[adrotate banner=”5″]
[metaslider id=282]
Getting to 10 Gbps using EoIP
The EoIP tunnel protocol is one of the more popular features we see deployed in MikroTik routers. It is useful anywhere a Layer 2 extension over a Layer 3 network is needed and can be done with very little effort / complexity. One of the questions that seems to come up on the forums frequently is how much traffic can an EoIP tunnel handle which is typically followed by questions about performance with IPSEC turned on. Answers given by MikroTik and others on forums.mikrotik.com typically fall into the 1 to 3 Gbps range with some hints that more is possible. We searched to see if anyone had done 10 Gbps over EoIP with or without IPSEC and came up empty handed. That prompted us to dive into the StubArea51 lab and set up a test network so we could get some hard data and definitive answers.
The EoIP protocol and recent enhancements
Ethernet over IP or EoIP is a protocol that started as an IETF draft somewhere around 2002 and MikroTik developed a proprietary implementation of it that has been in RouterOS for quite a while. Similar to EoMPLS or Cisco’s OTV, it faciltates the encapsulation of Layer 2 traffic over a Layer 3 network such as the Internet or even a private L3 WAN like an MPLS cloud. If you follow MikroTik and RouterOS updates closely, you might have come across a new feature that was released in version 6.30 of RouterOS.
What's new in 6.30 (2015-Jul-08 09:07): *) tunnels - eoip, eoipv6, gre,gre6, ipip, ipipv6, 6to4 tunnels have new property - ipsec-secret - for easy setup of ipsec encryption and authentication;
This is a much anticipated feature as it simplifies the deployment of secure tunnels immensely. It makes things so easy, that it really gives MikroTik a significant competitive advantage against Cisco and other vendors that have tunneling features in their routers and firewalls. When you look at the complexity involved in deploying a tunnel over ipsec in a Cisco router vs. a MikroTik router, there is a clear advantage to using MikroTik for tunneling. I originally looked into this feature for EoIP but it is available many other tunnel types like gre, ipip and 6to4.
When you look at the complexity involved in deploying a tunnel over ipsec in a Cisco router vs. a MikroTik router, there is a clear advantage to using MikroTik for tunneling.
Here is one of the simpler implementations of L2TPv3 over IPSEC in a Cisco router which still has a fair amount of complexity surrounding it.
http://www.cisco.com/c/en/us/support/docs/security/flexvpn/116207-configure-l2tpv3-00.html
VS.
http://wiki.mikrotik.com/wiki/Manual:Interface/EoIP
The MikroTik config has 3 required config items for EoIP on each router vs double the steps with Cisco and the added complexity of troubleshooting IPSEC if you get a line of config wrong.
The test network
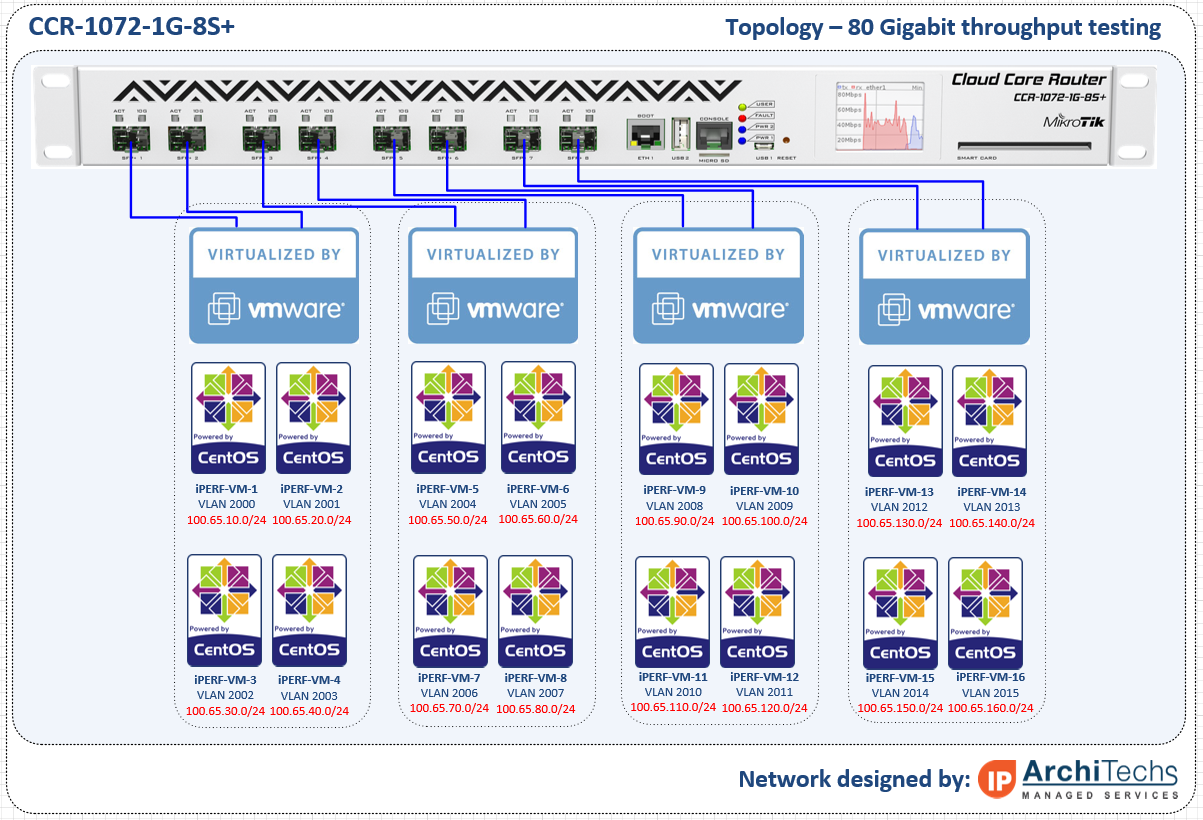
In order to test 10 Gbps speed over EoIP, we needed a 10 Gbps capable test network and decided to use two CCR-10368G-2S+ as our endpoints and a CCR1072-1G-8S+ as the core WAN. We used an HP DL360-G6 with ESXi as the hypervisor to launch our test VMs for TCP throughput. We typically use VMs instead of MikroTik’s built in bandwidth tester because they can generate more traffic and have more granularity to stage specific test conditions (TCP window, RX/TX buffer, etc).
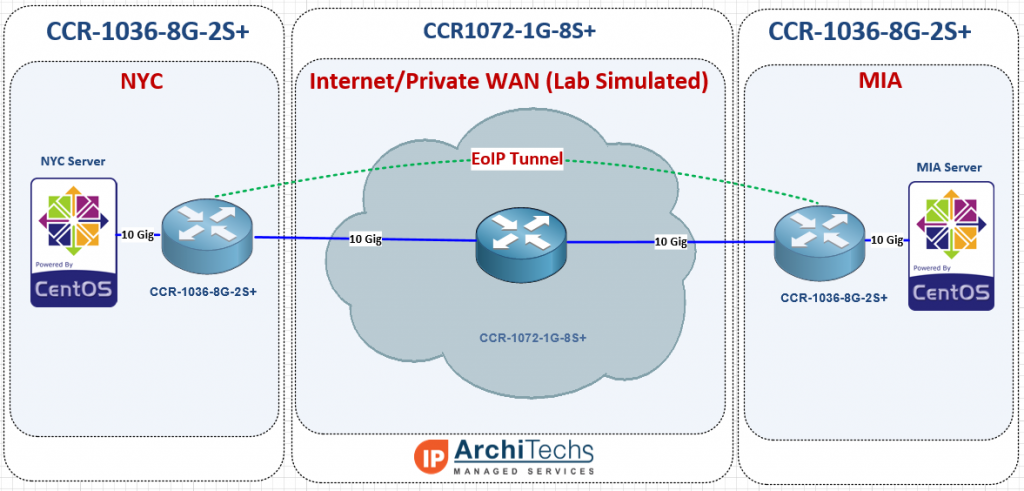
Concept of testing
Most often, EoIP is implemented over the Internet and so using 9000 as a test MTU might be surprising to some users and possibly irrelevant, but when using a private WAN, quite often a Layer 3 solution is much less expensive than Layer 2 handoffs (especially at 10 Gbps) and 9000 bytes is almost always supported on that kind of transport, so L2 over private L3 definitely has a place as a possible application for EoIP with 9000 byte frames.
9000 byte MTU unencrypted
9000 byte MTU encrypted with IPSEC
1500 byte MTU unencrypted
1500 byte MTU encrypted with IPSEC
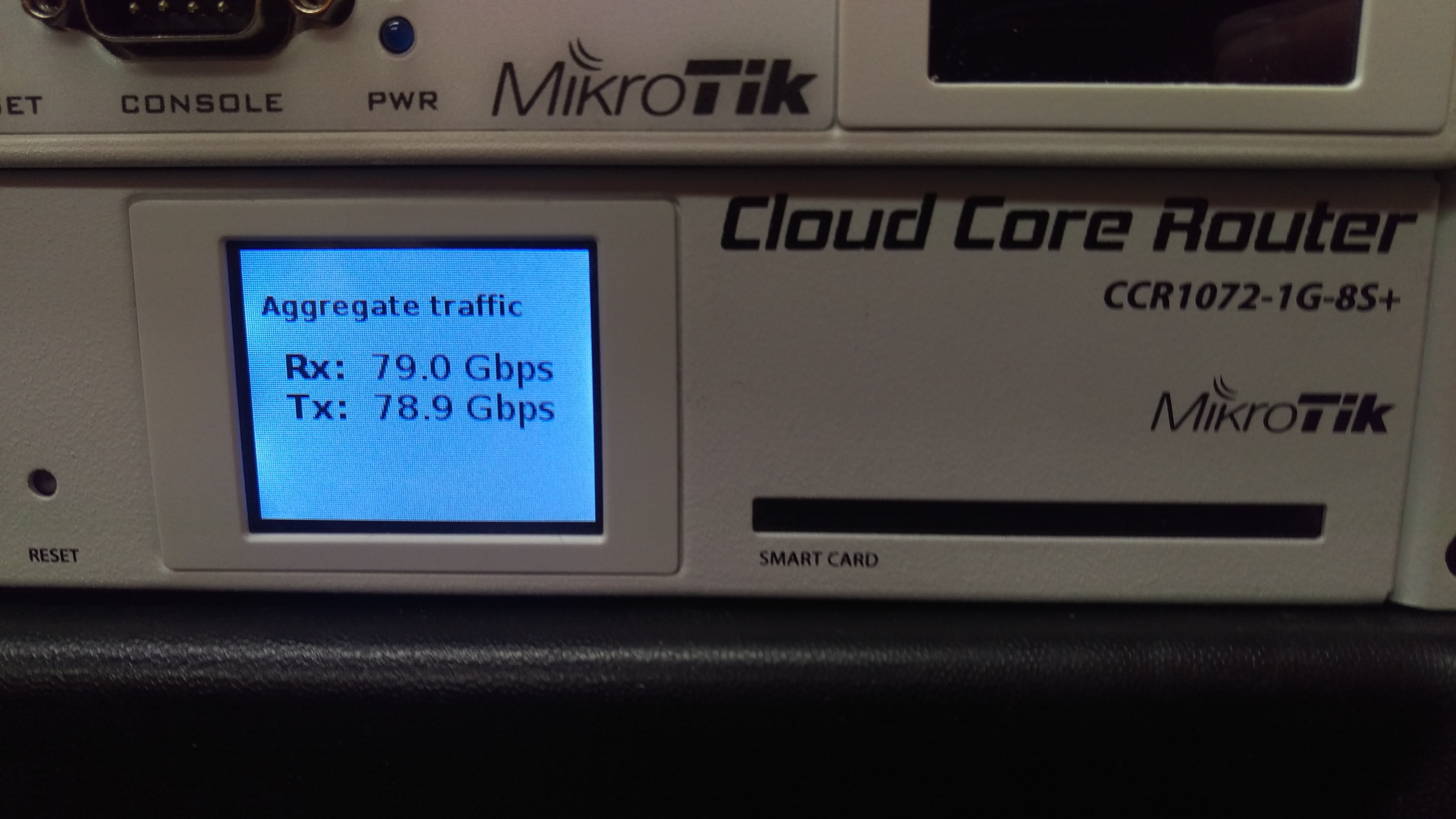
And the results are in!!! 10 Gbps is possible over EoIP
10 Gbps over EoIP (Unencrypted with 9000 byte MTU)
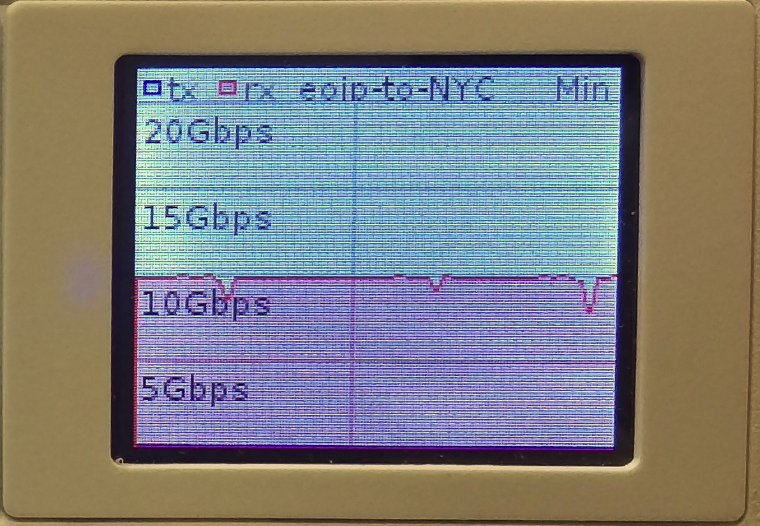
Video of 10 Gbps over EoIP (Unencrypted with 9000 byte MTU)
7.5 Gbps over EoIP (IPSEC encrypted with 9000 byte MTU)
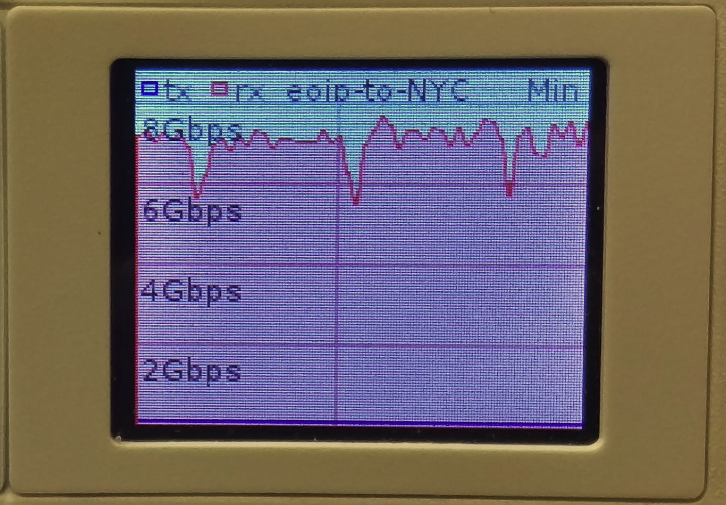
Video of 7.5 Gbps over EoIP (IPSEC encrypted with 9000 byte MTU)
6.4 Gbps over EoIP (Unencrypted with 1500 byte MTU)
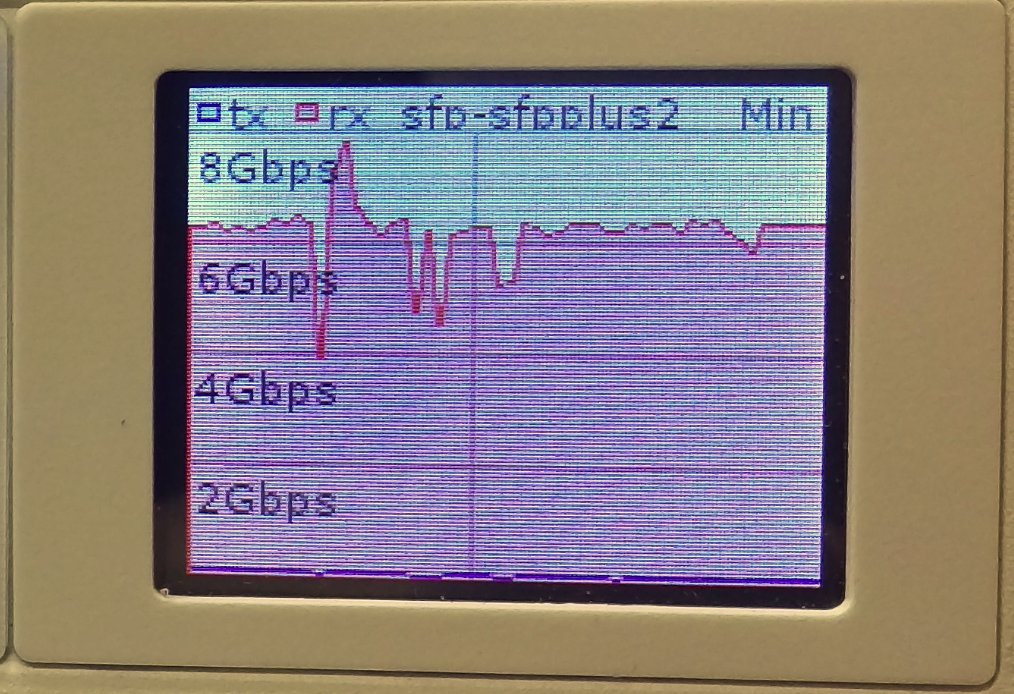
Video of 6.4 Gbps over EoIP (Unencrypted with 1500 byte MTU)
1.7 Gbps over EoIP (IPSEC encrypted with 1500 byte MTU)
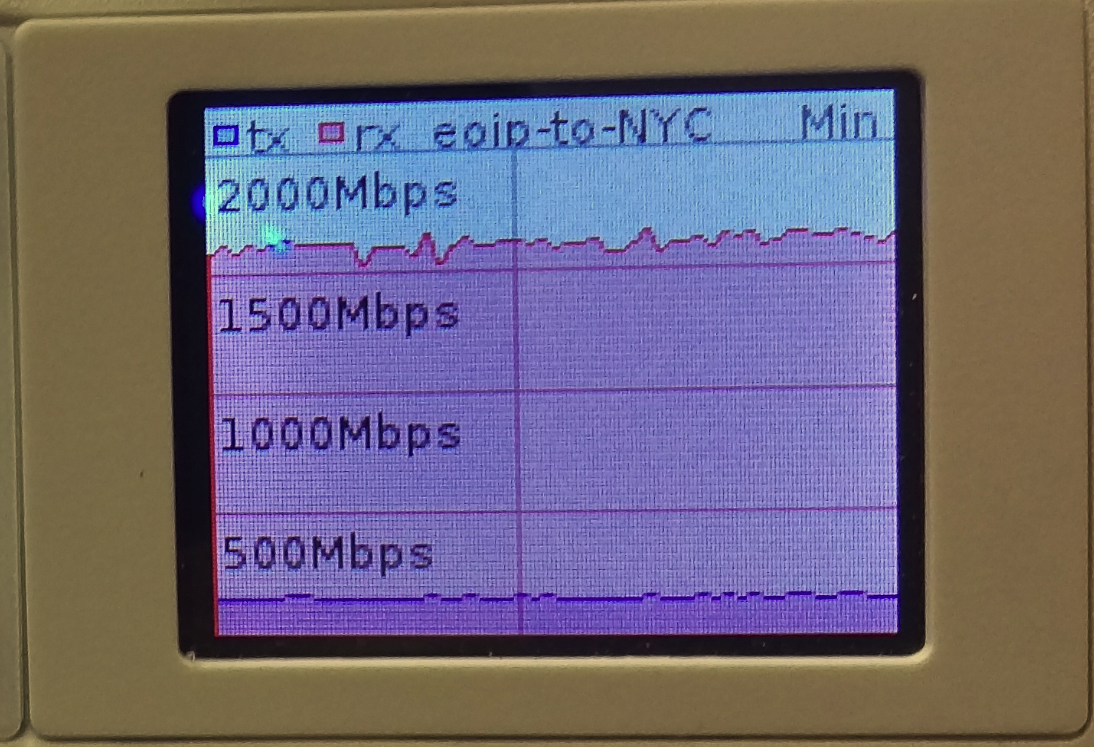
Video of 1.7 Gbps over EoIP (IPSEC encrypted with 1500 byte MTU)
Video will be posted soon.
Use cases and conclusions
The CCR1036 certainly had no issues getting to 10 Gbps with the right MTU and test hardware, but we were suprised that the IPSEC thoughput was so high. Considering a pair of CCR1036-8G-2S+ routers are just a little over $2000.00 USD, 7.5 Gigabits of encrypted throughput with IPSEC is incredible. Even over a 1500 byte MTU, the 1.7 Gbps we were able to hit is amazing considering it would probably take at least 20k to 30k USD to reach that kind of encrypted throughput with equipment from a mainstream network vendor like Cisco or Juniper.
Use cases for this are probably too numerous to mention but we came up with a few
- Extending an ISP or joining two or more ISPs in different regions
- High volume PPPoE backhaul to a BRAS
- Data Center Interconnect (DCI) at Layer 2
- Enterprise HQ and Branch connectivity or backup
- Layer 2 network extension for network migration or merger.
Please feel free to leave comments with questions about the testing or use cases we might not have thought of…we love getting feedback 🙂