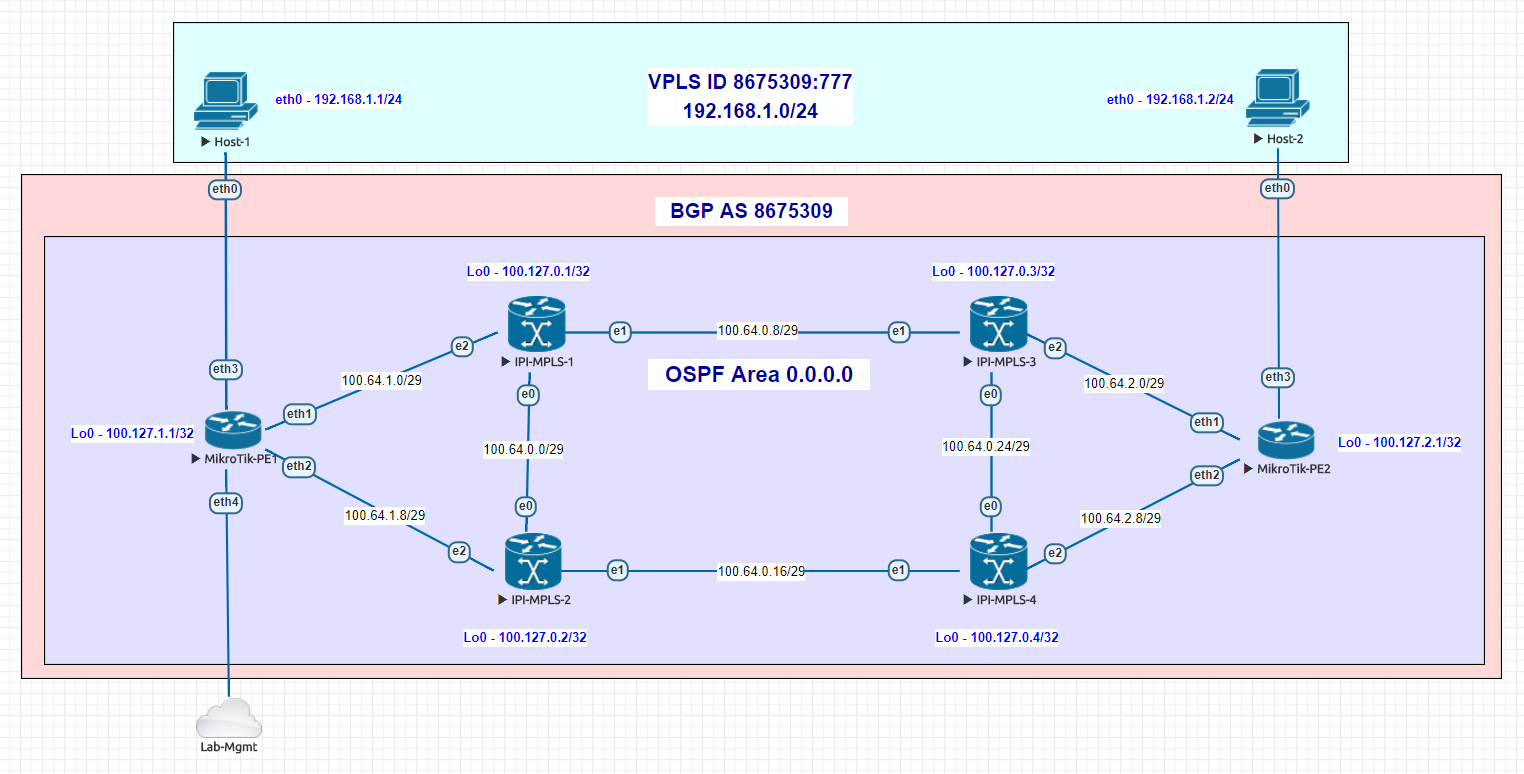
Use case – Building an MPLS core to deliver L2 overlay services
Although certainly not a new use case or implementation, MPLS and VPLS are very expensive to deploy using major vendors and are still a fundamental requirement for most ISPs.
This is where IPI really shines as they have feature sets like MPLS FRR, TE and the newer Segment Routing for OSPF and IS-IS that can be used in a platform that is significantly cheaper than incumbent network vendors.
The cost difference is so large that often ISPs are able to buy switches with a higher overall port speeds than they could from a major vendor. This in turn creates a significant competitive advantage as ISPs can take the same budget (or less) and roll out 100 gig instead of 10 gig – as an example
Unlike enterprise networks, cost is more consistently a significant driver when selecting network equipment for ISPs. This is especially true for startup ISPs that may be limited in the amount of capital that can be spent in a service area to keep ROI numbers relatively sane for investors.
Lab Overview
In the lab (and production) network we have above, OcNOS is deployed as the MPLS core at each data center and MikroTik routers are being used as MPLS PE routers.
VPLS is being run from one DC to the other and delivered via the PE routers to the end hosts.
Because the port density on whitebox switches is so high compared to a traditional aggregation router, we could even use LACP channels if dark fiber was available to increase the transport bandwidth between the DCs without a significant monetary impact on the cost of the deployment.
The type of switches that you’d use in production depend greatly on the speeds and feeds required, but for startup ISPs, we’ve had lots of success with Dell 4048s and Edge-Core 5812.
How hard is it to configure and deploy?
It’s not hard at all!
If you know how to use the up and down arrow keys in the bootloader and TFTP/FTP to load an image onto a piece of network hardware, you’re halfway there!
Here is a screenshot of the GRUB bootloader for an ONIE switch (this is a Dell) where you select which OS to boot the switch into
The configuration is relatively straightforward as well if you’re familiar with industry standard Command Line Interfaces (CLI).
While this lab was configured in a more traditional way using a terminal session to paste commands in, OcNOS can easily be orchestrated and automated using tools like Ansible (also presenting at Networking Field Day 18) or protocols like NETCONF as well as a REST API.
Lab configs
I’ve included the configs from the lab in order to give engineers a better idea of what OcNOS actually looks like for a production deployment.
IPI-MPLS-1
! !Last configuration change at 12:24:27 EDT Tue Jul 17 2018 by ocnos ! no service password-encryption ! hostname IPI-MPLS-1 ! logging monitor 7 ! ip vrf management ! mpls lsp-model uniform mpls propagate-ttl ! ip domain-lookup spanning-tree mode provider-rstp data-center-bridging enable feature telnet feature ssh snmp-server enable snmp snmp-server view all .1 included ntp enable username ocnos role network-admin password encrypted $1$HJDzvHS1$.4/PPuAmCUEwEhs UWeYqo0 ! ip pim register-rp-reachability ! router ldp router-id 100.127.0.1 ! interface lo mtu 65536 ip address 127.0.0.1/8 ip address 100.127.0.1/32 secondary ipv6 address ::1/128 ! interface eth0 ip address 100.64.0.1/29 label-switching enable-ldp ipv4 ! interface eth1 ip address 100.64.0.9/29 label-switching enable-ldp ipv4 ! interface eth2 ip address 100.64.1.1/29 label-switching enable-ldp ipv4 ! interface eth3 ! interface eth4 ! interface eth5 ! interface eth6 ! interface eth7 ! router ospf 1 ospf router-id 100.127.0.1 network 100.64.0.0/29 area 0.0.0.0 network 100.64.0.8/29 area 0.0.0.0 network 100.64.1.0/29 area 0.0.0.0 network 100.127.0.1/32 area 0.0.0.0 cspf disable-better-protection ! bgp extended-asn-cap ! router bgp 8675309 bgp router-id 100.127.0.1 neighbor 100.127.0.3 remote-as 8675309 neighbor 100.127.0.3 update-source lo neighbor 100.127.2.1 remote-as 8675309 neighbor 100.127.2.1 update-source lo neighbor 100.127.2.1 route-reflector-client neighbor 100.127.0.4 remote-as 8675309 neighbor 100.127.0.4 update-source lo neighbor 100.127.0.4 route-reflector-client neighbor 100.127.0.2 remote-as 8675309 neighbor 100.127.0.2 update-source lo neighbor 100.127.0.2 route-reflector-client neighbor 100.127.1.1 remote-as 8675309 neighbor 100.127.1.1 update-source lo neighbor 100.127.1.1 route-reflector-client ! line con 0 login line vty 0 39 login ! end
IPI-MPLS-2
! !Last configuration change at 12:23:31 EDT Tue Jul 17 2018 by ocnos ! no service password-encryption ! hostname IPI-MPLS-2 ! logging monitor 7 ! ip vrf management ! mpls lsp-model uniform mpls propagate-ttl ! ip domain-lookup spanning-tree mode provider-rstp data-center-bridging enable feature telnet feature ssh snmp-server enable snmp snmp-server view all .1 included ntp enable username ocnos role network-admin password encrypted $1$RWk6XAN.$6H0GXBR9ad8eJE2 7nRUfu1 ! ip pim register-rp-reachability ! router ldp router-id 100.127.0.2 ! interface lo mtu 65536 ip address 127.0.0.1/8 ip address 100.127.0.2/32 secondary ipv6 address ::1/128 ! interface eth0 ip address 100.64.0.2/29 label-switching enable-ldp ipv4 ! interface eth1 ip address 100.64.0.17/29 label-switching enable-ldp ipv4 ! interface eth2 ip address 100.64.1.9/29 label-switching enable-ldp ipv4 ! interface eth3 ! interface eth4 ! interface eth5 ! interface eth6 ! interface eth7 ! router ospf 1 network 100.64.0.0/29 area 0.0.0.0 network 100.64.0.16/29 area 0.0.0.0 network 100.64.1.8/29 area 0.0.0.0 network 100.127.0.2/32 area 0.0.0.0 cspf disable-better-protection ! bgp extended-asn-cap ! router bgp 8675309 bgp router-id 100.127.0.2 neighbor 100.127.0.3 remote-as 8675309 neighbor 100.127.0.3 update-source lo neighbor 100.127.0.1 remote-as 8675309 neighbor 100.127.0.1 update-source lo ! line con 0 login line vty 0 39 login ! end
IPI-MPLS-3
! !Last configuration change at 12:25:11 EDT Tue Jul 17 2018 by ocnos ! no service password-encryption ! hostname IPI-MPLS-3 ! logging monitor 7 ! ip vrf management ! mpls lsp-model uniform mpls propagate-ttl ! ip domain-lookup spanning-tree mode provider-rstp data-center-bridging enable feature telnet feature ssh snmp-server enable snmp snmp-server view all .1 included ntp enable username ocnos role network-admin password encrypted $1$gc9xYbW/$JlCDmgAEzcCmz77 QwmJW/1 ! ip pim register-rp-reachability ! router ldp router-id 100.127.0.3 ! interface lo mtu 65536 ip address 127.0.0.1/8 ip address 100.127.0.3/32 secondary ipv6 address ::1/128 ! interface eth0 ip address 100.64.0.25/29 label-switching enable-ldp ipv4 ! interface eth1 ip address 100.64.0.10/29 label-switching enable-ldp ipv4 ! interface eth2 ip address 100.64.2.1/29 label-switching enable-ldp ipv4 ! interface eth3 ! interface eth4 ! interface eth5 ! interface eth6 ! interface eth7 ! router ospf 1 ospf router-id 100.127.0.3 network 100.64.0.8/29 area 0.0.0.0 network 100.64.0.24/29 area 0.0.0.0 network 100.64.2.0/29 area 0.0.0.0 network 100.127.0.3/32 area 0.0.0.0 cspf disable-better-protection ! bgp extended-asn-cap ! router bgp 8675309 bgp router-id 100.127.0.3 neighbor 100.127.0.1 remote-as 8675309 neighbor 100.127.0.1 update-source lo neighbor 100.127.2.1 remote-as 8675309 neighbor 100.127.2.1 update-source lo neighbor 100.127.2.1 route-reflector-client neighbor 100.127.0.4 remote-as 8675309 neighbor 100.127.0.4 update-source lo neighbor 100.127.0.4 route-reflector-client neighbor 100.127.0.2 remote-as 8675309 neighbor 100.127.0.2 update-source lo neighbor 100.127.0.2 route-reflector-client neighbor 100.127.1.1 remote-as 8675309 neighbor 100.127.1.1 update-source lo neighbor 100.127.1.1 route-reflector-client ! line con 0 login line vty 0 39 login ! end
IPI-MPLS-4
! !Last configuration change at 12:24:49 EDT Tue Jul 17 2018 by ocnos ! no service password-encryption ! hostname IPI-MPLS-4 ! logging monitor 7 ! ip vrf management ! mpls lsp-model uniform mpls propagate-ttl ! ip domain-lookup spanning-tree mode provider-rstp data-center-bridging enable feature telnet feature ssh snmp-server enable snmp snmp-server view all .1 included ntp enable username ocnos role network-admin password encrypted $1$6OP7UdH/$RaIxCBOGxHIt1Ao IUyPks/ ! ip pim register-rp-reachability ! router ldp router-id 100.127.0.4 ! interface lo mtu 65536 ip address 127.0.0.1/8 ip address 100.127.0.4/32 secondary ipv6 address ::1/128 ! interface eth0 ip address 100.64.0.26/29 label-switching enable-ldp ipv4 ! interface eth1 ip address 100.64.0.18/29 label-switching enable-ldp ipv4 ! interface eth2 ip address 100.64.2.9/29 label-switching enable-ldp ipv4 ! interface eth3 ! interface eth4 ! interface eth5 ! interface eth6 ! interface eth7 ! router ospf 1 ospf router-id 100.127.0.4 network 100.64.0.16/29 area 0.0.0.0 network 100.64.0.24/29 area 0.0.0.0 network 100.64.2.8/29 area 0.0.0.0 network 100.127.0.4/32 area 0.0.0.0 cspf disable-better-protection ! bgp extended-asn-cap ! router bgp 8675309 bgp router-id 100.127.0.4 neighbor 100.127.0.3 remote-as 8675309 neighbor 100.127.0.3 update-source lo neighbor 100.127.0.1 remote-as 8675309 neighbor 100.127.0.1 update-source lo ! line con 0 login line vty 0 39 login ! end
MikroTik PE-1
# jul/17/2018 17:33:30 by RouterOS 6.38.7
# software id =
#
/interface bridge
add name=Lo0
add name=bridge-vpls-777
/interface vpls
add disabled=no l2mtu=1500 mac-address=02:BF:0A:4A:55:D0 name=vpls777
pw-type=tagged-ethernet remote-peer=100.127.2.1 vpls-id=8675309:777
/interface vlan
add interface=vpls777 name=vlan777 vlan-id=777
/interface wireless security-profiles
set [ find default=yes ] supplicant-identity=MikroTik
/routing bgp instance
set default as=8675309 router-id=100.127.1.1
/routing ospf instance
set [ find default=yes ] router-id=100.127.1.1
/interface bridge port
add bridge=bridge-vpls-777 interface=ether3
add bridge=bridge-vpls-777 interface=vlan777
/ip address
add address=100.64.1.2/29 interface=ether1 network=100.64.1.0
add address=100.127.1.1 interface=Lo0 network=100.127.1.1
add address=100.64.1.10/29 interface=ether2 network=100.64.1.8
/ip dhcp-client
add disabled=no interface=ether4
/mpls ldp
set enabled=yes lsr-id=100.127.1.1 transport-address=100.127.1.1
/mpls ldp interface
add interface=ether1 transport-address=100.127.1.1
add interface=ether2 transport-address=100.127.1.1
/routing bgp peer
add name=IPI-MPLS-1 remote-address=100.127.0.1 remote-as=8675309
update-source=Lo0
add name=IPI-MPLS-3 remote-address=100.127.0.3 remote-as=8675309
update-source=Lo0
/routing ospf network
add area=backbone network=100.64.1.0/29
add area=backbone network=100.64.1.8/29
add area=backbone network=100.127.1.1/32
/system identity
set name=MIkroTik-PE1
/tool romon
set enabled=yes
MikroTik PE-2
# jul/17/2018 17:34:23 by RouterOS 6.38.7 # software id = # /interface bridge add name=Lo0 add name=bridge-vpls-777 /interface vpls add disabled=no l2mtu=1500 mac-address=02:E2:86:F2:23:21 name=vpls777 pw-type=tagged-ethernet remote-peer=100.127.1.1 vpls-id=8675309:777 /interface vlan add interface=vpls777 name=vlan777 vlan-id=777 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /routing bgp instance set default as=8675309 router-id=100.127.2.1 /routing ospf instance set [ find default=yes ] router-id=100.127.2.1 /interface bridge port add bridge=bridge-vpls-777 interface=ether3 add bridge=bridge-vpls-777 interface=vlan777 /ip address add address=100.64.2.2/29 interface=ether1 network=100.64.2.0 add address=100.127.2.1 interface=Lo0 network=100.127.2.1 add address=100.64.2.10/29 interface=ether2 network=100.64.2.8 /ip dhcp-client add disabled=no interface=ether1 /mpls ldp set enabled=yes lsr-id=100.127.2.1 transport-address=100.127.2.1 /mpls ldp interface add interface=ether1 transport-address=100.127.2.1 add interface=ether2 transport-address=100.127.2.1 /routing bgp peer add name=IPI-MPLS-1 remote-address=100.127.0.1 remote-as=8675309 update-source=Lo0 add name=IPI-MPLS-3 remote-address=100.127.0.3 remote-as=8675309 update-source=Lo0 /routing ospf network add area=backbone network=100.64.2.0/29 add area=backbone network=100.64.2.8/29 add area=backbone network=100.127.2.1/32 /system identity set name=MIkroTik-PE2 /tool bandwidth-server set authenticate=no /tool romon set enabled=yes
]]>
If you’re into whitebox, disaggregated or commodity networking, come join the StubArea51.net Facebook group!
All network geeks are welcome 
|
||||||||

{kind=link}
One challenge that every WISP owner or operator has faced is how to leverage unused bandwidth on a backup path to generate more revenue.
For networks that have migrated to MPLS and BGP, this is an easier problem to solve as there are tools that can be used in those protocols like communities or MPLS TE to help manage traffic and set policy.
However, many WISPs rely solely on OSPF and cost adjustment to attempt to influence traffic. Alternatively, trying to use policy routing can lead to a design that doesn’t failover or scale well.
Creating a bottleneck on a single path
WISPs that are OSPF routed will often have a primary path back to the Internet at one or more points in the network typically from a tower that aggregates multiple backhauls.
As more towers are added that rely on this path, it can create a bottleneck while other paths are unused.
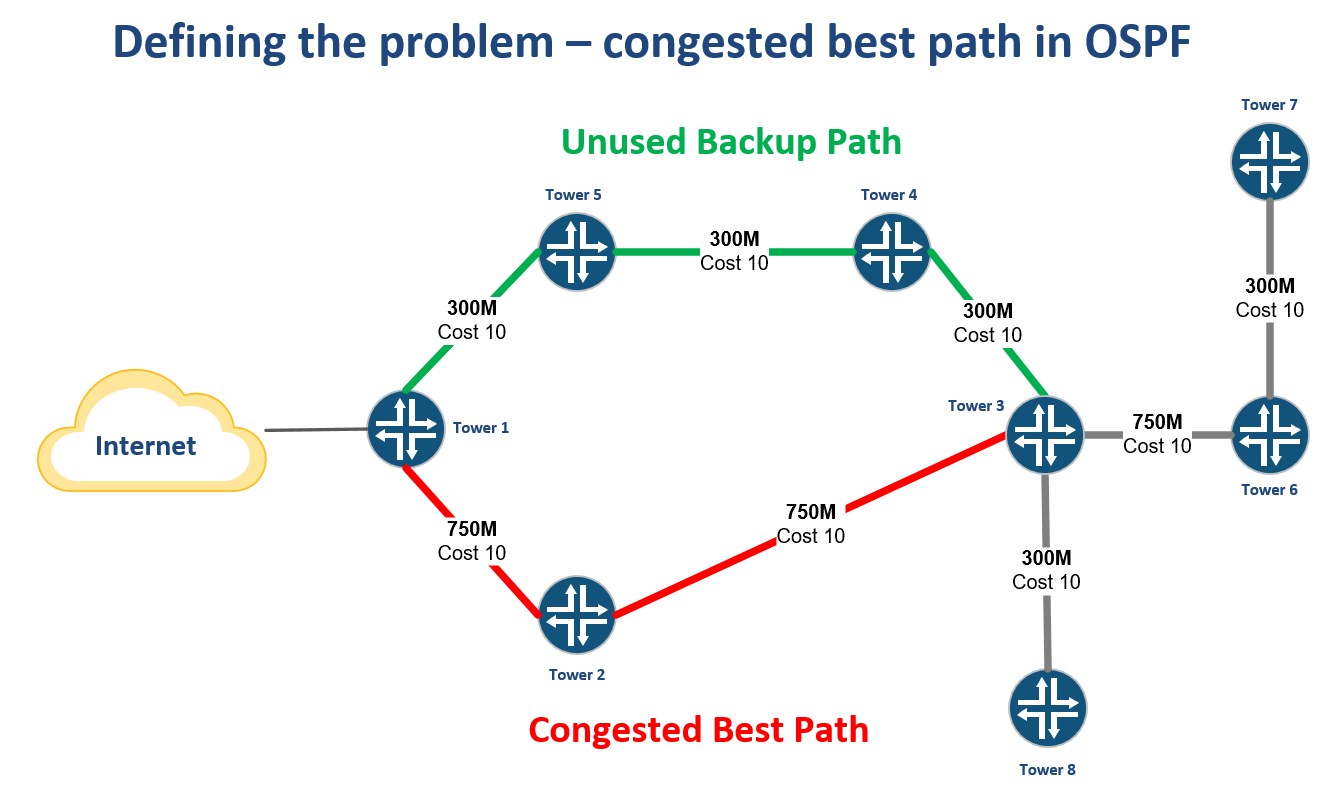
Creating an alternate best path by leapfrogging another router
One way to solve this problem is to use VLANs to create another subnet for OSPF to form an adjacency.
By tagging the VLAN from Tower 6 through Tower 3 and into Tower 4, a new path for OSPF is created that will cause Tower 6 and Tower 7 to take an alternate path.
This allows a WISP operator to tap into unused bandwidth while still retaining a straightforward failover mechanism.
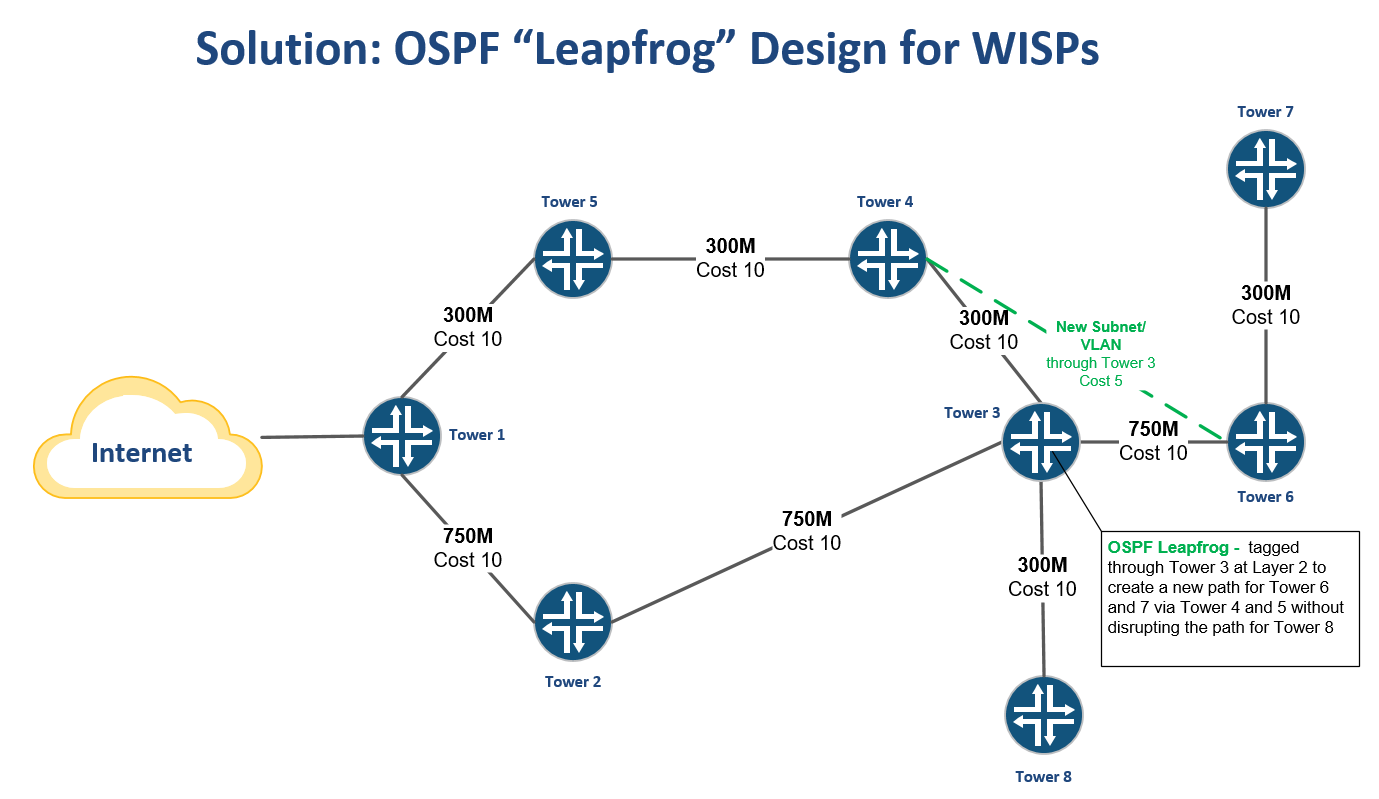
Tower 6 and 7 can now use the alternative path
Now that a lower cost path exists at Layer 3 for Tower 6 and 7, the original best path become less congested and bandwidth that was previously unused can now be used to load balance traffic.
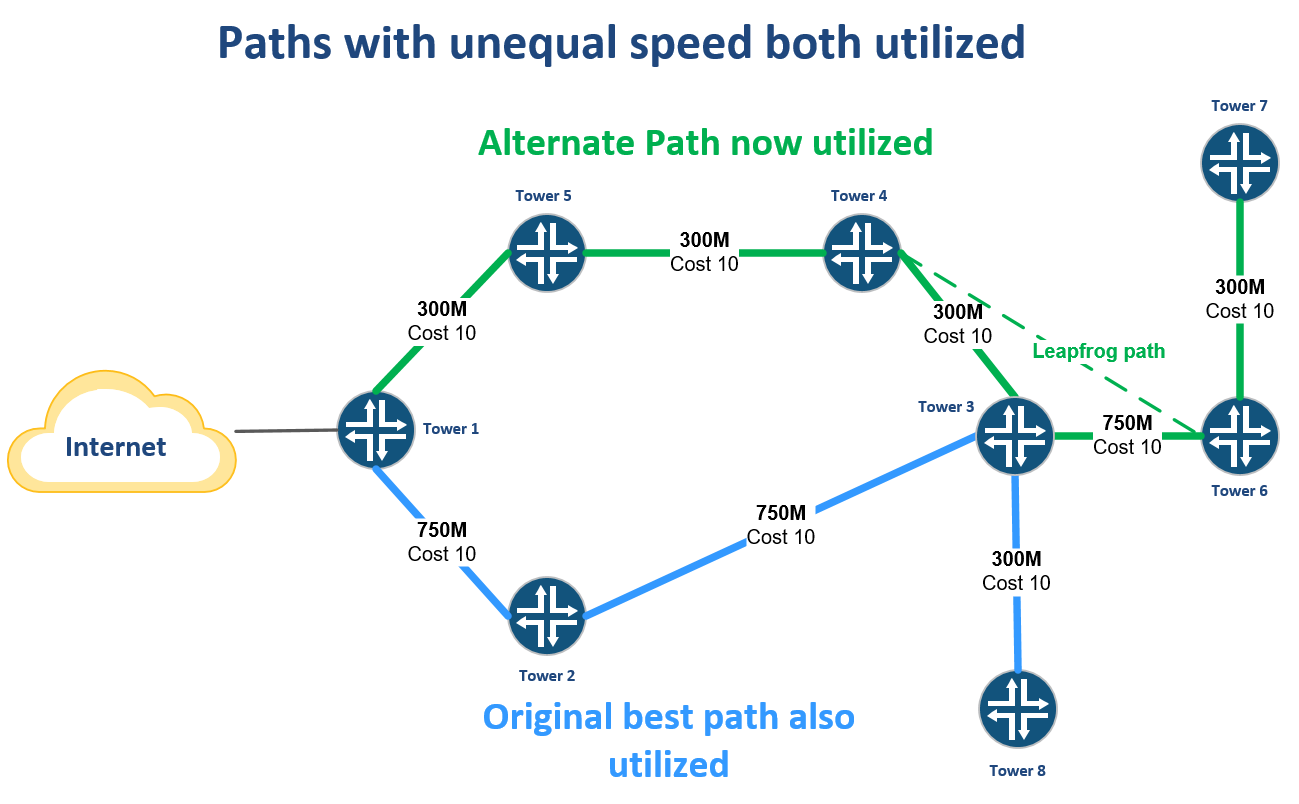
How to build the new path?
I often recommend “switch-centric” architecture also known as “router-on-a-stick” when building a WISP – there are a number of benefits to doing this. In this case, since the switches handle all connections, it’s fairly easy to tag a VLAN from Tower 6 to Tower 4 and create the “leapfrog” path.
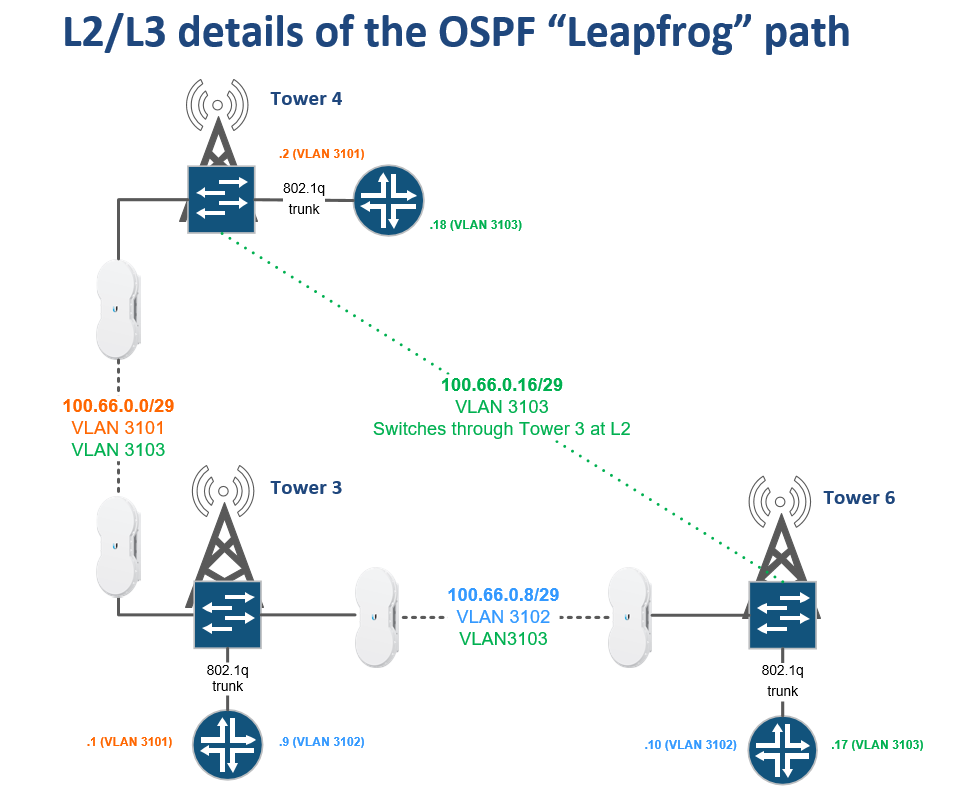
A few closing thoughts
This works well when the towers you need to move onto an alternate path are part of a stub network – that is, they only have one way into the aggregation point before the traffic is split.
If you were trying to do this with rings that connect to other rings and had redundant paths, there could be unintended results so you need to plan the costs and paths carefully.
Labbing the topology to see what will happen is always a good idea.
Hope this is helpful for someone looking to get just a little more bandwidth out of an OSPF based WISP network.
]]>One of the hardest things to do quickly in network engineering, is learn a new syntax for a NOS. Especially if you have a tight deadline and need to stand up equipment you’ve never worked with before. The command structure for RouterOS can be cumbersome if you are used to the Cisco CLI.
If you’ve been in networking for a while, you probably started with learning the Cisco CLI. Therefore, it is helpful to compare the commands if you want to implement a network with a MikroTik and Cisco routers.
This is the third post in a series that creates a Rosetta stone between IOS and RouterOS. We plan to tackle other command comparisons like VLANs, QoS and basic operations to make it easier for network engineers trained in Cisco IOS to successfully implement Mikrotik / RouterOS devices.
Click here for the first article in this series – “Cisco to MikroTik BGP command translation”
Click here for the second article in this series – “Cisco to MikroTik OSPF command translation”
While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
Using EVE-NG for testing
In the last article, we began using EVE-NG instead of GNS3 to emulate both Cisco IOS and RouterOS so we could compare the different commands and ensure the translation was as close as possible. Don’t get me wrong, I like GNS3, but the web interface of EVE-NG makes it really easy to keep all the horsepower for complex labs at a central location and then VPN in to work on labs as needed.
Network for Basic mpls commands
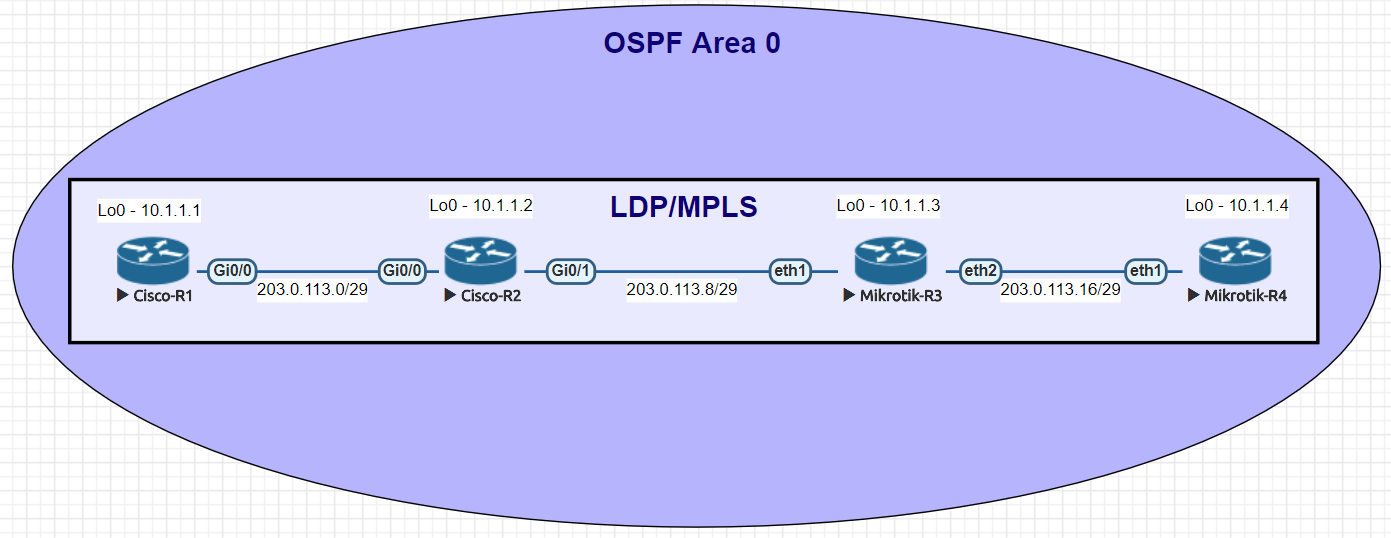
| Cisco command | MikroTik Command |
|---|---|
| show mpls ldp neighbor | mpls ldp neighbor print |
| show mpls interfaces | mpls ldp interface print |
| show mpls forwarding-table | mpls forwarding-table print |
| show mpls binding | mpls remote-bindings print |
| sh mpls ip binding local | mpls local-bindings print |
| sh mpls label range | mpls print |
| sh mpls ldp parameters | mpls ldp print |
| interface GigabitEthernet0/1 mpls ip | /mpls ldp interface add interface=ether1 |
| mpls ldp router-id Loopback0 | /mpls ldp set enabled=yes lsr-id=10.1.1.3 |
Examples of the MikroTik RouterOS commands from the table above
[admin@MikroTik] > mpls ldp neighbor print
This command will show LDP neighbors and detail on whether they are Dynamic, Targeted, Operational or using VPLS

[admin@MikroTik] > mpls ldp interface print
This command will list the interfaces that LDP is enabled on

[admin@MikroTik] > mpls forwarding-table print
Use this command to display the MPLS forwarding table which shows what labels are assigned, the interface used and the next hop.

[admin@MikroTik] > mpls remote-bindings print
This is a quick way to show remote bindings which displays the labels desired and used by the next hop routers for each prefix.

[admin@MikroTik] > mpls local-bindings print
This is a quick way to show local bindings which displays the labels desired and used by the local router – in this case R3.
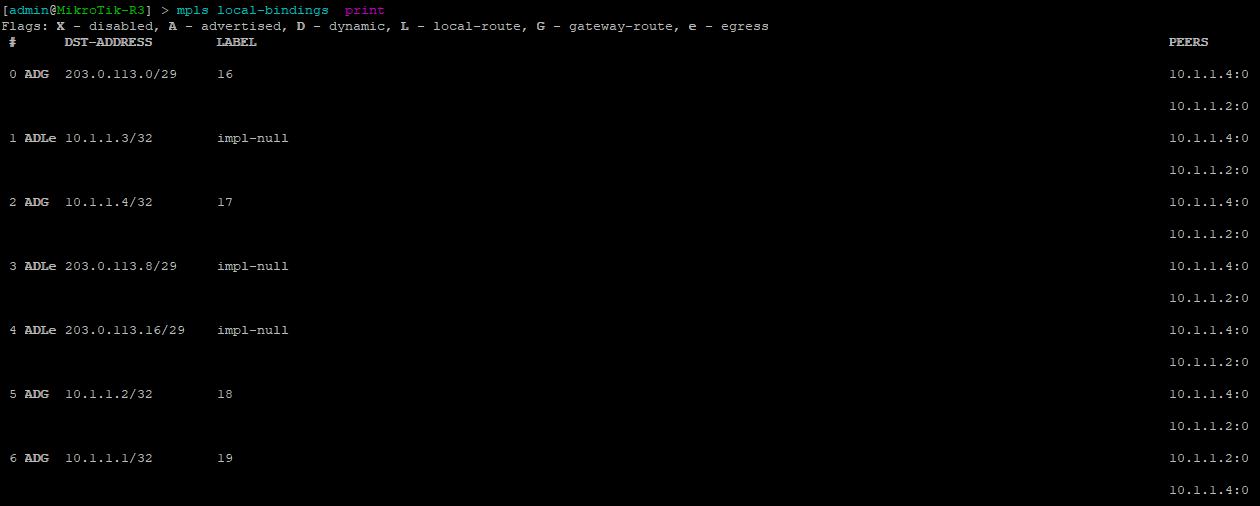
[admin@MikroTik] > mpls print
This is a quick way to show basic mpls settings for RouterOS which includes the label range and whether or not to propagate TTL which affects what a traceroute looks like over an MPLS network.

[admin@MikroTik] > mpls ldp print
This is a quick way to show mpls ldp settings for Router-OS including whether or not LDP is enabled.

Configurations
R1
Cisco-R1#sh run Building configuration... Current configuration : 3062 bytes ! version 15.5 service timestamps debug datetime msec service timestamps log datetime msec no service password-encryption ! hostname Cisco-R1 ! boot-start-marker boot-end-marker ! ! ! no aaa new-model ethernet lmi ce ! ! ! mmi polling-interval 60 no mmi auto-configure no mmi pvc mmi snmp-timeout 180 ! ! ! ! ! ! ! ! ! ! ! ip cef no ipv6 cef ! multilink bundle-name authenticated ! ! ! ! ! redundancy ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! interface Loopback0 ip address 10.1.1.1 255.255.255.255 ! interface GigabitEthernet0/0 ip address 203.0.113.1 255.255.255.248 duplex auto speed auto media-type rj45 mpls ip ! interface GigabitEthernet0/1 no ip address shutdown duplex auto speed auto media-type rj45 ! interface GigabitEthernet0/2 no ip address shutdown duplex auto speed auto media-type rj45 ! interface GigabitEthernet0/3 no ip address shutdown duplex auto speed auto media-type rj45 ! router ospf 1 network 10.1.1.1 0.0.0.0 area 0 network 203.0.113.0 0.0.0.7 area 0 ! ip forward-protocol nd ! ! no ip http server no ip http secure-server ! ! ! mpls ldp router-id Loopback0 ! control-plane ! banner exec ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner incoming ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner login ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C ! line con 0 line aux 0 line vty 0 4 login transport input none ! no scheduler allocate ! end
R2
Cisco-R2#sh run Building configuration... Current configuration : 3122 bytes ! version 15.5 service timestamps debug datetime msec service timestamps log datetime msec no service password-encryption ! hostname Cisco-R2 ! boot-start-marker boot-end-marker ! ! ! no aaa new-model ethernet lmi ce ! ! ! mmi polling-interval 60 no mmi auto-configure no mmi pvc mmi snmp-timeout 180 ! ! ! ! ! ! ! ! ! ! ! ip cef no ipv6 cef ! multilink bundle-name authenticated ! ! ! ! ! redundancy ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! interface Loopback0 ip address 10.1.1.2 255.255.255.255 ! interface GigabitEthernet0/0 ip address 203.0.113.2 255.255.255.248 duplex auto speed auto media-type rj45 mpls ip ! interface GigabitEthernet0/1 ip address 203.0.113.9 255.255.255.248 duplex auto speed auto media-type rj45 mpls ip ! interface GigabitEthernet0/2 no ip address shutdown duplex auto speed auto media-type rj45 ! interface GigabitEthernet0/3 no ip address shutdown duplex auto speed auto media-type rj45 ! router ospf 1 network 10.1.1.2 0.0.0.0 area 0 network 203.0.113.0 0.0.0.7 area 0 network 203.0.113.8 0.0.0.7 area 0 ! ip forward-protocol nd ! ! no ip http server no ip http secure-server ! ! ! mpls ldp router-id Loopback0 ! control-plane ! banner exec ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner incoming ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C banner login ^C ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * **************************************************************************^C ! line con 0 line aux 0 line vty 0 4 login transport input none ! no scheduler allocate ! end
R3
[admin@MikroTik-R3] > export # may/03/2018 16:34:51 by RouterOS 6.38.7 # software id = # /interface bridge add name=Loopback0 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /ip address add address=203.0.113.10/29 interface=ether1 network=203.0.113.8 add address=10.1.1.3 interface=Loopback0 network=10.1.1.3 add address=203.0.113.17/29 interface=ether2 network=203.0.113.16 /ip dhcp-client add disabled=no interface=ether1 /mpls ldp set enabled=yes lsr-id=10.1.1.3 /mpls ldp interface add interface=ether1 add interface=ether2 /routing ospf network add area=backbone network=203.0.113.8/29 add area=backbone network=10.1.1.3/32 add area=backbone network=203.0.113.16/29 /system identity set name=MikroTik-R3
R4
[admin@MikroTik-R4] > export # may/03/2018 16:35:28 by RouterOS 6.38.7 # software id = # /interface bridge add name=Loopback0 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /ip address add address=203.0.113.18/29 interface=ether1 network=203.0.113.16 add address=10.1.1.4 interface=Loopback0 network=10.1.1.4 /ip dhcp-client add disabled=no interface=ether1 /mpls ldp set enabled=yes lsr-id=10.1.1.4 /mpls ldp interface add interface=ether1 /routing ospf network add area=backbone network=203.0.113.16/29 add area=backbone network=10.1.1.4/32 /system identity set name=MikroTik-R4
Virtual Private LAN Service or VPLS is a Layer 2 overlay or tunnel that allows for the encapsulation of ethernet frames (with or without VLAN tags) over an MPLS network.
https://tools.ietf.org/html/rfc4762
VPLS is often found in Telco networks that rely on PPPoE to create centralized BRAS deployments by bringing all of the end users to a common point via L2.
MikroTik VPLS example (https://wiki.mikrotik.com/wiki/Transparently_Bridge_two_Networks_using_MPLS)
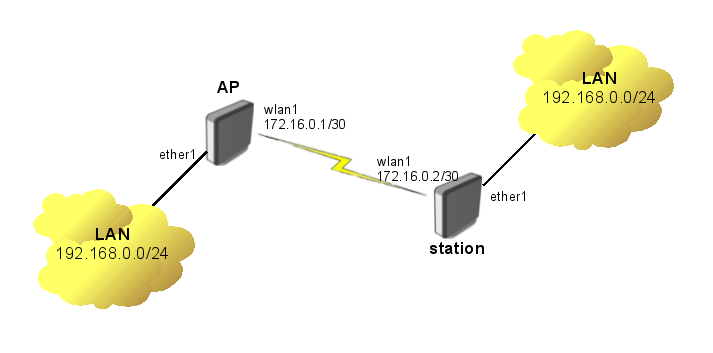
Background
The idea for this post came out of a working session (at the bar of course) at WISPAmerica 2018 in Birmingham, Alabama.
There was a discussion about how to create redundancy for VPLS tunnels on multiple routers. I started working on this in EVE-NG as we were talking about it.
The goal is creating highly available endpoints for VPLS when using them to deploy a public subnet that can be delivered to any tower in the WISP. The same idea works for wireline networks as well.
Use Case
As IPv4 becomes harder to get, ISPs like WISPs, without large blocks of public space find it difficult to deploy them in smaller subnets. The idea behind breaking up a /23 or /24 for example, is that every tower has public IP addresses available.
However, the problem with this approach is that some subnets may not be used if there isn’t much demand for a dedicated public IP by customers.
What makes VPLS attractive in this scenario is that the public subnet (a /24 in this example) can be placed at the data center as an intact prefix.
VPLS tunnels then allow for individual IP addresses to exist at any tower in the network which provides flexibility and conserves IPv4 space by not subnetting the block into /29 /28 /27 at the tower level.
Lab Network
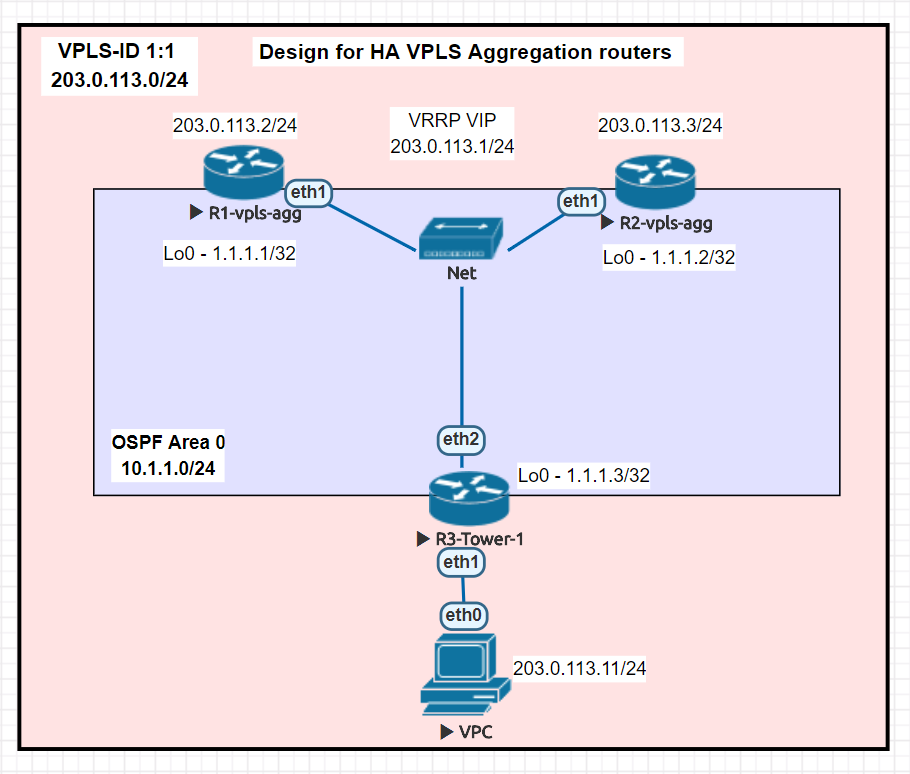
Deployment
In this lab, the VPLS tunnels terminate in two different data centers as well as at a tower router to create an L2 segment for 203.0.113.0/24. VRRP is then run between the two data center VPLS routers so that the gateway of 203.0.113.1 can failover to the other DC if needed.
Failover
Here is an example of the convergence time when we manually fail R1 and the gateway flips over to R2 in the other DC. The yellow highlight marks the point where R1 has failed and R2 VRRP has become master.
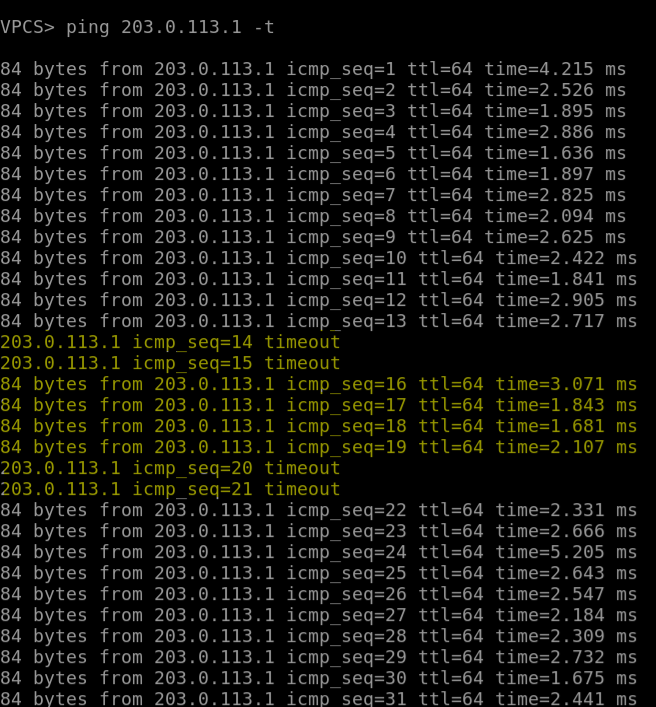
Configurations
R1-vpls-agg
/interface bridge add name=Lo0 add name=vpls1-1 /interface vrrp add interface=vpls1-1 name=vpls1-1-vrrp priority=200 /interface vpls add disabled=no l2mtu=1500 mac-address=02:2C:0B:61:64:CB name=vpls1 remote-peer=1.1.1.2 vpls-id=1:1 add disabled=no l2mtu=1500 mac-address=02:7C:8C:C9:CE:8E name=vpls2 remote-peer=1.1.1.3 vpls-id=1:1 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /interface bridge port add bridge=vpls1-1 interface=vpls1 add bridge=vpls1-1 interface=vpls2 /ip address add address=1.1.1.1 interface=Lo0 network=1.1.1.1 add address=10.1.1.1/24 interface=ether1 network=10.1.1.0 add address=203.0.113.2/24 interface=vpls1-1 network=203.0.113.0 add address=203.0.113.1/24 interface=vpls1-1-vrrp network=203.0.113.0 /ip dhcp-client add disabled=no interface=ether1 /mpls ldp set enabled=yes lsr-id=1.1.1.1 transport-address=1.1.1.1 /mpls ldp interface add interface=ether1 /routing ospf network add area=backbone network=10.1.1.0/24 add area=backbone network=1.1.1.1/32 /system identity set name=R1-vpls-agg
R2-vpls-agg
/interface bridge add name=Lo0 add name=vpls1-1 /interface vrrp add interface=vpls1-1 name=vpls1-1-vrrp /interface vpls add disabled=no l2mtu=1500 mac-address=02:C3:4C:31:FB:C9 name=vpls1 remote-peer=1.1.1.1 vpls-id=1:1 add disabled=no l2mtu=1500 mac-address=02:02:34:C0:A3:3C name=vpls2 remote-peer=1.1.1.3 vpls-id=1:1 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /interface bridge port add bridge=vpls1-1 interface=vpls1 add bridge=vpls1-1 interface=vpls2 /ip address add address=10.1.1.2/24 interface=ether1 network=10.1.1.0 add address=1.1.1.2 interface=Lo0 network=1.1.1.2 add address=203.0.113.3/24 interface=vpls1-1 network=203.0.113.0 add address=203.0.113.1/24 interface=vpls1-1-vrrp network=203.0.113.0 /ip dhcp-client add disabled=no interface=ether1 /mpls ldp set enabled=yes lsr-id=1.1.1.2 transport-address=1.1.1.2 /mpls ldp interface add interface=ether1 /routing ospf network add area=backbone network=10.1.1.0/24 add area=backbone network=1.1.1.2/32 /system identity set name=R2-vpls-agg
R3-Tower-1
/interface bridge add name=Lo0 add name=vpls-1-1 /interface vpls add disabled=no l2mtu=1500 mac-address=02:CB:47:7A:92:0B name=vpls1 remote-peer=1.1.1.1 vpls-id=1:1 add disabled=no l2mtu=1500 mac-address=02:E3:C5:5B:EC:BF name=vpls2 remote-peer=1.1.1.2 vpls-id=1:1 /interface wireless security-profiles set [ find default=yes ] supplicant-identity=MikroTik /interface bridge port add bridge=vpls-1-1 interface=ether1 add bridge=vpls-1-1 interface=vpls1 add bridge=vpls-1-1 interface=vpls2 /ip address add address=10.1.1.3/24 interface=ether2 network=10.1.1.0 add address=1.1.1.3 interface=Lo0 network=1.1.1.3 /ip dhcp-client add disabled=no interface=ether1 /mpls ldp set enabled=yes lsr-id=1.1.1.3 transport-address=1.1.1.3 /mpls ldp interface add interface=ether2 /routing ospf network add area=backbone network=10.1.1.0/24 add area=backbone network=1.1.1.3/32 /system identity set name=R3-tower-vpls]]>
If you’ve been in networking for a while, there’s a good chance you started with Cisco gear and so it is helpful to draw comparisons between the commands, especially if you are trying to build a network with a MikroTik and Cisco router.
This is the second post in a series that creates a Rosetta stone essentially between IOS and RouterOS. We plan to tackle other command comparisons like MPLS, VLANs and basic operations to make it easier for network engineers trained in Cisco IOS to successfully implement Mikrotik / RouterOS devices.
Click here for the first article in this series – “Cisco to MikroTik BGP command translation”
While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
Using EVE-NG for testing
In the last article, we used GNS3 to emulate both Cisco IOS and RouterOS so we could compare the different commands and ensure the translation was as close as possible. For this article, we decided to use EVE-NG as it’s becoming more and more popular for network emulation.
Network for Basic commands
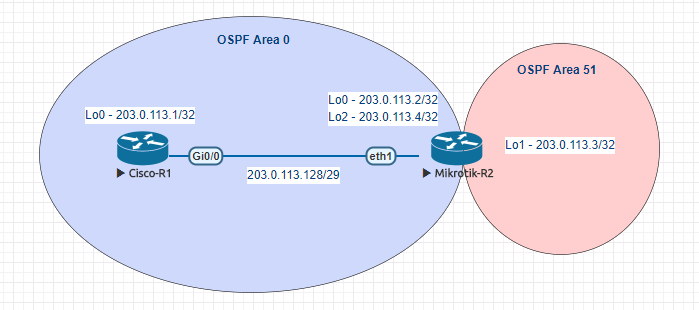
| Cisco command | MikroTik Command |
|---|---|
| show ip ospf neighbor | routing ospf neighbor print |
| show ip ospf interface | routing ospf interface print |
| show ip ospf 1 | routing ospf instance print detail |
| show ip ospf database | routing ospf lsa print |
| show ip route ospf | ip route print where ospf=yes |
| show ip ospf rib | routing ospf route print |
| show ip ospf border-routers | routing ospf area-border-router print |
| show ip ospf border-routers | routing ospf as-border-router print |
| Cisco(config)#router ospf 1 | /routing ospf instance |
| Cisco(config-router)#router-id 203.0.113.1 | /routing ospf instance set 0 router-id=203.0.113.2 |
| Cisco(config-router)#network 203.0.113.1 0.0.0.0 area 0 | /routing ospf network add area=backbone network=203.0.113.2/32 |
| Cisco(config-router)#network 203.0.113.128 0.0.0.7 area 0 | /routing ospf network add area=backbone network=203.0.113.128/29 |
| Cisco(config-router)#interface GigabitEthernet0/0 Cisco(config-if)# ip ospf network point-to-point Cisco(config-if)# ip ospf dead-interval 4 Cisco(config-if)# ip ospf hello-interval 1 | /routing ospf interface add dead-interval=4s hello-interval=1s interface=ether1 network-type=point-to-point |
Examples of the MikroTik RouterOS commands from the table above
[admin@MikroTik] > routing ospf neighbor print
This is a quick way to show all the OSPF neighbors the router is adjacent to.

[admin@MikroTik] > routing ospf interface print
This command lists all of the interfaces configured for OSPF, costs, authentication and whether or not the interface is passive. Unlike Cisco, MikroTik’s default behavior is to dynamically create an OPSF interface when a network statement is added which is what the ‘D’ flag stands for.

[admin@MikroTik] > routing ospf instance print detail
This command lists the details for all OSPF instances on the router including: router-id, redistribution settings, default metrics and filters applied in and out.
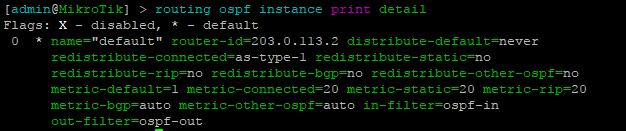
[admin@MikroTik] > routing ospf lsa print
This command lists all OPSF LSAs along with sequence number, originator and age.

[admin@MikroTik] > ip route print where ospf=yes
This command allows you to list all of the OSPF routes in the routing table. Unlike Cisco, RouterOS will list routes that aren’t active in the routing table instead of just in the RIB like Cisco.

[admin@MikroTik] > routing ospf route print
This is a quick way to show the routes that OSPF is aware of on the router, the state of the route, cost and the gateway/interface.

[admin@MikroTik] > routing ospf area-border-router print
Using this command will print all of the ABRs and areas the router is aware of.

[admin@MikroTik] > routing ospf as-border-router print
This command will list all ASBRs for the router.

[admin@MikroTik] > routing ospf export
Here is an example of a basic MikroTik OSPF config with a few options turned on like a standard area defined as well as redistribution of connected routes.
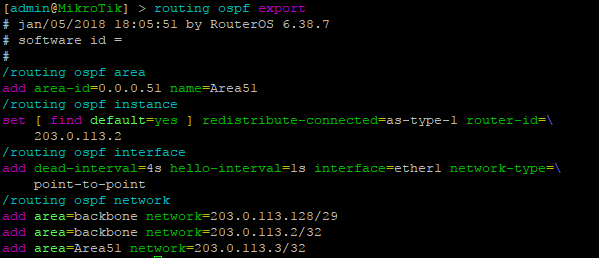
More Cisco to MikroTik articles are on the way!
This article covers most of the common OSPF commands. Some of the more advanced config and commands including OSPF flitering, Virtual and Sham Links will be tackled in a separate article. MPLS and VLANs are also on the list. Stay tuned for more!
]]>
Back to Silicon Valley!
As a network type, it’s hard not to be excited when heading to a Networking Field Day event. I joined then NFD club by attending NFD14 and have been hooked ever since.
Not only is it an honor and a privilege to be invited to an NFD event, the personal relationships that are forged in the larger TFD community are some of the most valuable I’ve ever had in my career.
This go around we’ll be visiting Aruba (A Hewlett Packard Enterprise Company) in Santa Clara to deep dive on the newest addition to the Aruba product line – the 8400 core switch.
A new face in campus town – the Aruba 8400
It’s been a while since anything exciting happened in the world of campus networking. It’s a steady segment for most vendors but nothing disruptive has really happened in the last few years.
And that’s not incredibly surprising. For better or worse, as long as campus networks aren’t broken in most enterprises, they are often neglected in favor of the data center and cloudy pursuits.
Aruba is touting the 8400 to increase automation and visibility in the campus core – both are areas that network engineering teams have traditionally struggled to implement.
Couple that with a brand new API enabled NOS that has built-in analytics and Aruba may have a serious claim on the ‘game changing’ campaign it has been running since announcing the 8400 in June 2017.
The 8400 quick specs:
- 8 slot chassis (for linecards)
- Provides up to 19.2 Tbps switching capacity (8.571 billion packets per second)
- Supports a maximum of 256 10GbE (SFP/SFP+) ports, or 64 40GbE (QSFP+) ports, or 48 ports 40/100GbE (QSFP28) combination
- Full 8400 data sheet is here
First impressions:
What I like
Speeds/Port Density – The speed/port density specs for the 8400 read more like a data center switch than a campus core which means even the largest campus networks will have plenty of available ports with up to 100 gig if needed.
Security – Encryption at wire speed is becoming more and more of an issue as new security and compliance requirements force network teams to treat private links that were previously trusted as untrusted. The availability of MACSEC on linecards is big plus.
Automation – In reading the product literature, one of the differentiating factors listed is the ability to automate manual tasks like the provisioning of network switches to support wireless access points. This is a task that can be fairly daunting in a network with a large number of switches and no automation. I’ll be interested to see how the ‘zero touch’ provisioning for APs that Aruba describes actually works.
Visibility/Troubleshooting – Enhanced visibility and troubleshooting tools are a welcome feature for any engineering team. Aruba has developed a Network Analytics Engine that is listed as being at the heart of this set of capabilities. Onboard network analysis modules have been tried before by other vendors with varying degrees of success and so it will be interesting to see what Aruba’s take is on built in analytics.
Virtual Switching Framework – As a designer of networks, i’m a big fan of leveraging link aggregation in my designs for path redundancy coupled with switches than can support multi-chassis LACP. The 8400 supports Aruba’s Virtual Switching Framework which allows both chassis to work together in similar fashion to a switch stack which allows for a single LACP channel to contain links in two different chassis. While this isn’t a groundbreaking feature, it’s critical to competing in the campus core market.
Complete REST API – Aruba describes the REST based API in this blog post as having access to “every network function and state, both persistent and ephemeral, within the switch.” This opens up a world of possibilities for integration and automation into enterprise applications as well as automation/orchestration engines.
Initial questions I have for Aruba:
Code maturity – The Aruba OS-CX network operating system seems to be the heart and soul of the new switch. As with any new NOS, one of my first questions is around interop and bug testing. What interop testing has been done and what are the results from current field deployments?
Software licensing and support – Software/feature licensing and support can be a source of frustration fro enterprise clients. Understanding the software and support model that Aruba uses will be one of the initial questions that I have.
Depth of the L3 feature set – As much as we try to avoid complexity in the core, sometimes advanced features in OSPF and BGP are needed such as dynamic routing within a VRF or a complex set of REGEX values to build a route map for a BGP peer. One of my goals in attending this NFD is to better understand the capabilities of Aruba’s routing stack in OS-CX.
To disaggregate or not
Often the opinions we have on new technology are shaped by our daily work. As someone who is frequently engaged in whitebox integration, disaggregation has become more and more prevalant in my daily work.
I suspect the decision by Aruba to use a chassis to offer port density rather than a disaggregated leaf/spine architecture stems from the lack of demand by enterprises to use leaf/spine in the campus.
Chassis is what everyone is comfortable with and expects to implement when designing the campus core. As such, nobody in the world of disaggregated networking has taken aim at the campus from a software standpoint.
That said, it will be interesting to see if a small leaf/spine core is considered for future hardware iterations of the OS-CX family aimed at campus deployments.
More to come!
As I write this, I’m enroute to #NFDx and am looking forward to the presentation by Aruba so that we can deep dive and really understand what makes the 8400 tick and the problems Aruba is trying to solve.
Please tag me @stubarea51 on twitter with the #NFDx hashtag if you have questions you’d like to ask Aruba about the 8400.
Stay tuned!
]]>
The role of whitebox in a WISP/FISP MPLS core
Whitebox, if you aren’t familiar with it, is the idea of separating the network operating system and switching hardware into commodity elements that can be purchased separately. There was a good overview on whitebox in this StubArea51.net article a while back if you’re looking for some background.
Lately, I’ve had a number of clients interested in deploying IP Infusion with either Dell, Agema or Edge Core switches to build an MPLS core architecture in lieu of an L2 ring deployment via ERPs. Add to that a production deployment of Cumulus Linux and Edge Core that I’ve been working on building out and it’s been a great year for whitebox.
There are a number of articles written that extoll the virtues of whitebox for web scale companies, large service providers and big enterprises. However, not much has been written on how whitebox can help smaller Tier 2 and 3 ISPs – especially Wireless ISPs (WISPs) and Fiber ISPs (FISPs).
And the line between those types of ISPs gets more blurry by the day as WISPs are heavily getting into fiber and FISPs are getting into last mile RF. Some of the most successful ISPs I consult for tend to be a bit of a hybrid between WISP and FISP.
The goal of any ISP stakeholder whether large or small should be getting the lowest cost per port for any network platform (while maintaining the same level of service – or even better) so that service offerings can be improved or expanded without being required to pass the financial burden down to the end subscriber.
Whitebox is well positioned to aid ISPs in attaining that goal.
Whitebox vs. Traditional Vendor
Whitebox is rapidly gaining traction and working towards becoming the new status quo in networking. The days of proprietary hardware as the dominant force are numbered. Correspondingly, the extremely high R&D/manufacturing cost that is passed along to customers also seems to be in jeopardy for mainstream vendors like Cisco and Juniper.
Here are a few of the advantages that whitebox has for Tier2 and 3 ISPs:
- Cost – it is not uncommon to find 48 ports of 10 gig and 4 ports of 40 gig on a new whitebox switch with licensing for under $10k. Comparable deployments in Cisco, Juniper, Brocade, etc typically exceed that number by a factor of 3 or more.
- SDN and NFV – Open standards and development are at the heart of the SDN and NFV movement, so it’s no surprise that whitebox vendors are knee deep in SDN and NFV solutions. Because whitebox operating systems are modular, less cluttered and have built in hardware abstraction, SDN and NFV actually become much easier to implement.
- No graymarket penalty – Because the operating system and hardware are separate, there isn’t an issue with obtaining hardware from the graymarket and then going to get a license with support. While the cost of the hardware brand new is still incredibly affordable, some ISPs leverage the graymarket to expand when faced with limited financial resources.
- Stability – whitebox operating systems tend to implement open standards protocols and stick to mainstream use cases. The lack of proprietary corner case features allows the development teams for a whitebox NOS to be more thorough about testing for stability, interop and fixing bugs.
- Focus on software – One of the benefits that comes from separating hardware and software for network equipment is a singular focus on software development instead of having to jump though hoops to support hundreds of platforms that sometimes have a very short product lifecycle. This is probably the single greatest challenge traditional vendors face in producing high quality software.
- ISSU – Often touted as a competitive advantage by the likes of Cisco and others, In Service Software Upgrade (ISSU ) is now supported by some whitebox NOS vendors.

IP Infusion
IP Infusion (IPI) first got on my radar about 2 years ago when I was working through a POC for Cumulus Linux and just getting my feet wet in understanding the world of whitebox. What struck me as unique about them is that IP Infusion has been writing code for protocol stacks and modular network operating systems (ZebOS) for the last 20 years – essentially making them a seasoned veteran in turning out stable code for a NOS. As the commodity hardware movement started gathering steam, IP Infusion took all of the knowledge and experience from ZebOS and created OcNOS, which is a platform that is compatible with ONIE switches.
Earlier this year, I attended Networking Field Day 14 (NFD14) as a delegate and was pleasantly surprised to learn that IP Infusion presented at Networking Field Day 15 (NFD15) back in April. I highly recommend watching all of the NFD15 videos on IP Infusion, as you’d be hard pressed to find a better technical deep dive on IPI anywhere else. Some of the technical and background content here is taken from the video sessions at NFD15.
Background
- Has its roots in GNU Zebra routing engine
- Strong adherence to standards-based protocol implementations
- Original white label NOS ZebOS has been around for 20+ years and is used by companies like F5, Fortinet and Citrix
Advantages
- Very service provider focused with advanced feature sets for BGP/MPLS
- OcNOS benefits from 20 years of white label NOS development and according to IP Infusion’s marketing material is reputed to have “six 9’s” of stability as observed by their larger ISP customers.
- Perpetual licensing – once the license is purchased, the only recurring cost is the annual maintenance which is a much smaller fee (typically around 15% of the license)
- Extensive API support – IPI has extensive API support for protocols like BGP to facilitate integration of automation and orchestration.
- Easier hardware abstractions than proprietary NOS – look for chassis based whitebox and form factors beyond 1U in the future
- Increased focus on the 1 Gbps switch market with Broadcom’s incredibly feature rich Qumran chipset so that Start-up and very small ISPs can still leverage the benefits of whitebox. Also, larger Tier 2 and 3 ISPs will have a switching solution for edge, aggregation and customer CPE needs.
Integrating OcNOS with MikroTik/Ubiquiti
I’ve specifically listed IP Infusion instead of doing a more in depth comparison of all the various whitebox operating systems, because IP Infusion is really positioned to be the best choice for Tier 2 and 3 ISPs due to the available feature set and modular approach to building protocol support. Going a step further, it’s a natural fit for ISPs that are running MikroTik or Ubiquiti as the OcNOS operating system fills in many of the gaps in protocol support (MPLS TE and FRR especially) that are needed when building an MPLS core for a rapidly expanding ISP.
While I’ve successfully built MPLS into many ISPs with MikroTik and Ubiquiti and continue to do so, there is a scaling limit that most ISPs eventually hit and need to start using ASIC based hardware with the ability to design comprehensive traffic engineering policies.
The good news is that MikroTik and Ubiquiti still have a role to play when building a whitebox core. Both work very well as MPLS PE routers that can be attached to the IP Infusion MPLS core. Last mile services can then be delivered in a very cost effective way leveraging technologies like VPLS or L3VPN.
Other Whitebox NOS offerings
There are a number of other whitebox network operating systems to choose from. Although the focus has been on IPI due to the feature set, Cumulus Linux and Big Switch are both great options if you have a need to deploy data center services.
Cumulus Linux is also rapidly working on developing and putting MPLS and more advanced routing protocol support into the operating system and it wouldn’t surprise me if they become more of a contender in the ISP arena in the next few years.
This actually touches on one of the other great benefits of whitebox. You can stock a common switch and put the operating system on that best fits the use case.
For example, the Dell S4048-ON switch (48x10gig,4x40gig) can be used for IPI, Cumulus Linux and Big Switch depending on the feature set required.
Some ISPs are getting into or already run cloud and colocation services in their data centers. If a compatible whitebox switch is used then stocking replacement hardware and operational maintenance of the ISP and Data Center portions of the network become far simpler.
Design elements of a WISP/FISP based on a whitebox MPLS core
Here are some examples of the most common elements we are trending towards as we start building WISPs and FISPs on a whitebox foundation coupled with other common low cost vendors like MikroTik and Ubiquiti.
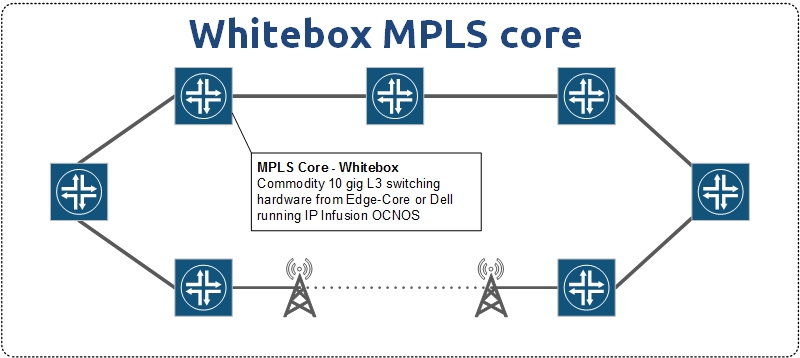
Whitebox MPLS Core
As ISPs grow, the core tends to move from pure routers to Layer 3 switches to be able to better support higher speeds and take advantage of technologies like dark fiber and DWDM/CWDM to increase speeds. Many smaller ISPs are starting to compete using the “Google Fiber” model of selling 1Gbps synchronous to residential customers and need the extra capacity to handle that traffic.
MPLS support on ASICs has traditionally been extremely expensive with costs soaring as the port speeds increase from 1 gig to 10 gig and 40 gig. And yet MPLS is a fundamental requirement for the multi-tenancy needs of an ISP.
Leveraging whitebox hardware allows for MPLS switching in hardware at 10, 40 and 100 gig speeds for a fraction of the cost of vendors like Cisco and Juniper.
This allows ISPs to utilize dark fiber, wave and 10Gig+ layer 2 services in more cost effective way to increase the overall capacity of the core.
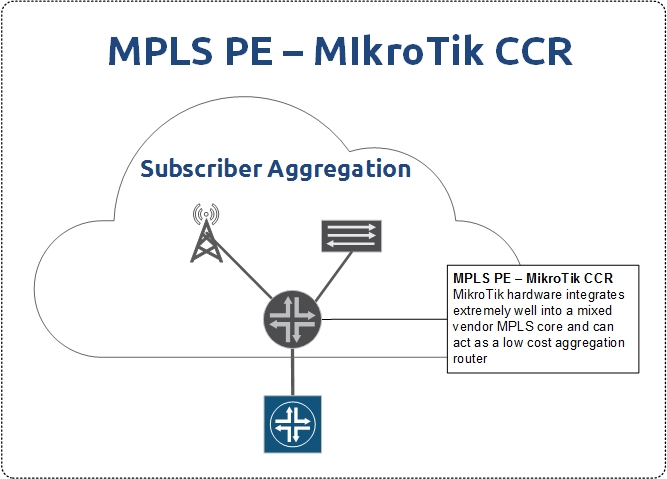
MPLS PE for Aggregation
MikroTik and Ubiquiti both have hardware with economical MPLS feature sets that work well as an MPLS PE. Having said that, I give MikroTik the edge here as Ubiquiti has only recently implemented MPLS and is still working on expanding the feature set.
MikroTik in contrast has had MPLS in play for a long time and is a very solid choice when aggregation and PE services are needed. The CCR series in particular has been very popular and stable as a PE router.
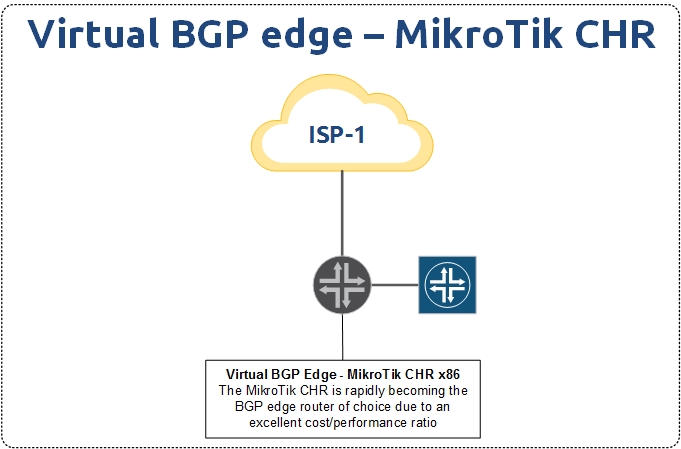
Virtual BGP Edge
MikroTik has made great strides in the high performance virtual market with the introduction of the Cloud Hosted Router (CHR) a little over a year ago.
Due to the current limitation of the MikroTik kernel to only using one processor for BGP, there has been a trend towards using x86 hardware with much higher clock speed per core than the CCR series to handle the requirement of a full BGP table.
The CHR is able to process changes in the BGP table much faster as a result and doesn’t suffer from the slow convergence speeds that can happen on CCRs with a large number of full tables.
Couple that with license costs that max out at $200 USD for unlimited speeds and the CHR becomes incredibly attractive as the choice for an edge BGP router.
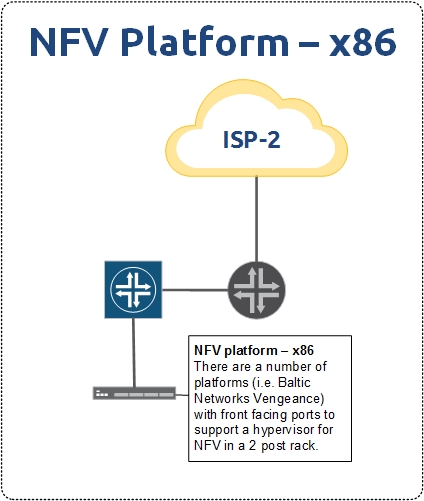
NFV platform
Network Function Virtualization (NFV) has been getting a lot of press lately as more and more ISPs are turning to hypervisors to spin up resources that would traditionally be handled in purpose built hardware. NFV allows for more generic hardware deployments of hypervisors and switches so that more specific network functions can be handed virtually.
Some examples are:
- BGP Edge routers (smiliar to the previous BGP CHR use case)
- BRAS for PPPoE
- QoE engines
- EPC for LTE deployments
- Security devices like IPS/IDS and WAF
- MPLS PE routers
There are many ways to leverage x86 horsepower to get NFV into a WISP or FISP. One platform in particular that is gaining attention is Baltic Networks’ Vengeance router which runs VMWARE ESXi and can be used in a number of different NFV deployments.
We have been testing a Vengeance router in the StubArea51.net lab for several months and have seen very positive results. We will be doing a more in depth hardware review on that platform as a separate article in the future.
Closing thoughts
Whitebox is poised for rapid growth in the network world, as the climate is finally becoming favorable – even in larger companies – to use commodity hardware and not be entirely dependent on incumbent network vendors. This is already opening up a number of options for economical growth of ISPs in a platform that appears to be surpassing the larger vendors in reliability due to a more concentrated focus on software.
Commodity networking is here to stay and I look forward to the vast array of problems that it can solve as we build out the next generation of WISP and FISP networks.
]]>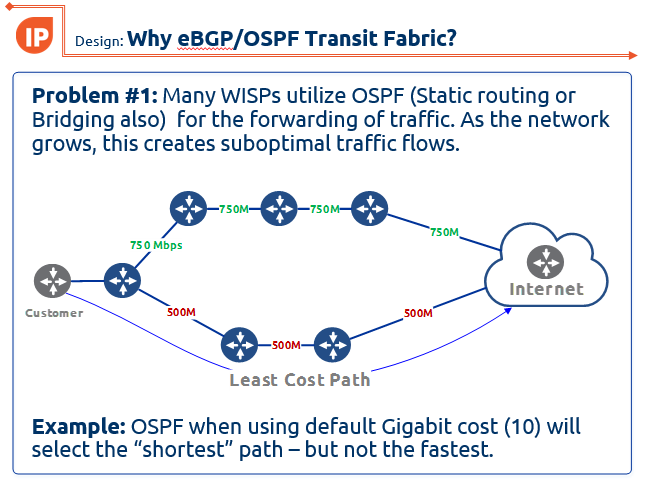
One of the latest designs I have been working on is using eBGP and an OSPF transit fabric to provide traffic engineering and load balancing. If you missed this presentation at the 2017 MikroTik User Meeting in Denver, CO, here are the slides:
WISP-Design-Using-eBGP-and-OSPF-TF-traffic-engineering-MUM-2017_KevinMyers-4-by-3
]]>
What is whitebox networking and why is it important?
A brief history of the origins of whitebox
One of the many interesting conversations to come out of my recent trip to Network Field Day 14 (NFD14) hosted by Gestalt IT was a discussion on the future of whitebox. As someone who co-founded a firm that consults on whitebox and open networking, it was a topic that really captivated me and generated a flurry of ideas on the subject. This will be the first in a series of posts about my experiences and thoughts on NFD14.
Whitebox is a critical movement in the network industry that is reshaping the landscape of what equipment and software we use to build networks. At the dawn of the age of IT in the late 80s and early 90’s, we used computing hardware and software that was proprietary – a great example would be an IBM mainframe.
Then we evolved into the world of x86 and along came a number of operating systems that we could choose from to customize the delivery of applications and services. Hardware became a commodity and software became independent of the hardware manufacturer.
ONIE – The beginning of independent network OS
The importance of whitebox in 2017 and beyond
Whitebox is critically important to the future of networking because it is forcing all incumbent network hardware/software vendors to compete in an entirely different way. The idea that a tightly integrated network operating system on proprietary hardware is essential to maintaining uptime and availability is rapidly fading.
Tech giants like Google, Facebook and Linkedin have proven that commodity and open network hardware/software can scale and support the most mission critical environments. This has given early adopters of whitebox networking the confidence to deploy it in the enterprise data center.
Whitebox is only a data center technology…right?
White box has been so disruptive in the data center, why wouldn’t we want it everywhere?
As we visited the presenters of NFD14 who had been developing whitebox software and hardware (Big Switch Networks and Barefoot Networks), one idea in particular stood out in my mind – White box has been so disruptive in the data center, why wouldn’t we want it everywhere?
The use case for whitebox in the data center has grown so much in the last few years, that it’s now a major part of the conversation when selecting a vendor for new data centers that I’m involved with designing. This is a huge leap forward as most companies would have struggled with considering whitebox technology as recently as two or three years ago.
A clear advantage to come out of the hard work that whitebox vendors have done in marketing and selling data centers on the proposition of commodity hardware and independent operating systems is that it’s paved the way for whitebox to make it to the branch and edge of the network.
Vendor position on whitebox as an edge technology
The idea that whitebox can be used outside of the data center seems to be prevalent among the vendors we met with during NFD14. This is a question I specifically posed to both Barefoot and Big Switch and the answer was the same – both companies have developed technology that is reshaping the network engineering landscape and they would like to see it go beyond the boundaries of the data center.
I would expect in the next 12 to 18 months, we are going to see the possibility of use cases targeted to the edge and maybe even campus distribution/core. A small leaf spine architecture would be well suited to run most enterprise campuses and the CAPEX/OPEX benefits would be enormous. Couple that with smaller edge switches and you’ve got a really strong argument to make for ditching the incumbent network vendor as well as breaking out of vendor lock in.
And it makes a lot of sense for whitebox companies to expand into this market, there are already edge platforms in the world of commodity switching that support 48 ports of POE copper with 4 x 10 Gpbs uplinks. Aside from the obvious cost savings, imagine taking some of the orchestration/automation systems that are being used right now for the data center and applying them to problems like edge port provisioning or Network Access Control. Also, being able to support large wireless rollouts and controllers in a more automated fashion would be a huge win.
Role in Network Function Virtualization and the virtual enterprise branch
Network Function Virtualization (NFV) has gotten a lot of press lately as more and more organizations are virtualizing routers, firewalls, wan optimizers and now SDWAN appliances.
One of the endgames that I see coming out of the whitebox revolution is the marrying of NFV and whitebox edge switching to create a virtual branch in a box. The value to an enterprise is enormous here as the underlying hardware can be used in a longer design cycle while the software running on top can be refreshed to solve new business requirements as needed.
The other major benefit of hardware abstraction is that it simplifies orchestration and automation when interfaces are VLAN based and not tied to a specific port/number.
What are the challenges to getting whitebox into the hands of the average enterprise for edge or campus use?
While not an exhaustive list, these are a few of the challenges to getting whitebox into the average enterprise.
- Perception is one of the key challenges to moving towards whitebox in the edge. Most enterprises tend to be hesitant to be early adopters unless there is a clear business advantage to doing so.
- Vendor lock in is another major barrier as most enterprises tend to stay within one vendor for routing and switching.
- Confidence is a key part of the hardware selection process and this is an area that I feel whitebox is gathering serious momentum. And that will help make the edge case an easier sell when it becomes a more common use case.
- Training and Support is always one of the first questions asked by a network team to see how easy it will be to support and get the techies up to speed on care and feeding of the new deployment. This is another area of whitebox that has seen a huge amount of growth in the last few years. Big Switch has a fantastic lab for learning data center deployments and hopefully as the use cases expand, we’ll see the same high quality training for those areas as well.
Closing thoughts
Whitebox at the edge is closer than ever before and there are small pockets of actual deployments which are mostly in the service provider world.
However, we’ll likely have to wait until the use cases are specifically developed and marketed towards the enterprise before there is significant momentum in adoption. As a designer of whitebox solutions, it’s something that i’ll continue to push for and evaluate as it has the potential to make an enormous impact in enterprise networking.
That said, the future of whitebox is incredibly bright and 2017 should bring a significant amount of growth and more movement towards commodity switching as a mainstream technology in all areas of networking.
]]>
In another life, not too long ago, I spent a number of years in civilian and military law enforcement. When going through just about any kind of tactical training, one of the recurring themes they hammer into you is “situational awareness or SA.”
Wikipedia defines SA as:
Situational awareness or situation awareness (SA) is the perception of environmental elements with respect to time or space, the comprehension of their meaning, and the projection of their status after some variable has changed, such as time, or some other variable, such as a predetermined event. It is also a field of study concerned with understanding of the environment critical to decision-makers in complex, dynamic areas from aviation, air traffic control, ship navigation, power plant operations, military command and control, and emergency services such as fire fighting and policing; to more ordinary but nevertheless complex tasks such as driving an automobile or riding a bicycle.
Defining the need for SA in network engineering
It’s interesting to notice that critical infrastructure such as power plants and air traffic control are listed as disciplines that train in SA, however, I’ve never seen it taught in network engineering. In today’s world, the Internet has become as important as any other critical infrastructure and probably more in some ways. Network engineering shares many of the high pressure components as other critical infrastructure. Engineers are often forced to make decisions quickly under stress that can have a significant financial impact and may have regional, national or even global ramifications. Engineers that work supporting military, healthcare, public safety and telecom sectors have the additional responsibility of avoiding downtime that can risk the safety of life and property. When not under the immediate pressure of a high risk change or outage, network engineers are frequently given projects with timelines that are too short to plan properly and when the time to implement comes, unforeseen issues tend to pop up much more frequently. Understanding SA is key to ensuring that engineers focus on the right tasks at the right time and know when to ask for help, when to coordinate and even when to step back and stop working.
Why don’t we teach SA in networking?
This is largely, I suspect, one of the things network engineers are expected to acquire with experience and so it isn’t formally taught or is passed down from engineer to engineer. SA is something that is best taught as a combination of practical experience and both formal and informal training. The Cisco CCIE Route/Switch lab exam is probably one of the few examples of formal training that forces a network engineer to be aware of task priority as well as assessing the changing state of the network and responding appropriately. That said, after a brief google search, it does appear to be taught in cyber security as an adapted form of SA meant for military personnel. Much of the training tends to focus on how to avoid losing situational awareness by following certain methodologies and what to do if you realize you have lost SA.
An example of the loss of SA in networking.

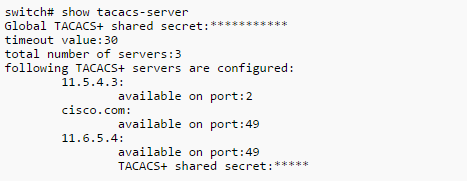
This is a scenario that just about every engineer can relate to…You’re working on a network cut and one of the tasks that you have to perform (which should be relatively quick) turns out to be quite difficult – because of a mis-configuration, bug, missing info, etc. A common example is network management config like SNMP, netflow, TACACS, etc. Let’s say you’re bringing a new L3 switch core online that involves physical link migration as well as new VLANs and OSPF/BGP. You have a 4 hour maintenance window and you start to work on an issue where your centralized TACACS server isn’t responding to the new switch – maybe it’s a security policy in the server or maybe you have the key wrong. You start to troubleshoot the issue with the expectation that you’ll have it solved in 10 or 15 minutes.
45 minutes later, you’re ALMOST there and so you put your head down and charge on through since you’re only 10 minutes away from solving the issue…right? Another 45 minutes go by and you’re at a complete loss as to why TACACS won’t work properly on this switch. Let’s pause for a moment and assess the status of the cut – we are now 1 hour and 30 minutes into the window and we have used almost half of the time on a single task. We still have to move physical links, ensure smooth L2 STP convergence when we add a new trunk and VLANs and L3 routing has to be brought online and tested with BGP and OSPF.
At this point, you’ve probably lost situational awareness because almost half of the time was spent on one task that is probably not critical to bringing a new L3 switch core online. This isn’t to say that ensuring the proper AAA isn’t important, but it’s a task that could be done in a follow up window the next night – or you might even extend your current maintenance window after the critical physical and route/switch pieces have been done. The point is, that in most environments, network management tasks aren’t as critical to configure as L2/L3 forwarding if you have to make a choice between the two based on time available.
There are probably thousands of scenarios like this one we could go through but the critical take away here is to understand exactly which items have to function in order to accomplish the overall goal. A secondary component to that is to understand where you can make compromises and still come away with a win – maybe in the example above, static routes are an acceptable temporary solution if you run into issues with dynamic routing.
SA concepts for network engineers
I’ve adapted some of the concepts from the US Coast Guard’s manual on SA to illustrate the important points and relevance for network engineers. The full text can be found here
Clues to the loss of SA
In reviewing a network outage or failed cut, you will often find one or more of these clues in hindsight as you try to figure out what went wrong.
- Confusion – If something isn’t quite right with the network as you’re working on it, but you can’t put your finger on it, trust your gut and share it with the engineering team or any other relevant parties. Likewise if you sense the team is generally confused about a critical task, don’t be afraid to take a step back and try to get clarification from the team. At worst you may have a short delay, but at best, you may discover some major gaps or other issues that need to be dealt with before moving forward. Confusion is the sworn enemy of communication.
- Deviation from the plan – we don’t always have the time to plan our network changes and it isn’t realistic to think that 100% of changes will be planned, but if you’re doing it right, most of the config that is put into the network should be planned and tested. When executing a network change, if you have to deviate from the planned config more than just a few lines, it might be worth putting the change on hold to assess whether or not your on-the-fly changes will upset things in other areas. Trying to think through all the dependencies of adding BGP route reflection in an entire data center at 3AM may not be the best choice to make.
- Unresolved Discrepancies – If the SYSLOG is churning through OSPF neighbor flapping entries, then maybe it isn’t the best time to introduce more OSPF changes. Understanding the state of the network before you make changes is key to avoiding breaking things even more. This seems like a very common sense approach, but all too often, we as engineers tend ignore the danger signs of an unstable network and try to fight our way through to “just get things working.” It’s far better to identify and resolve known issues before introducing new config that could be destabilizing – even if that means missing a target date in a project.
- Ambiguity – If there isn’t a great deal of clarity around the changes you plan to introduce into the network, then you’re setting yourself up for failure. If an engineer comes to me and says he wants “throw VLANs 100 through 110″ onto all the switches that need it”, I would probably challenge him to come back with the configuration required to do exactly that and in the process, we will probably have a much better understanding of the Layer 2 impact versus (con)figuring it out as we go.
- Fixation/Preoccupation – If we think back to the example earlier about spending an hour and a half on troubleshooting TACACS, that is a great example of fixation on one task. Unfortunately just about all of us have been there because it is so easy to lose sight of the bigger picture when you’re trying to get something to work. This is where a team of engineers can be very helpful. You might suggest to a member of the team who is head down and wrestling with a non-critical problem to refocus on the critical pieces and then the team can come back and work on the tasks together. If you’re working solo, then you have to be especially vigilant and self-policing when it comes to avoiding fixation/preoccupation.
Maintaining Awareness

- Communication – clear and effective communication, both verbal and written, is key to avoiding major issues. You should always strive to provide the right information in a timely manner to avoid ambiguity and confusion. It’s important to communicate things like a planned course of action as well as tasks that you are specifically charged with – even if it’s just to verify the information you have is accurate.
- Identify Problems – If you see a potential issue, don’t wait to bring it up. Sometimes, we as engineers are afraid to raise concerns for fear of looking foolish or uninformed, but harboring a concern and then voicing it once you’re in an outage situation doesn’t help anybody and certainly will make you feel foolish for not bringing it up when you had the chance.
- Continually Assess the Situation – Continually checking on the state of the network and the impact changes are having will keep you alert for any issues that may pop up. Many of the problems we have to go back and fix as network engineers are a direct result of incomplete validation after a change has been made. Another thought to consider here is that if you are a member of a team, you can delegate this task or ask for assistance so the burden isn’t entirely on you.
- Clarify expectations – If expectations and goals are not clearly defined, they can be hard to achieve. If it’s not understood that a network change is expected to cause an outage, you may have some unhappy campers on your hands because you didn’t clearly set the expectation.
The lone gunman effect on SA

There is no faster way to lose SA than to try and go it alone in the midst of a team environment…
One of the hardest things to do sometimes when functioning as a member of a team is to delegate tasks and responsibility. Especially if everyone on the team is not at the same technical level. That said, it’s typically not the best idea to be the lone gunman if you have resources available to utilize. Simple tasks like checking monitoring systems and logs can be assigned to team members with less experience and doing peer review of config can be helpful with more experienced engineers. To take this concept even further, if you have support from the network vendor available for peer review or even a dedicated engineer to sit in on a change window, always take advantage of that resource. Too often, we as engineers become consumed with being the go-to guy or gal and coming up with all the answers. What we should be doing is putting the success of the project first and using any resources available to ensure a successful network change or implementation.
Don’t be afraid to pull the emergency brake
If you find yourself in the middle of a bad situation or sense that you’re about to be in the middle of a major network outage, then STOP! One of the most important skills an engineer can possess is the ability to understand when to call it quits – at least for a brief period – until you can come back with a better plan. We’ve all had to make that gut wrenching call where we decide whether to plow forward or pull back and sometimes there isn’t much of a choice. Whenever you have the option, however, don’t hesitate to take it. The stakeholders will usually overlook schedule delays in the interest of preserving up-time. Also, demonstrating an understanding and respect for the business side of the house that depends on a functional network will probably buy you some goodwill with the business unit and increase the level of trust in your technical judgement.
Closing thoughts
Situational awareness for network engineers is mindset that we have to practice daily, but the overall learning curve is a long term process. We don’t always get it 100% perfect because we are human and subject to a number of external influences that compromise objectivity and work performance. The most important take away is to recognize, as other disciplines have, that there is value in understanding SA and the potential issues that come with losing SA. The next time you have a network cut, implementation or outage, take a minute to think through the SA concepts and how they relate to your specific corner of IP networking.
]]>
Rough specs are:
- 6 slot chassis
- Dual redundant 720 Gbps CPU modules
- Dual power
- 96 ports of copper 1 gig
- 48 1 gig SFP ports
- 16 Ten gig SFP+ ports
Apparently this device will coincide with the release of RouterOS version 8 in 2026 [an inside source at MikroTik named “Janis” confirmed this is a realistic target date.]
Many covert mAP-quadcopters died to bring us this information…these photos are NOT for public distribution.



And if you haven’t quite figured it out yet…APRIL FOOLS DAY!!!! But seriously MikroTik….we need this router. 
]]>

Recently, I was fortunate enough to be invited by Brian Horn with WISPA.org to teach a session at WISP America 2016 in Lousiville, KY. We had the class on Tuesday, March 15th 2016 and the turnout and response were great. Many different people have asked for the presentation, so I decided to go ahead and post it here. Hope this helps some of you who are trying to get into MPLS and although it does have a bit of a WISP focus, almost all of the concepts in the presentation apply to wireline networks as well.
About the presentation
Scope: This session was 30 minutes long with a Q&A afterwards, so the material is really a deep dive on MPLS. The goal was to introduce WISP engineers and owners to MPLS and how it improves the network as well as revenue.
When should I put MPLS in my WISP or Service Provider network? The answer is ASAP! I was asked this question by a small WISP earlier in the week and he said i’m just too small to be thinking about MPLS. My response to him was simply – “Do you want to get MPLS in and working well when you only have a handful of routers or do you want to wait until you have a large number of routers and the cost/complexity of adding MPLS will increase significantly?”
Link to PDF version of the presentation:
ISP Architecture – MPLS Overvew, Design and Implemention for WISPs
]]>
Happy New Year and welcome to the VM you can punish your routers with
Hello from stubarea51.net and Happy New Year! We are back from the holidays and recharged with lots of new stuff in the world of network engineering. If you ever thought it would be cool to put a full BGP table into a lab router, GNS3 or other virtualized router, you’re not alone.
A while back, I tackled this post and got everything up and running:
http://evilrouters.net/2009/08/21/getting-bgp-routes-into-dynamips-with-video/
First of all, thanks to evilrouters.net for figuring out the hard parts so we could build this into a VM. After basking for a while in the high geek factor of this project, it gave me an idea to build a VM that could be distributed among network engineers and IT professionals. The idea is to easily spin up one or more full BGP tables to test a particular network design or convergence speed, playing with BGP attributes, etc. After a few months of tweaking it and getting the VM ready for distribution, we finally are ready to put it out for everyone to use.
Network Diagram
Here is an overview of the topology we used for testing our full BGP table. This can be done a number of different ways and you can use just about any combination of Hypervisors including VM Ware and VirtualBox which are the two downloads included in this post. In this setup, we are using a MikroTik x86 VM to peer into the Ubuntu VM that has copies of the global table. It established an EBGP peering over 10.254.253.0/24 and takes in a full table.
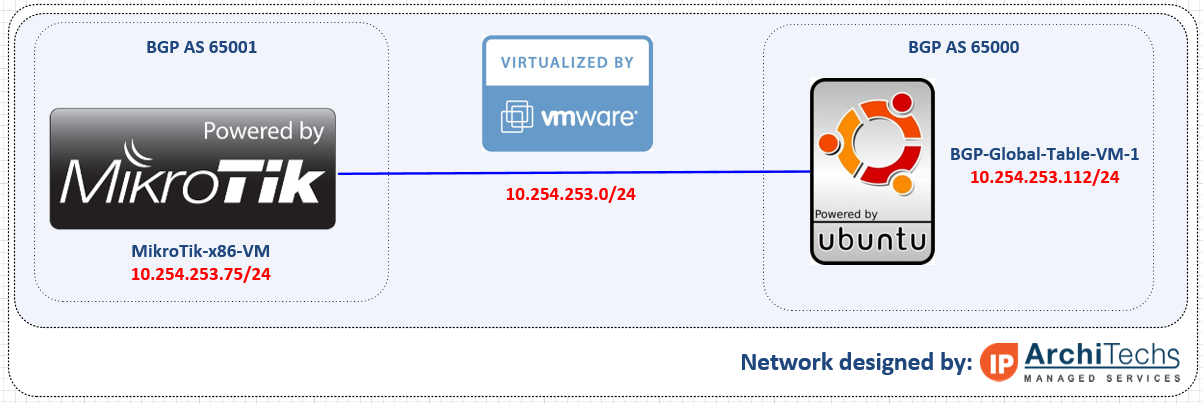
Getting started
First you need to download either the VM Ware or VirtualBox OVA files and import them into your hypervisor. The setup and installation of VM Ware ESXi or VirtualBox is beyond the scope of this post, so please google it if you need help.
Downloads
Powering up the VM
Once you have successfully imported the VM, you will get a screen that looks like this:
Credentials
Here are the credentials which you can change if needed.
username: bgpuser
password: bgpuser
sudo password: bgpuser
Bridging the VM NIC to your lab network
In order to have IP connectivity to another router (physical or virtual) you will need to setup the VM NIC to connect to the network you want to test on. There are a number of different ways to connect VMs into a virtual or physical network.
VM Ware – we connected the VM to the default VM management network (which is a physical server NIC) so it could reach other VMs and physical lab routers

VirtualBox – we bridged the VM to the NIC of the desktop we are running VirtualBox on so it could reach other VMs and physical lab routers
BGP Feeds that are used in this VM
The BGP feeds that are available come from the RIPE RIS Raw Data page and were archived in January 2016. We included 6 different tables from 4 continents so you can have up to 6 unique BGP tables to use in your lab testing. See the next section for the syntax to use for one of these files.
| RIPE RRC | File Name |
|---|---|
| rrc00.ripe.net | ISP1-Europe-Amsterdam-Jan-2016 |
| rrc01.ripe.net | ISP2-Europe-London-Jan-2016 |
| rrc06.ripe.net | ISP3-Asia-Tokyo-Jan-2016 |
| rrc15.ripe.net | ISP4-SouthAmerica-SaoPaulo-Jan-2016 |
| rrc11.ripe.net | ISP5-NorthAmerica-NewYork-Jan-2016 |
| rrc14.ripe.net | ISP6-NorthAmerica-PaloAlto-Jan-2016 |
Important Note !!!! – Using this VM does not provide connectivity to the Internet and will likely cause an outage when connected to a production network with live BGP peerings. This VM is intended to simulate an upstream peering for testing and lab development.
Setting up a BGP peering – BGP VM
Once you have IP connectivity and can ping the router you want to peer with, you can set up a peering on the VM. Here is the command syntax – first change to the bgp directory and issue the command below (with edits for your IPs and AS numbers)
bgpuser@Full-BGP-Global-Table-VM:~$ cd bgp bgpuser@Full-BGP-Global-Table-VM:~/bgp$ sudo ./bgp_simple.pl -myas 65000 -myip 10.254.253.112 -peerip 10.254.253.75 -peeras 65051 -p ISP1-Europe-Amsterdam-Jan-2016
Options for the BGP Peering (using the program bgp_simple ver 0.12)
bgpuser@Full-BGP-Global-Table-VM:~/bgp$ ./bgp_simple.pl
Please provide -myas, -myip, -peerip and -peeras!
bgp_simple.pl: Simple BGP peering and route injection script.
Version v0.12, 22-Jan-2011.
usage:
bgp_simple.pl:
-myas ASNUMBER # (mandatory) our AS number
-myip IP address # (mandatory) our IP address to source the sesion from
-peerip IP address # (mandatory) peer IP address
-peeras ASNUMBER # (mandatory) peer AS number
[-holdtime] Seconds # (optional) BGP hold time duration in seconds (default 60s)
[-keepalive] Seconds # (optional) BGP KeepAlive timer duration in seconds (default 20s)
[-nolisten] # (optional) dont listen at $myip, tcp/179
[-v] # (optional) provide verbose output to STDOUT, use twice to get debugs
[-p file] # (optional) prefixes to advertise (bgpdump formatted)
[-o file] # (optional) write all sent and received UPDATE messages to file
[-m number] # (optional) maximum number of prefixes to advertise
[-n IP address] # (optional) next hop self, overrides original value
[-l number] # (optional) set default value for LOCAL_PREF
[-dry] # (optional) dry run; dont build adjacency, but check prefix file (requires -p)
[-f KEY=REGEX] # (optional) filter on input prefixes (requires -p), repeat for multiple filters
KEY is one of the following attributes (CaSE insensitive):
NEIG originating neighbor
NLRI NLRI/prefix(es)
ASPT AS_PATH
ORIG ORIGIN
NXHP NEXT_HOP
LOCP LOCAL_PREF
MED MULTI_EXIT_DISC
COMM COMMUNITY
ATOM ATOMIC_AGGREGATE
AGG AGGREGATOR
REGEX is a perl regular expression to be expected in a
match statement (m/REGEX/)
Without any prefix file to import, only an adjacency is established and the received NLRIs, including their attributes, are logged.
Setting up a BGP peering – Your peering router
We used a MikroTik x86 VM in ESXi for this test, but any brand of virtual or physical router that supports BGP can be used.
[[email protected]] > routing bgp export # jan/21/2016 10:34:43 by RouterOS 6.30.1 # software id = KC33-08AQ # /routing bgp instance set default as=65001 /routing bgp peer add hold-time=30m keepalive-time=4m15s name=BGP-VM remote-address=10.254.253.112 remote-as=65000 ttl=default
Sit back and watch hundreds of thousands of prefixes torture the CPU of your router
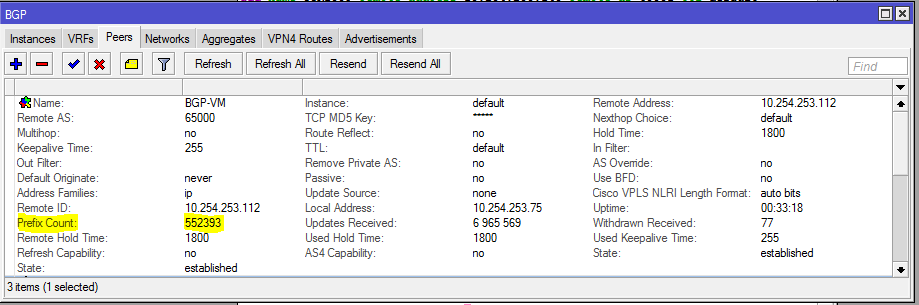
In the world of network engineering, learning a new syntax can challenging especially if you need a lot of detail quickly. The command structure for RouterOS can be a bit challenging sometimes if you are used to Cisco CLI commands. Most of us that have been in networking for a while got our start with Cisco gear and so it is helpful to draw comparisons between the commands, especially if you are trying to build a network with a MikroTik and Cisco router.
This is the first post in a series I’ve wanted to do for a while that creates a Rosetta stone essentially between IOS and RouterOS. We plan to tackle a number of other command comparisons like OSPF, MPLS and VLANs to make it easier for network engineers trained in Cisco IOS to successfully implement MikroTik / RouterOS devices. While many commands have almost the exact same information, others are as close as possible. Since there isn’t always an exact match, sometimes you may have to run two or three commands to get the information needed.
We plan to tackle a number of other command comparisons like OSPF, MPLS and VLANs to make it easier for network engineers trained in Cisco IOS to successfully implement Mikrotik / RouterOS devices.
Using GNS for testing
We used GNS3 to emulate both Cisco IOS and RouterOS so we could compare the different commands and ensure the translation was as close as possible.
BGP Commands
| Cisco Command | MikroTik Command |
|---|---|
| show ip bgp summary | routing bgp peer print brief |
| show ip bgp neighbor | routing bgp peer print status |
| show ip bgp neighbor 1.1.1.1 advertised-routes | routing bgp advertisements print peer=peer_name |
| show ip bgp neighbor 1.1.1.1 received-routes | ip route print where received-from=peer_name |
| show ip route bgp | ip route print where bgp=yes |
| clear ip bgp 172.31.254.2 soft in | routing bgp peer refresh peer1 |
| clear ip bgp 172.31.254.2 soft out | routing bgp peer resend peer1 |
| BGP-Cisco(config)#router bgp 1 | /routing bgp instance set default as=2 |
| BGP-Cisco(config-router)#neighbor 172.31.254.2 remote-as 2 | /routing bgp peer add name=peer1 remote-address=172.31.254.1 remote-as=1 |
| BGP-Cisco(config-router)#network 100.99.98.0 mask 255.255.255.0 BGP-Cisco(config-router)#network 100.99.97.0 mask 255.255.255.0 BGP-Cisco(config-router)#network 100.99.96.0 mask 255.255.255.0 | /routing bgp network add network=100.89.88.0/24 add network=100.89.87.0/24 add network=100.89.86.0/24 |
| BGP-Cisco(config)#router bgp 1 BGP-Cisco(config-router)#neighbor 172.31.254.2 default-originate | /routing bgp peer add default-originate=always name=peer1 remote-address=172.31.254.1 remote-as=1 |
Examples of the MikroTik RouterOS commands from the table above
[admin@BGP-MikroTik] > routing bgp peer print brief
This is a quick way to get a list of peers/AS and their status

[admin@BGP-MikroTik] > routing bgp peer print status
This is a command that will give you more detailed information about a BGP peer including MD5 auth, timers, prefixes received and the state of the peering as well as other info.

[admin@BGP-MikroTik] > routing bgp advertisements print peer=peer_name
This will allow you to see what BGP prefixes are actually being advertised to a peer and the nexthop that will be advertised

[admin@BGP-MikroTik] > ip route print where received-from=peer_name
This will allow you to see what BGP prefixes are actually being received from a peer and the nexthop that will be advertised

[admin@BGP-MikroTik] > ip route print where bgp=yes
This will allow you to see what all BGP prefixes that are in the routing table – both active and not. This is a slight difference between Cisco and MikroTik since Cisco keeps BGP routes that aren’t in the routing table in the bgp table, whereas MikroTik routers keep all routes in the routing table with a distinction between active and not.

[admin@BGP-MikroTik] > routing bgp peer refresh peer_name
This will allow you to force the BGP peer to resend all prefixes without tearing down the peering – similar to a soft clear in Cisco IOS.
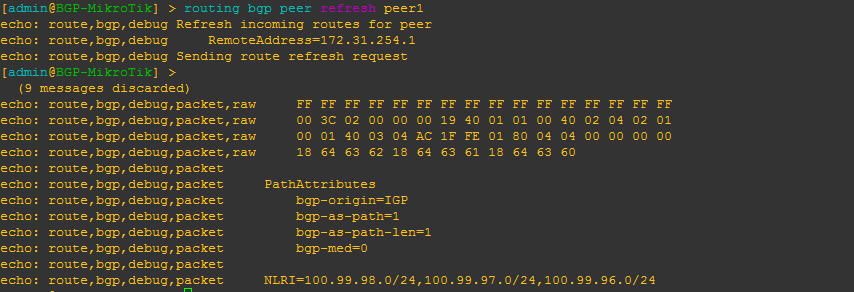
[admin@BGP-MikroTik] > routing bgp peer resend peer_name
This will allow you to force RouterOS to resend all prefixes to the peer without tearing down the peering – similar to a soft clear in Cisco IOS.
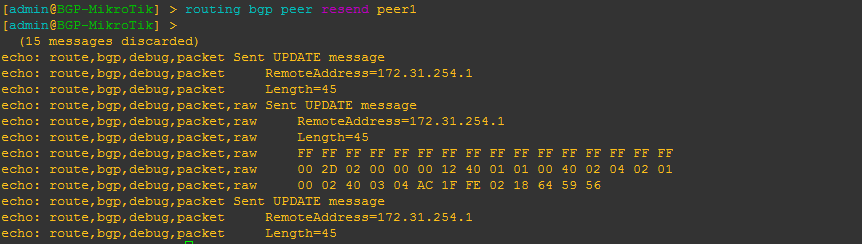
Configure BGP instance and peering
Here is a very basic BGP peering config with the minimum required to get BGP running for RouterOS. It includes setting the BGP AS, a peering and several networks to advertise.
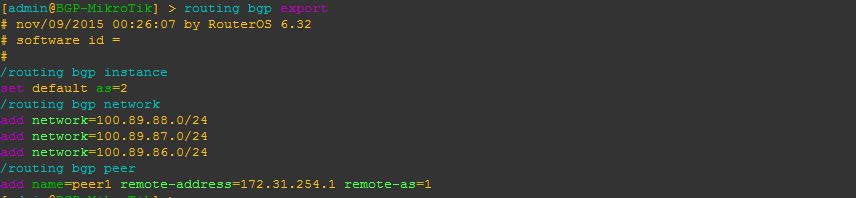
Originate a default route to a specific peer
This will configure the peering to originate or advertise a 0.0.0.0/0 route to the peer regardless of whether or not a default route already exists in the routing table. You can use the alternate default-originate=if-installed to only advertise a default route if one exists in the routing table.

More to come
There are so many commands to consider for BGP, we probably could have added close to 100, but we decided to list the commands we use the most often to start with and will be adding to the list of BGP commands as well as others like OSPF, MPLS and VLANs in future posts.
]]>
[adrotate banner=”5″]
Why we chose PPPoE as the next test
First of all, thanks to everyone for all the positive feedback, comments and questions about the CCR1072-1G-8S+ testing we have been posting in the last few months. Even MikroTik has taken an interest in this testing and we have gotten some great feedback from them as well.
We received more questions about the PPPoE capabilities of the CCR1072-1G-8S+ than any other type of request. Since we have already published the testing on BGP, throughput and EoIP, we have decided to tackle the PPPoE testing to understand where the limits of the CCR1072-1G-8S+ are. This is only a preview of the testing as we are working on different methods of testing and config, but this will at least give you a glimpse of what is possible.
30,000 PPPoE Connections !!!!

Overview of PPPoE connections and CPU load
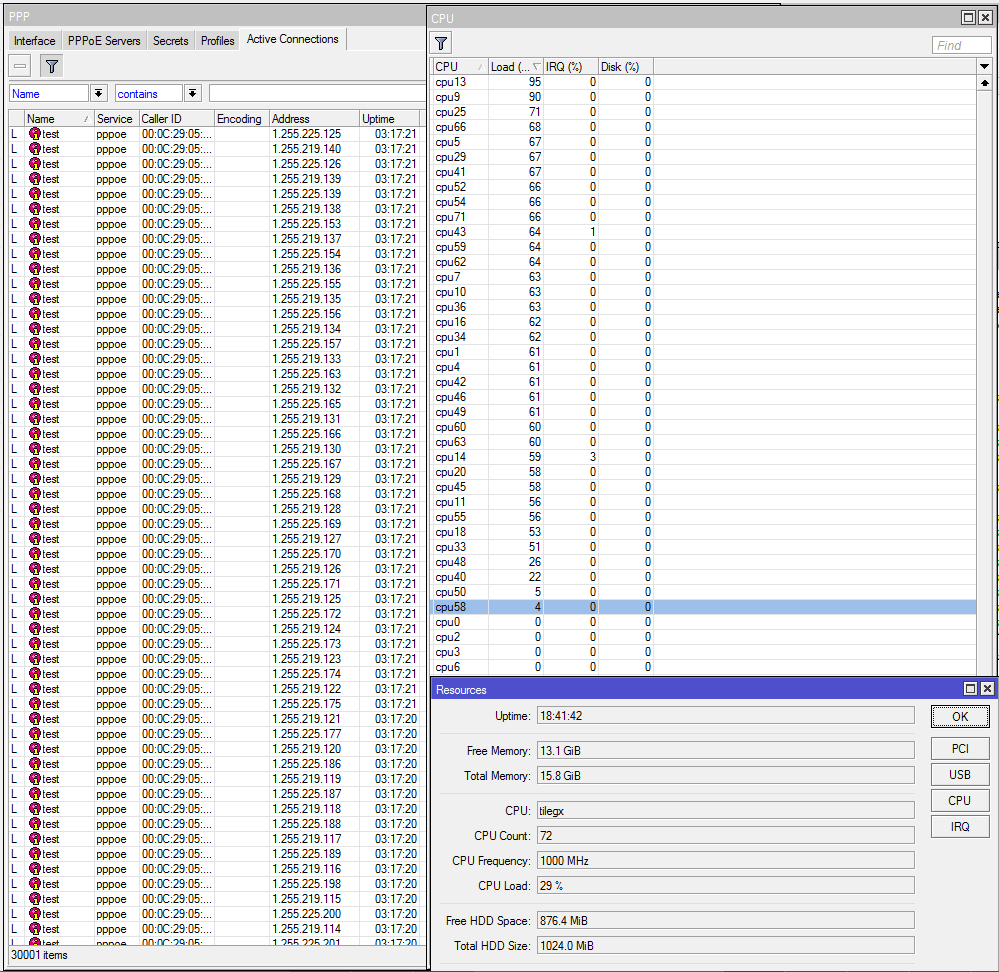
PRTG Monitoring
We have started using PRTG in the StubArea51.net lab as it makes monitoring of resource load over time much easier when we are testing. Check it out as it is free up to 100 sensors and works very well with MikroTik
https://www.paessler.com/prtg/download
PRTG CPU Profile
PRTG PPPoE connection count over time
It took us about 20 minutes to reach 30,000 connections…we are working on tuning the config to see if we can shorten the time it takes to build the connections. In the graph here, you can see it go form a 24 hour stable load of 30k connections donw to nothing as we prepare for a load test. At about 10:07 AM is when we started the full load test and you can see the time it takes to get to 30k.
More on the way!!!
This is just a small preview of our full PPPoE testing. We will be completing testing and should be publishing the results within the next week.
]]>[adrotate banner=”5″]
[metaslider id=282]
Getting to 10 Gbps using EoIP
The EoIP tunnel protocol is one of the more popular features we see deployed in MikroTik routers. It is useful anywhere a Layer 2 extension over a Layer 3 network is needed and can be done with very little effort / complexity. One of the questions that seems to come up on the forums frequently is how much traffic can an EoIP tunnel handle which is typically followed by questions about performance with IPSEC turned on. Answers given by MikroTik and others on forums.mikrotik.com typically fall into the 1 to 3 Gbps range with some hints that more is possible. We searched to see if anyone had done 10 Gbps over EoIP with or without IPSEC and came up empty handed. That prompted us to dive into the StubArea51 lab and set up a test network so we could get some hard data and definitive answers.
The EoIP protocol and recent enhancements
Ethernet over IP or EoIP is a protocol that started as an IETF draft somewhere around 2002 and MikroTik developed a proprietary implementation of it that has been in RouterOS for quite a while. Similar to EoMPLS or Cisco’s OTV, it faciltates the encapsulation of Layer 2 traffic over a Layer 3 network such as the Internet or even a private L3 WAN like an MPLS cloud. If you follow MikroTik and RouterOS updates closely, you might have come across a new feature that was released in version 6.30 of RouterOS.
What's new in 6.30 (2015-Jul-08 09:07): *) tunnels - eoip, eoipv6, gre,gre6, ipip, ipipv6, 6to4 tunnels have new property - ipsec-secret - for easy setup of ipsec encryption and authentication;
This is a much anticipated feature as it simplifies the deployment of secure tunnels immensely. It makes things so easy, that it really gives MikroTik a significant competitive advantage against Cisco and other vendors that have tunneling features in their routers and firewalls. When you look at the complexity involved in deploying a tunnel over ipsec in a Cisco router vs. a MikroTik router, there is a clear advantage to using MikroTik for tunneling. I originally looked into this feature for EoIP but it is available many other tunnel types like gre, ipip and 6to4.
When you look at the complexity involved in deploying a tunnel over ipsec in a Cisco router vs. a MikroTik router, there is a clear advantage to using MikroTik for tunneling.
Here is one of the simpler implementations of L2TPv3 over IPSEC in a Cisco router which still has a fair amount of complexity surrounding it.
http://www.cisco.com/c/en/us/support/docs/security/flexvpn/116207-configure-l2tpv3-00.html
VS.
http://wiki.mikrotik.com/wiki/Manual:Interface/EoIP
The MikroTik config has 3 required config items for EoIP on each router vs double the steps with Cisco and the added complexity of troubleshooting IPSEC if you get a line of config wrong.
The test network
In order to test 10 Gbps speed over EoIP, we needed a 10 Gbps capable test network and decided to use two CCR-10368G-2S+ as our endpoints and a CCR1072-1G-8S+ as the core WAN. We used an HP DL360-G6 with ESXi as the hypervisor to launch our test VMs for TCP throughput. We typically use VMs instead of MikroTik’s built in bandwidth tester because they can generate more traffic and have more granularity to stage specific test conditions (TCP window, RX/TX buffer, etc).
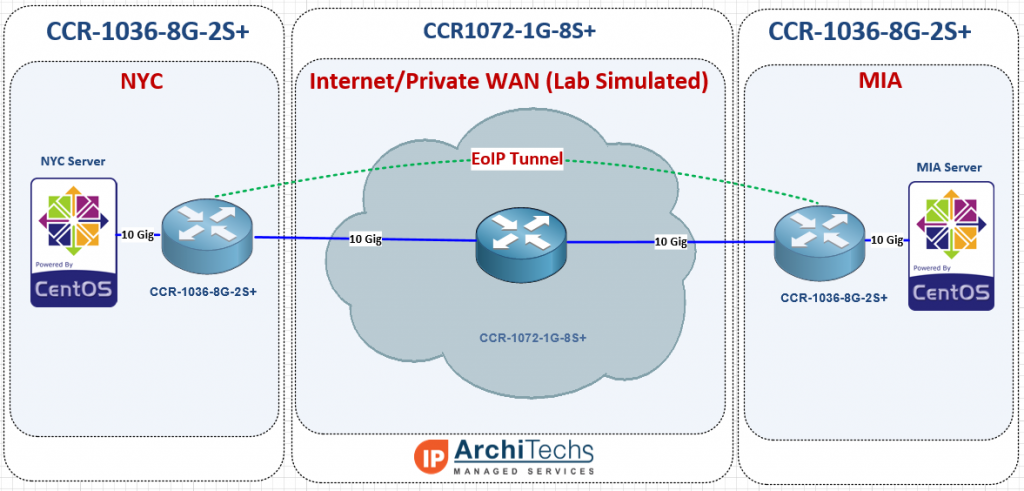
Concept of testing
Most often, EoIP is implemented over the Internet and so using 9000 as a test MTU might be surprising to some users and possibly irrelevant, but when using a private WAN, quite often a Layer 3 solution is much less expensive than Layer 2 handoffs (especially at 10 Gbps) and 9000 bytes is almost always supported on that kind of transport, so L2 over private L3 definitely has a place as a possible application for EoIP with 9000 byte frames.
9000 byte MTU unencrypted
9000 byte MTU encrypted with IPSEC
1500 byte MTU unencrypted
1500 byte MTU encrypted with IPSEC
And the results are in!!! 10 Gbps is possible over EoIP
10 Gbps over EoIP (Unencrypted with 9000 byte MTU)
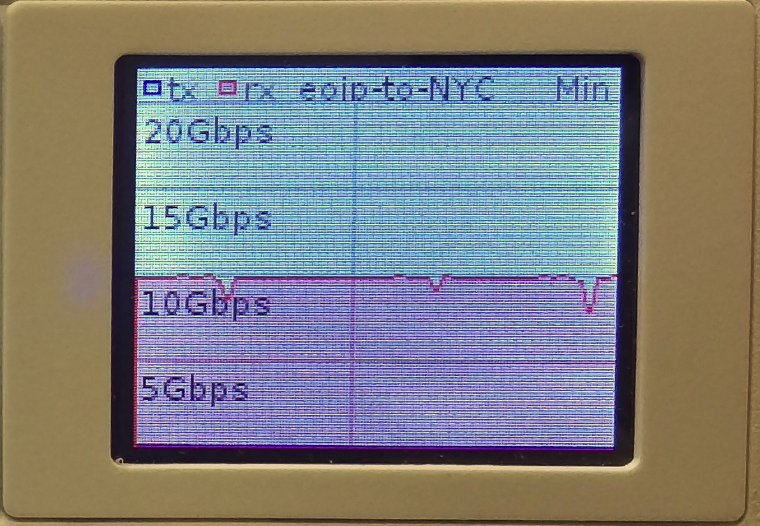
Video of 10 Gbps over EoIP (Unencrypted with 9000 byte MTU)
7.5 Gbps over EoIP (IPSEC encrypted with 9000 byte MTU)
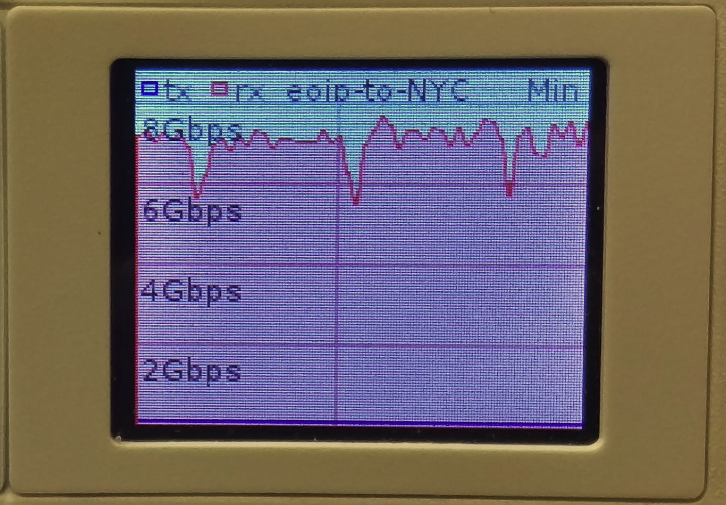
Video of 7.5 Gbps over EoIP (IPSEC encrypted with 9000 byte MTU)
6.4 Gbps over EoIP (Unencrypted with 1500 byte MTU)
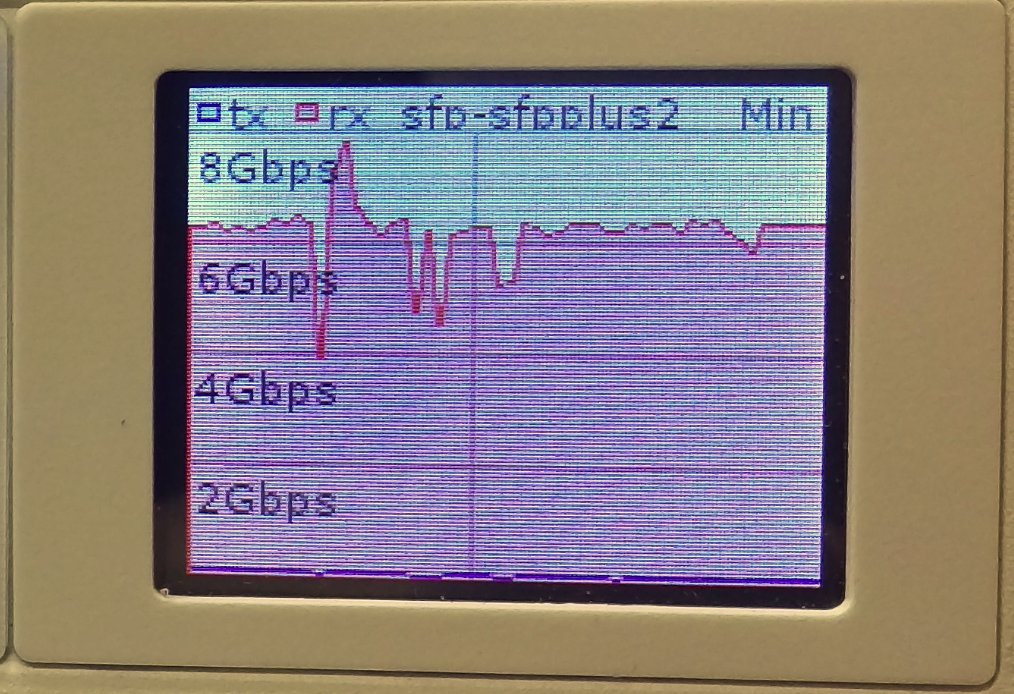
Video of 6.4 Gbps over EoIP (Unencrypted with 1500 byte MTU)
1.7 Gbps over EoIP (IPSEC encrypted with 1500 byte MTU)
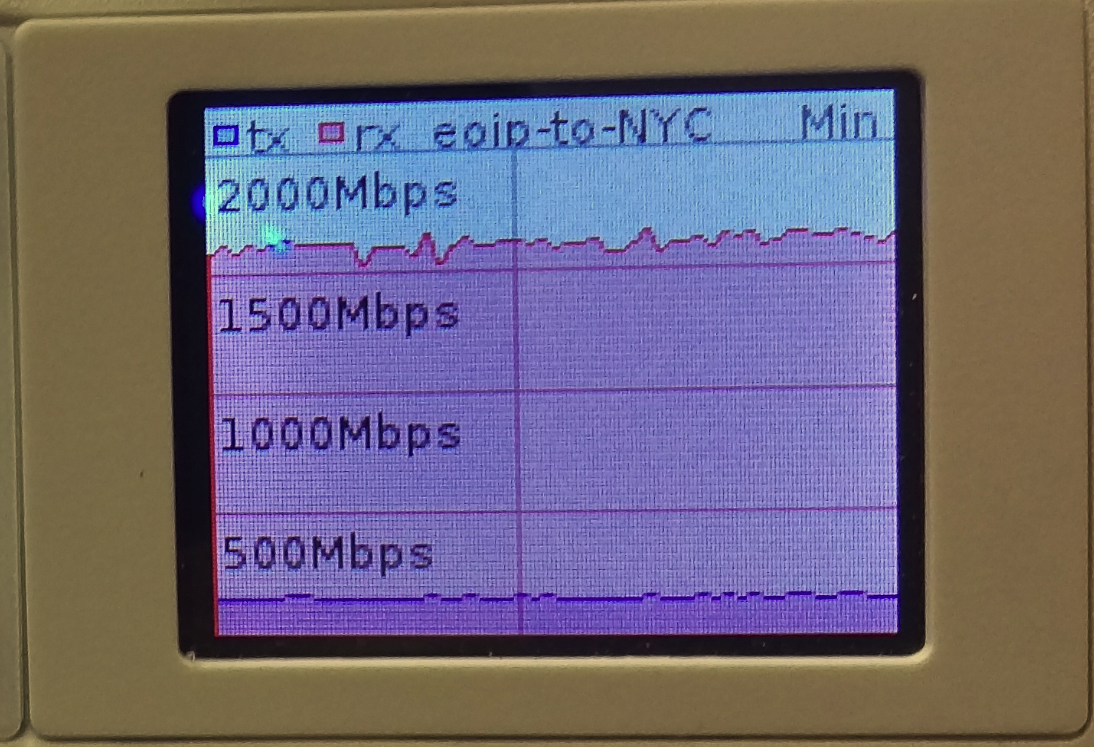
Video of 1.7 Gbps over EoIP (IPSEC encrypted with 1500 byte MTU)
Video will be posted soon.
Use cases and conclusions
The CCR1036 certainly had no issues getting to 10 Gbps with the right MTU and test hardware, but we were suprised that the IPSEC thoughput was so high. Considering a pair of CCR1036-8G-2S+ routers are just a little over $2000.00 USD, 7.5 Gigabits of encrypted throughput with IPSEC is incredible. Even over a 1500 byte MTU, the 1.7 Gbps we were able to hit is amazing considering it would probably take at least 20k to 30k USD to reach that kind of encrypted throughput with equipment from a mainstream network vendor like Cisco or Juniper.
Use cases for this are probably too numerous to mention but we came up with a few
- Extending an ISP or joining two or more ISPs in different regions
- High volume PPPoE backhaul to a BRAS
- Data Center Interconnect (DCI) at Layer 2
- Enterprise HQ and Branch connectivity or backup
- Layer 2 network extension for network migration or merger.
Please feel free to leave comments with questions about the testing or use cases we might not have thought of…we love getting feedback
[metaslider id=249]
The 80 Gbps barrier has finally been broken (and yes we are rounding up) !!!!
Well at least it has been reached by someone other than MikroTik. It’s taken us quite a while to get all the right pieces to push 80 Gbps of traffic through the CC1072 but with the latest round of servers that just got delivered to our lab, we were able to go beyond our previous high water mark of 54 Gbps all the way to just under 80 Gbps. There have been a number of questions about this particular router and what the performance will look like in the real world. While this is still a lab test, we are using non-MikroTik equipment and iperf which is considered an extremely accurate performance measuring tool for TCP and UDP.
Video of the CCR1072-1G-8S+ in action (Turn up your volume to hear the roar of the ESXi servers as they approach 80 Gbps)
How we did it – The Hardware
CCR1072-1G-8S+ – Obviously you can’t have a test of the CCR1072 without one to test on. Our CCR1072-1G-8S+ is a pre-production model so there are some minor differences between it and the units that are shipping right now.

HP DL360-G6 – It’s hard to find a better value in the used server market than the HP DL360 series. This series of server can be found on ebay for under $500 USD in general and makes a great ESXi host for development and testing work.

Intel x520-DA2 10 Gbps PCI-E NIC – This NIC was definitely not the cheapest 10 gig NIC on the market, but after some research, we found it was one of the most compatible and stable across a wide variety of x86 hardware. The only downside to using this particular NIC is the requirement to use INTEL branded SPF+ modules. We tried several types of generics and after reading some forums posts, we were able to figure out that it only takes a few different types of INTEL SFP+ modules. This didn’t impact performance in any way but doubled the cost of the SFPs required.

How we did it – The Software
RouterOS – We tried several thoughought the testing cycle, but settled on 6.30.4 bugfix.
iperf3 – If you need to generate traffic for a load test, this is probably one of the best programs to use.
VM Ware ESXi 6.0 – There were certainly a fair amount of hypervisors to choose from, and we even considered a Docker deployment for the performance advantages but in the end, VM Ware was the easiest to deploy and manage since we needed some flexibility in the vswitch and 9000 MTU.

CentOS 6.6 Virtual Machines – We chose CentOS as the base OS for TCP throughput testing because it supports VM Ware tools and the VMXNET3 paravirtualized NIC. It is not possible to get a VM to 10 Gbps of throughput without using a paravirtualized NIC so this limits the range of Linux distros to mainstream types like Ubuntu and CentOS. Also, we tend to use CentOS more than the other flavors of linux and so it allowed us to get the VMs ready quickly to generate traffic.

Network Topology for the test – We essentially had to put two VLANs on every physical interface so that the link could be fully loaded by using the 1072 to route between VLANs. A VM was built on each VLAN and tagged in the vswitch for simplicity. In earlier tests, we tried to use LACP between ESXi and the 1072 but had problems loading the links fully with the hashing algorithms we had available.
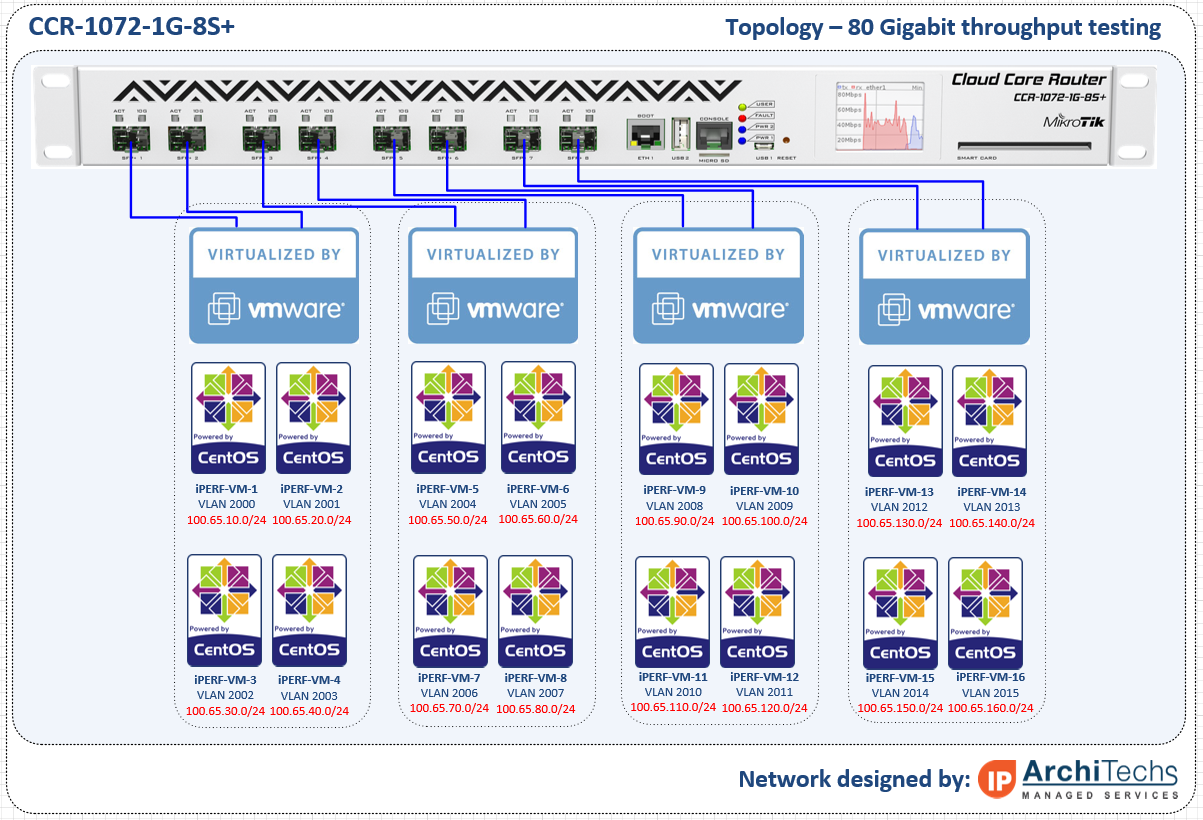
RouterOS Config for the test
www.iparchitechs.com/iparchitechs.com-ccr1072-80gig-test-config.rsc
Conclusions, challenges and what we learned
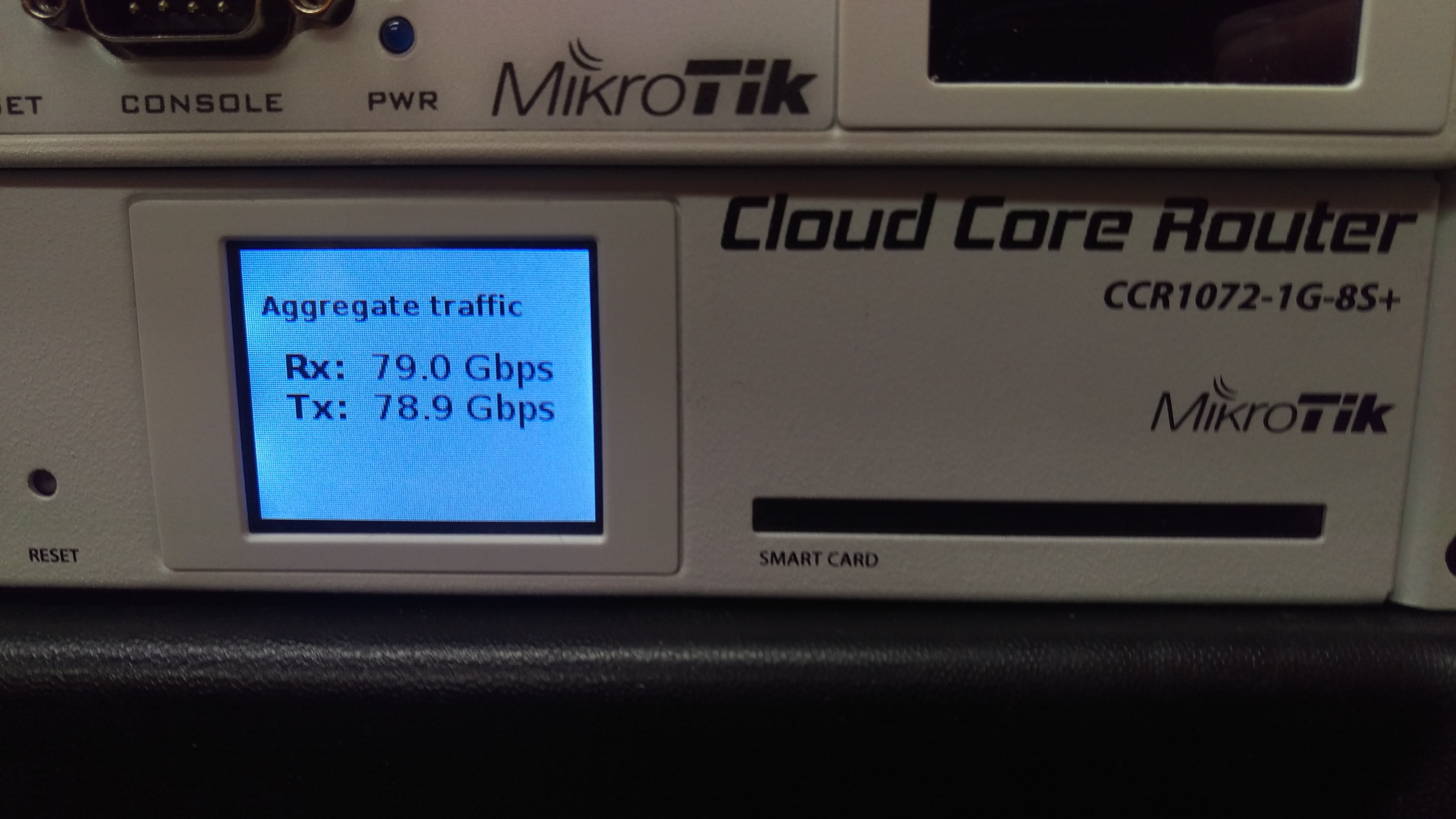
The CCR1072-1G-8S+ is an extremely powerful router and had little difficulty in reaching full throughput once we were able to muster enough resources to load all of the links. As RouterOS continues to develop and moves into version 7, this router has the potential to be extremely disruptive to mainstream network vendors. At $3,000.00 USD list price, this router is ab absolute steal for the performance, 1U footprint and power consumption. Look for more and more of these to show up in data centers, ISPs and enterprises.
Challenges
There have been a number of things that we have had to work through to get to 80 Gbps but we finally got there.
- VMWARE ESXi – LACP Hashing – Initially we built LACP channels between the ESXi hosts and the 1072 expecting to load the links by using multiple source and destination IPs but we ran into issues with traffic getting stuck on one side of the LACP channel and had to move to independent links.
- Paravirtualized NIC – The VM guest OS must support a paravirtualized NIC like VMXNET3 to reach 10 Gbps speeds.
- CPU Resources – TCP consumes an enormous amount of CPU cycles and we were only able to get 27 Gbps per ESXi host (we had two) and 54 Gbps total
- TCP Offload – Most NICs these days allow for offloading of TCP segmentation by hardware in the NIC rather than the CPU, we were never able to get this working properly in VM WARE to reduce the load on the hypervisor host CPUs.
- MTU – While the CCR1072 supports 10,226 bytes max MTU, VMWARE vswitch only supports 9000 so we lost some potential throughput by having to lower the MTU by more than 10%
What we learned
- MTU – In order for the CCR1072-1G-8S+ (and really any MikroTik) to reach maximum throughput, the highest L2/L3 MTU (we used 9000) must be used on:
- The CCR
- The Guest OS
- The Hypervisor VSWITCH
- Hypervisor Throughput – Although virtualization has come a long way, there is still a fair amount of performance lost especially in the network stack when putting a software layer between the Guest OS and the Hardware NIC.
- CPU Utilization with no firewall rules or queues is very low. We haven’t had a chance to test with queues or firewall rules but CPU utilization never went above 10% across all cores.
- TCP tuning for 10 Gbps in the Guest OS is very important – see this link: https://fasterdata.es.net/host-tuning/linux/
Please comment and let us know what CCR1072-1G-8S+ test you would like to see next!!!
]]>[adrotate banner=”4″]
Breaking the 80 Gbps barrier!!!

The long wait for real-world 1072 performance numbers is almost over – the last two VMWARE server chassis we needed to push the full 80 Gpbs arrived in the StubArea51 lab today. Thanks to everyone who wrote in and commented on the first two reviews we did on the CCR-1072-1G-8S+. We initially began work on performance testing throughput for the CCR1072 in late July of this year, but had to order a lot of parts to get enough 10 Gig PCIe cards, SFP+ modules and fiber to be able to push 80 Gbps of traffic through this router.
Challenges
There have been a number of things that we have had to work through to get to 80 Gbps but we are very close. This will be detailed in the full review we plan to release next week but here are a few.
- VMWARE ESXi – LACP Hashing – Initially we built LACP channels between the ESXi hosts and the 1072 expecting to load the links by using multiple source and destination IPs but we ran into issues with traffic getting stuck on one side of the LACP channel and had to move to independent links.
- CPU Resources – TCP consumes an enormous amount of CPU cycles and we were only able to get 27 Gbps per ESXi host (we had two) and 54 Gbps total
- TCP Offload – Most NICs these days allow for offloading of TCP segmentation by hardware in the NIC rather than the CPU, we were never able to get this working properly in VM WARE to reduce the load on the hypervisor host CPUs.
- MTU – While the CCR1072 supports 10,226 bytes max MTU, VMWARE vswitch only supports 9000 so we lost some potential throughput by having to lower the MTU by more than 10%
Results preview
Here is a snapshot of where we have been able to get to using 6.30.4 bugfix so far
Single TCP Stream performance at 10 Gig in iperf at 9000 bytes MTU (L2/L3)

Throughput in WinBox

Max throughput so far with two ESXi 6.0 hosts (HP DL360 G6 with 2 Intel Xeon x5570 CPUs)

Two more servers arrived today – Full results coming very soon!
Once we hit the performance limit at 54 Gbps, we ordered two more servers and they just arrived. We will be racking them into the lab immediately and should have some results by next week. Thanks for being patient and check back soon!!
]]>
[adrotate banner=”4″]
As we all patiently await the release of RouterOS (RoS) v7 beta, MikroTik has announced a change in the way RoS development is organized. There will now be three different tracks of development:
Bugfix only – When a current build is released, only fixes to known bugs will be added to this branch of development
Current – Current release will contain bugfixes and new features
Release Candidate – The release candidate will remain the development build for the next “current” release.
Graphical Overview of the new development cycle
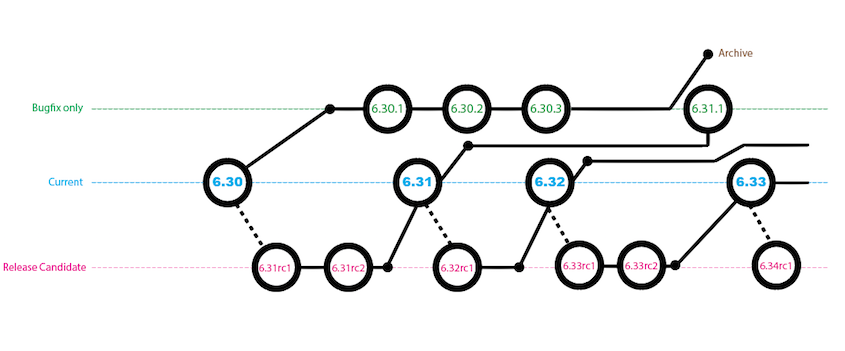
Image and notes below are from here
A small addendum: the Bugfix only will only contain verified fixes, and no new features. The Current release contains the same fixes but also new features and other improvements, sometimes also less critical fixes than in Bugfix. And finally the Release Candidate is more likely to a nightly build. We will not to intensive testing before publishing these, only quick check if upgrade can be done and if most features work fine.
Origin
The idea originally came out of this thread and after a flurry of positive commentary, it became a working practice shortly therafter.
We plan to make sub-version releases that only contain fixes and no new features.
For example, we would release 6.30 with some new features in FastPath. Then, if some issues are found, we would make 6.30.1 with only fixes and no new functionality. When we add a new option or feature, we would make 6.31.
6.XX.Y – only bug fixes
6.XX – fixes and feature changesWe could even make several fix-only releases in a row, if needed.
The idea is that you can upgrade to a sub-point release without risking new bugs, that could come with new features being added.
As the v6 cycle is coming to an end, there is simply no other ‘branch’ to put new features in, as v7 is still too ‘raw’. We could stop with the sub-point releases once v7 is mature enough for general use.
MikroTik download page gets a slight refresh with a new drop down
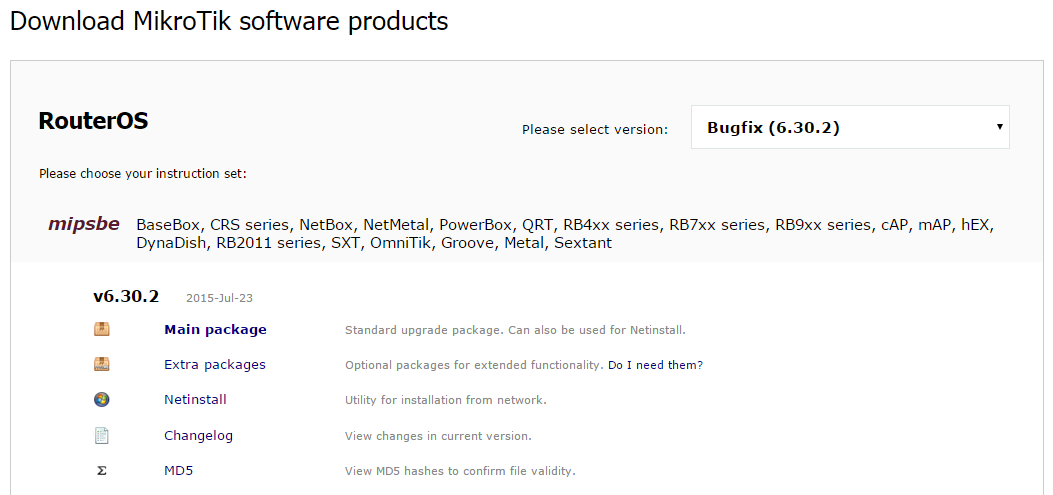
Thoughts
This a very positive change for MikroTik and will go a long way with customers and integrators to be able to select code based on the needs of the environment. This release cycle is very similar to other network vendors (Think of Cisco IOS General Deployment vs Maintenance Deployment) and works well.
Code selection is such a critical element to the stability of a network and it’s helpful to have the ability to load a RoS code that has been patched but without new features. It’s a bit early to tell as to how much of an impact this will make in the MikroTik community, but the results so far look promising. I’ve done upgrades on a number of CCRs and 2011 series routers from 6.30 –> 6.30.1 –> 6.30.2 bugfix only and haven’t seen any major stability issue s or other bugs when running on a BGP/MPLS/OSPF service provider network.
There was a lot of churn with bugs and working features breaking early on in 6.x and this change should help to avoid at least some of that upheaval when 7.x makes it to a “current” release.
]]>
Here is Part 1 of the CCR1072-1G-8S+ review in case you missed it!
CCR1072-1G-8S+ Ultimate BGP Performance test
After many days of testing, Part 2 is finally here! Welcome to the stubarea51.net BGP gauntlet. We subjected the CCR1072 to different types of network torture stress testing. Continuing on from our initial review, we chose BGP as the first way to test the limits and capacity of the CCR1072-1G-8S+.
Here is an overview of our lab environment to test the new CCR
- CCR1072-1G-8S+
- CCR1009-8G-1S-1S+
- CRS-125-24G-1S+
- x86 VMs on ESXi 6.0 for upstream BGP peering
- (2) ESXi 6.0 Hosts with 20 Gb (4×10) connectivity
- Multimode 10 gig SFP+ using 50/125 OM3 fiber
All RouterOS devices were loaded with the latest stable code (6.30.1 at the time of testing)
Network Design of the StubArea51 LAB setup for BGP testing
For this series of testing, we took our two ESXi 6.0 hosts and built a number of VMs using RouterOS and Ubuntu to supply the 1.21 Gigawatts 3.6 Million routes we would need to beat up on the CCR1072 for a few days. If you’re not familiar with the RIPE Routing Information Service (RIS) project, go here to take a look at the routing tables we used. Because the route server does not load routes nearly as quickly as a router, we used a CCR-1009-1S-1S+ to take in a single copy of the 457,461 routes in the Palo Alto IX public BGP table (July 2015). Then we set up eBGP peerings between the CCR1009 and each of the 8 BGP upstream VMs to give the CCR1072 plenty of peers. We also put two iBGP VMs in the same AS as the 1072 so we could test the route reflection capabilites of the CCR1072.
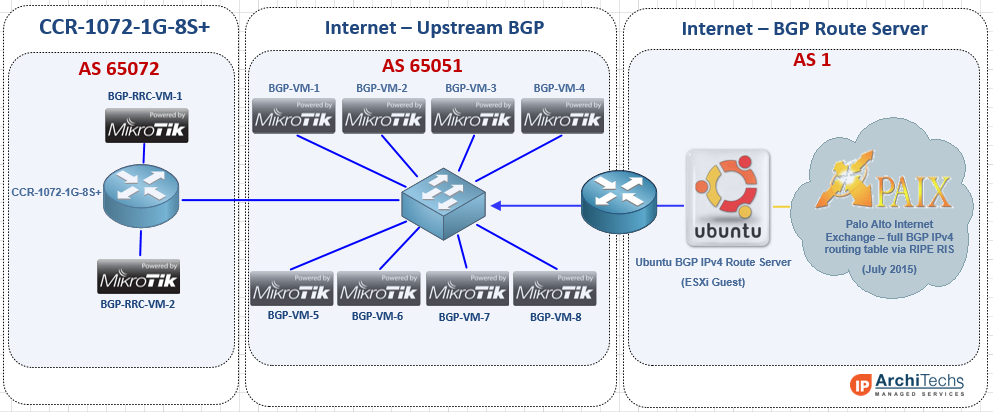
Concept of Testing in v6.30.1
One of the first things we wanted to test on the CCR-1072-1G-8S+ was how quickly it handled large BGP routing tables. It is probably a good idea to take a slight detour here and mention that in version 6 of RouterOS, the BGP process is not multi-threaded, so it is limited to one core. As such, there are improvements MikroTik is working on to make pulling in large BGP tables faster and more efficient. Here is that discussion in the MikroTik forums:
http://forum.mikrotik.com/viewtopic.php?t=69931
Next generation of code – RouterOS v7
After exhibiting and presenting at the USA MUM 2015 in Miami, we had a lot of time to talk to MikroTik and get some insight on what is happening with optimizing BGP in RouterOS. MikroTik has seen major BGP performance improvements in v7. I seem to remember a slide that was presented at the MUM with some specific performance numbers on v7 but I couldn’t find it. I did come across a slide from the 2014 MUM in Russia that talks about the routing improvements in v7:
This presentation on CCR Tips and Tricks by Janis Megis from that MUM is available here

Testing Results
Here are the results of the BGP testing we have done that list:
- How many peers are used
- How many total routes are taken in
- How long it took to fully converge
- VRF performance results (if applicable)
- Route-reflection performance results (if applicable)
Public BGP Table – IPv4 with 1 upstream peer (457,461 routes – 1 Minute 33 seconds)
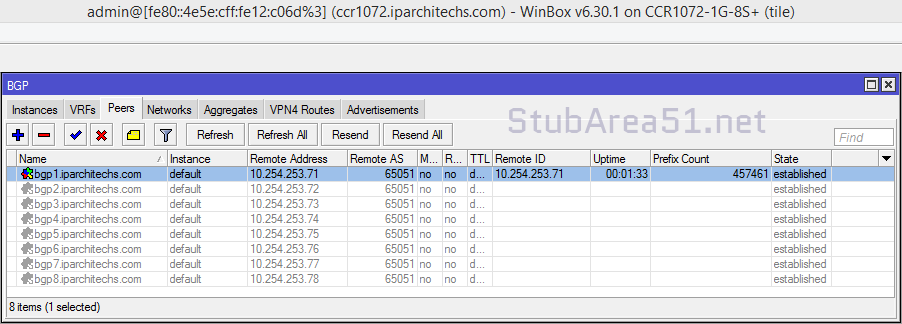
Public BGP Table – IPv4 with 2 upstream peers (914,922 routes – 3 Minutes 25 seconds)
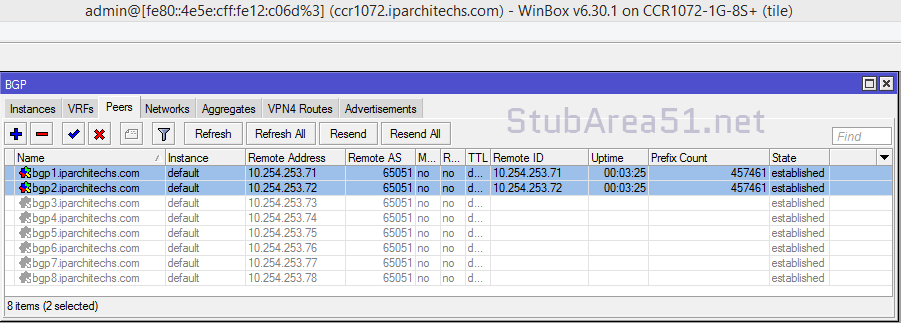
Public BGP Table – IPv4 with 4 upstream peers (1,829,844 routes – 7 Minutes 8 seconds)
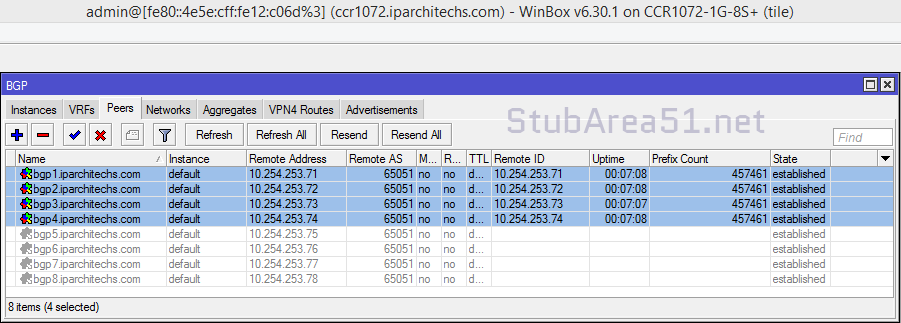
Public BGP Table – IPv4 with 8 upstream peers (3,659,688 routes – 13 Minute 17 seconds)
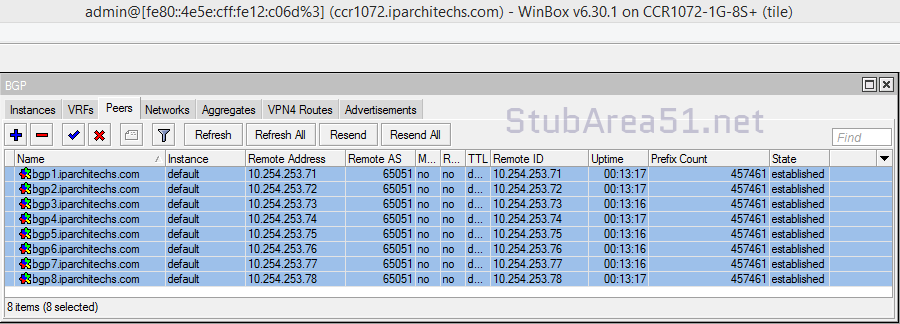
Public BGP Table – IPv6
Unfortunately, we did not have a way to test a full IPv6 BGP table in our lab. We are working on enabling that for future testing and will update once we have some results.
BGP Performance in a VRF – IPv4 with 8 upstream peers (3,659,688 routes – 15 Minutes 45 seconds)
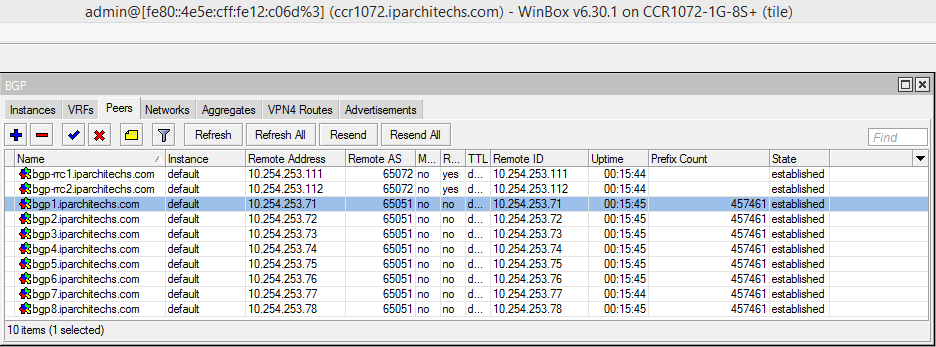
BGP Route Reflection – 2 clients (914,922 routes sent – 1 Minute 53 seconds)
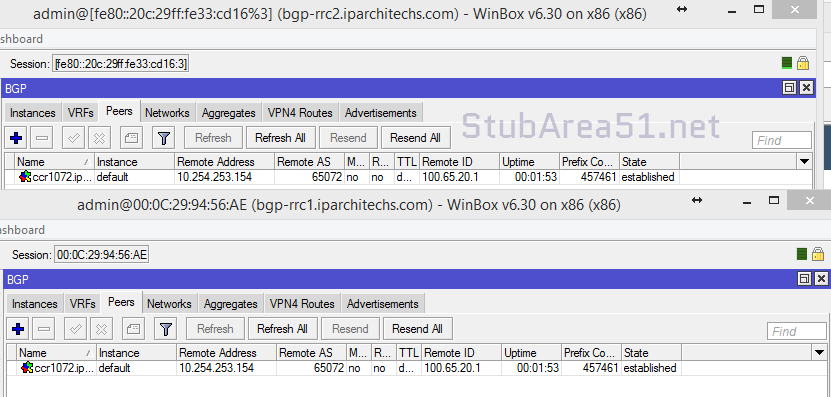
Conclusion
The CCR-1072-1G-8S+ is a fantastic BGP core or edge router. It is able to take in a full table in just over a minute, and is able to take in two tables (which is the most common type of BGP peering deployment we see) in just over 3 minutes, which puts on equal or better footing with a Cisco ASR 1001/1002 at a fraction of the cost.
We see the CCR-1072-1G-8S+ as an extremely strong candidate to use as an Internet BGP edge or core router. A pair of the 1072 routers would also make great WAN aggregation routers for an enterprise data center. Considering most large enterprises don’t go much beyond 10,000 to 15,000 BGP routes in their private MPLS routing tables, the CCR1072 would be able to converge almost immediately and provide stable and scalable throughput to the core.
The next phase of testing we will move into involves throughput testing using iperf on the 1072 with 20 gbps, 40 Gbps and 80 Gbps load tests – we will use BGP/OSPF and MPLS/VPLS configurations to look at performance differences for different types of networks.
CCR-1072-1G-8S+ available soon @
![]()
http://www.roc-noc.com/mikrotik/routerboard/CCR1072-1G-8Splus.html
Stay Tuned!
Coming next – MikroTik CCR1072-1G-8S+ Review (Part 3 ) 20 Gpbs, 40Gbps and 80 Gbps routing performance testing over BGP/OSPF/MPLS.
]]>It has been a busy week and we have been working hard on CCR1072 testing. The full review for BGP Performance is still a few days away, but here is a sneak preview of some of the testing in the stubarea51 Lab.
We put just under 1.7 Million routes across 4 BGP peers into the CCR1072-1G-8S+ and it was fully converged in 2 Minutes and 42 seconds.
Here is a screen shot of the CCR1072-1G-8S+ after converging with 4 full feeds.
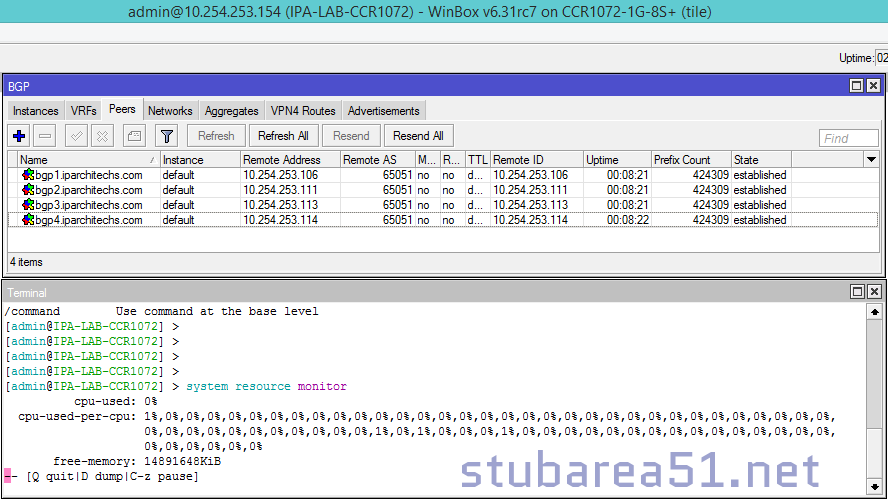
Came across several interesting articles that claim there is a change in the way Dyre aka Upatre malware is spreading. Dyre seems to be getting a lot of press as it is used in browser hijacks to compromise online banking credentials and other sensitive private data. However, most recently – instead of infecting hosts, it appears to be compromising routers as well. Blogger krebsonsecurity.com writes:
Recently, researchers at the Fujitsu Security Operations Center in Warrington, UK began tracking Upatre being served from hundreds of compromised home routers — particularly routers powered by MikroTik and Ubiquiti’s AirOS.
As I first started researching this, I was wondering how they determined the router itself is compromised and not a host that sits on a NAT behind the router. Certainly different devices leave telltale signs visible in an IP packet capture that help point towards the true origin of a packet, so it’s possible that something was discovered in that way. It’s also possible the router isn’t being compromised via the Internet, but rather on the LAN side as it would be much easier for malware to scan the private subnet it sits on and attempt to use well known default credentials to login and take control of a router. While concerning, this LAN attack vector theory relies on the user not properly securing the router and doesn’t indicate a vulnerability in the operating system of either router.
However…I then came across this thread at the Ubiquity forums:
Apparently the attackers are taking advantage of routers that are in fact open and have storage that can be utilized so that it can serve as a distribution point for the malware and also as a C&C point to initiate attacks. In the thread the vulnerable code version that is mentioned is firmware version XW.v5.5.6. It’s not exactly clear what makes this vulnerable, but from reading the forum it seems likely that the firewall may not be enabled by default and with the credentials unchanged, it becomes a target for Dyre. Somebody with more experience in Ubiquity may be able to comment further as I don’t spend enough time with Ubiquity to know for sure across the various code versions.
Example of Dyre using an ubiquity router to initiate attacks…the ./win9 processes are Dyre
Mem: 58492K used, 3632K free, 0K shrd, 764K buff, 6588K cached CPU: 0% usr 2% sys 0% nice 92% idle 0% io 0% irq 4% softirq Load average: 0.03 0.06 0.01 PID PPID USER STAT VSZ %MEM %CPU COMMAND 15472 15355 ubnt R 1992 3% 1% top 2746 2724 ubnt S 25400 41% 0% ./win9 2742 2724 ubnt S 25400 41% 0% ./win9 2739 2724 ubnt S 25400 41% 0% ./win9 2744 2724 ubnt S 25400 41% 0% ./win9 2745 2724 ubnt S 25400 41% 0% ./win9 2738 2724 ubnt S 25400 41% 0% ./win9 2743 2724 ubnt S 25400 41% 0% ./win9 2737 2724 ubnt S 25400 41% 0% ./win9 3128 2919 ubnt S 94836 152% 0% ./i 3112 2919 ubnt S 94836 152% 0% ./i 3103 2919 ubnt S 94836 152% 0% ./i 3106 2919 ubnt S 94836 152% 0% ./i 3102 2919 ubnt S 94836 152% 0% ./i 3087 2919 ubnt S 94836 152% 0% ./i 3129 2919 ubnt S 94836 152% 0% ./i 3137 2919 ubnt S 94836 152% 0% ./i 3104 2919 ubnt S 94836 152% 0% ./i 3113 2919 ubnt S 94836 152% 0% ./i 3135 2919 ubnt S 94836 152% 0% ./i
MikroTik’s response
There is a thread on this at the MIkroTik forums and MikroTik’s official response below is that this is mostly hype and there isn’t a major threat. Which seems to be true if your router is properly secured with a firewall and you change the default credentials. MikroTik routers definitely come with the firewall enabled to protect the less tech-savvy or forgetful users.
http://forum.mikrotik.com/viewtopic.php?t=98127
Conclusion
Neither vendor seems to have a vulnerability that exposes serious code flaws. The answer to this is an oldie but a goodie – be sure to properly set the firewall and use complex credentials on Internet facing routers.
References:
http://krebsonsecurity.com/2015/06/crooks-use-hacked-routers-to-aid-cyberheists/#more-31364
]]>07/25/2015 – Thanks to Normunds @ MikroTik for sending over photos of the production CCR-1072-1G-8S+ which have now been included in the slideshow
[metaslider id=52]
CCR-1072-1G-8S+ available soon @
![]()
http://www.roc-noc.com/mikrotik/routerboard/CCR1072-1G-8Splus.html
UPDATE 7/10/2015 – MikroTik officially lists the CCR1072
http://routerboard.com/CCR1072-1G-8Splus
NOTE: The pictures in this review are of a pre-production CCR1072. The CCR1072 that is shipping has some minor differences on the mainboard and the case. MikroTik is sending updated pictures and we will post those as soon as they come in!
StubArea51.net prepares for CCR1072 performance testing in the Flowood, MS lab
Well, the long wait is finally over. According to Tom over at www.roc-noc.com, the CCR1072 will start shipping in the next 2 weeks and we will be adding it to our development lab in Flowood, MS. We were fortunate enough to get a significant amount of time with the new flagship router down in Miami at the 2015 USA MUM thanks to MT. The arrival of the CCR1072 and 80 Gbps of throughput opens up new doors for MikroTik. The CCR1072 positions MikroTik to break into larger markets and enables competition against industry players like Cisco and Juniper.
This review will be divided into three separate posts (this is Part 1):
- Hardware/Specs
- Throughput testing/performance
- BGP peer load testing.
The first section will focus on the design, hardware specifications and use cases. We will have a CCR1072 in the Stub Area 51 lab very shortly and will be connecting it to our 10 Gbps capable ESXi servers to provide TCP/UDP performance metrics on IPv4 and IPv6. We will also be testing the BGP Peering capability of the CCR1072 by connecting it to our service provider lab and sending multiple full feeds simultaneously to see how it handles the load.
Raw Specs and product description
Let’s take a look at the numbers and product description from MikroTik:
CCR1072-1G-8S+ is an industrial grade super fast router with cutting edge 72 core CPU. If you need many millions of packets per second – Cloud Core Router is your best choice.
- 72 core networking CPU, 1 GHz clock per core
- 16GB ECC RAM
- State of the art TILE GX architecture
- 8x SFP+ ports for 10 Gigabit connectivity
- Ports directly connected to CPU
- Up to 80 Gbps throughput
- Over 100 million pps packet throughput
- 1U rackmount case
- Color touchscreen LCD display
- Two hot-swap power supplies for redundancy
- MicroSD and 2x USB
- Two M.2 slots accept 800mm Key-M x4 PCIe 2.0 modules
Under the hood
With the air channel installed for the quad fan assembly

With the air channel removed and the looking at the CPU heat sink

Power redundancy
One trend that I hope MikroTik continues across the rack mount product line is the option of dual power supplies like on the CCR1009. This has been a long awaited feature on MikroTik routers and it helps to position MikroTik into segments it has struggled to gain a foothold on like enterprise and data center networking.


72 Cores for 80Gbps+ worth of Interwebs!
A look inside the heart of the beast at the 72 Core Tilera gx8072 processor.

Mikrotik’s published speed numbers for the CCR1072 are 80 Gbps, but if you read the Tilera specs, it is capable of 100 Gbps of throughput. The 80 Gbps rating appears to come from the 8 x 10 Gig interfaces connected to the mPIPE. It would be interesting to see if any more 10 gig interfaces could be added via the PCIe slots.
Source: http://www.tilera.com/products/?ezchip=585&spage=618

Use Cases
- Service Provider – A number of ideas come to mind for ISPs – This could be used in the core / distribution with BGP/OSPF/MPLS, although it may not be the most efficient router to use to terminate public BGP until the router can process the tables more quickly. This would also make a great PE for a larger MPLS network that needs more resources on the PE. We will be testing the CCR1072 with multiple full feeds to see how well it handles them.
- Data Center – This could easily be the Layer 3 core of even a medium size data center and certainly those renting a partial rack of COLO space. InterVLAN routing at 80 Gbps easily exceeds the needs of all but the big data operators. These could also be used for throughput to IP based storage like NFS or iSCSI. There is a trend in Data Center design towards moving dynamic routing down to the end host and the 1072 could be positioned as a TOR (Top of Rack) or EOR (End of Row) L3 routing point.
- High throughput L4-L7 Firewall – When used as a firewall deployed at Layer 2 or 3, this router can move a large amount of data through its stateful firewall. Considering the Cisco 5585x starts at 20 gig of throughput and is typically approaching $100,000 to deploy, this could be a game changer in the firewall world at just under $3K per box.
- High Performance IPv4 / IPv6 Proxy / Web Cache – The SD slot opens up some great possibilities to build a high performance web proxy with caching. Throw in some Layer7 rules and you have a very economical IPv4 / IPv6 dual stack capable proxy capable of pushing traffic way beyond the capacity of most Internet pipes.
- Enterprise – When coupled with the right 10 gig switch, the CCR1072 is well suited to run an Enterprise campus and handle converged Data, Voice and Video. The 1072 is ideal for a core or distribution layer in the Enterprise.
Design Example – Data Center CCR1072 implementation
This is a design adapted from an initial Data Center buildout we labbed and presented at the US 2014 MUM on achieving HA and high throughput with a CCR 1036-8G-2S+ as the Layer 3 core in a Data Center. We have taken and adapted many of the design principles of that network and updated the design with the CCR1072.
See presentation slide here in PDF format: Mikrotik-Data-Center-MUM-2014_KevinMyers-4-by-3
Video is below:
The original design was built using CCR1036-8G-2S+ and used 20 Gig LACP channels to achieve 40 Gbps of aggregate throughput using ECMP with OSPF/BGP. Now that the CCR1072 has been released, we can increase the aggregate throughput to 160 Gbps between two routers and 320Gbps using four routers.
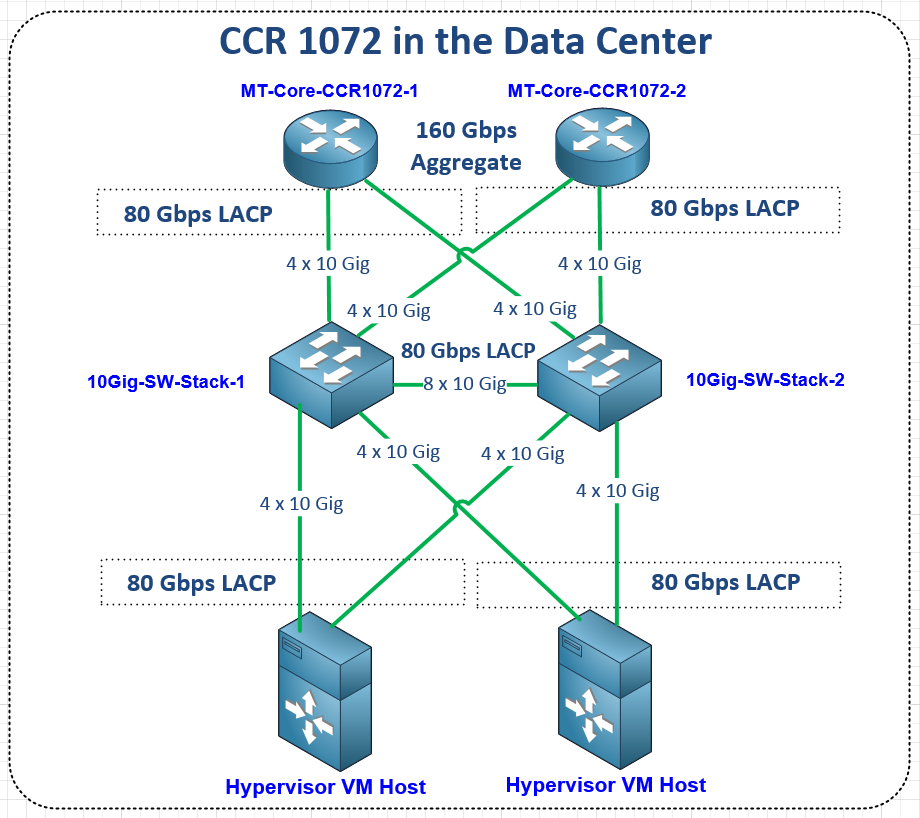
Coming next – MikroTik CCR1072-1G-8S+ Review (Part 2 ) BGP Performance testing using multiple peers with full BGP tables.
]]>